
검색어 자동 완성(Autocomplete, Typeahead, Search-as-you-type, Incremental Search)은 입력 중인 글자에 맞는 검색어가 자동으로 완성하여 표시되는 기능이다.
검색어 자동완성은 많은 제품에 중요하게 사용되는 기능으로 이번 장에서는 가장 많이 이용된 검색어 K개를 자동완성하여 출력하는 시스템을 설계한다.
1단계: 문제 이해 및 설계 범위 확정
- Q. 사용자의 입력 단어가 자동완성 될 검색어의 어느 부분인가?(첫, 뒷)
- A. 첫 부분으로 한정
- Q. 몇 개의 자동완성 검색어가 표시?
- A. 5개
- Q. 자동완성 검색어 5개를 고르는 기준은?
- A. 질의 빈도에 따라 정해지는 인기 순위
- Q. 맞춤법 검사 기능 제공?
- A. N
- Q. 질의는 영어?
- A. Y
- Q. 대문자나 특수문자도 처리?
- A. 모든 질의는 영어 소문자만
- Q. 얼마나 많은 사용자를 지원?
- A. DAU 천만
요구사항
위 질의응답을 통해 정리한 요구사항은 아래와 같다.
- 빠른 응답 속도
- 사용자가 검색어를 입력합에 따라 자동완성 검색어도 충분히 빨리 표시되어야한다.
- 페이스북은 응답속도 100ms 이내를 기준으로 한다.
- 자동 완성은 실시간으로 빠르게 처리되는 특성으로 느리면 사용이 매우 불편해진다.
- 연관성
- 자동완성 결과는 사용자가 입력한 단어와 연관된 것 이어야 한다.
- 정렬
- 계산 결과는 인기도(Populatiry) 등의 순위 모델(Ranking Model)에 의해 정렬되어 있어야 한다.
- 규모 확장성
- 많은 트래픽을 감당할 수 있도록 확장 가능해야한다.
- 고가용성
- 시스템의 일부에 장애, 지연, 네트워크 문제가 생겨도 계속 사용 가능해야한다.
개략적 규모 추정
- DAU는 천만 명으로 가정
- 사용자는 평균적으로 매일 10건의 검색을 수행한다고 가정
- 질의 마다 평균적으로 20바이트 데이터를 입력한다고 가정
- ASCII 사용한다고 가정(
1문자 = 1바이트) - 질의문은 평균적으로 4개 단어, 각 단어는 다섯 글자로 구성된다고 가정
- 질의당 평균
4 * 5 = 20바이트
- ASCII 사용한다고 가정(
- 검색창에 글자를 입력할 때마다 클라이언트는 검색어 자동완성 백엔드에 요청을 보낸다.
- 평균적으로 1회 검색당 20건의 요청이 백엔드로 전달된다.
- “dinner” 입력 예시
search?q=dsearch?q=disearch?q=dinsearch?q=dinnsearch?q=dinnesearch?q=dinner
- 대략 초당 24,000건 질의(QPS)
10,000,000 사용자 * (10 질의/일) * 20자 / 24시간 / 3,600초
최대 QPS = QPS * 2 = 대략 48,000- 질의 중 20%는 신규 검색어라 가정.
10,000,000 사용자 * (10 질의/일 * 20자 * 20%) = 일 0.4GB- 0.4GB의 신규 데이터가 시스템에 추가
2단계 개략적 설계안 제시 및 동의 구하기
검색어 자동완성 시스템은 개략적으로 두 부분으로 나뉜다.
- 데이터 수집 서비스(Data gathering service)
- 사용자가 입력한 질의를 실시간로 수집하는 시스템
- 데이터가 많은 시스템에 실시간으로 수집하는건 바람직하지 않기 때문에 진행하며 현실적인 안으로 교체한다.
- 질의 서비스(Query Service)
- 주어진 질의에 다섯 개의 인기 검색어를 정렬해 내놓는 서비스
데이터 수집 서비스
데이터 수집 서비스의 동작을 간단한 예제로 살펴본다.
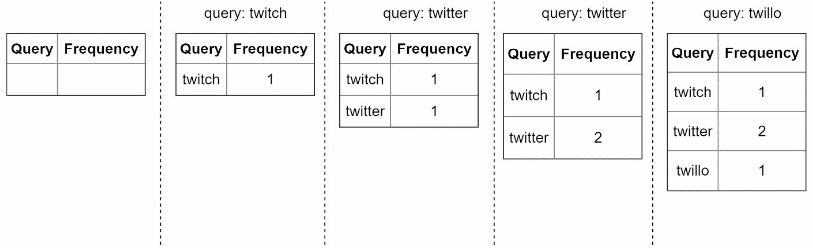
질의문과 사용 빈도를 저장하는 빈도 테이블(frequency table)이 있다고 가정하면, 처음 이 테이블은 비어있지만, 사용자가 검색하면 그 상태가 바뀌어 나가게 된다.
질의 서비스
erDiagram
Frequency {
query varchar
freuqency bigint
}
| query | freuqency |
|---|---|
| 35 | |
| twitch | 29 |
| twilight | 25 |
| twin peak | 21 |
| twitch prime | 18 |
| twitter search | 14 |
| twillo | 10 |
| twin peak sf | 8 |
위와 같은 상태에서 사용자가 tw를 검색창에 입력하면 “top 5” 검색어가 표시되어야 한다.
- twitch
- twilight
- twin peak
- twitch prime
| |
이러한 방법은 데이터 양이 적을 때는 나쁘지 않지만, 데이터가 아주 많아지면 데이터베이스가 병목이 될 수 있다.
3단계: 상세 설계
개략적 설계안은 출발점으로 나쁘진 않지만 최적화가 이루어지지 않아 장기적으로 발전이 필요한 구조였다.
이번 절에서는 컴포넌트를 몇 개 골라 보다 상세히 설계하고 다음 순서로 최적화 방안을 논의한다.
- 트라이(Trie) 자료구조
- 데이터 수집 서비스
- 질의 서비스
- 규모 확장이 가능한 저장소
- 트라이 연산
트라이 자료구조
개략적 설계안에서는 관계형 데이터베이스를 저장소로 사용했었지만, 관계형 데이터베이스를 이용해 가장 인기 있었던 다섯 개 질의문을 골라내는 방법은 비교적 효율적이지 않다.
이 문제는 트라이(Trie, 접두어 트리, Prefix tree)를 사용해 성능을 끌어올릴 수 있다.
트라이는 문자열들을 간략하게 저장할 수 있는 자료구조이다.
- 트리 형태의 자료 구조다.
- 루트 노드는 빈 문자열을 나타낸다.
- 각 노드는 글자 하나를 저장하며, 이 설계에서는 26개의 자식 노드를 가질 수 있다.
- 자식 노드는 해당 글자 다음에 등장할 수 있는 모든 글자의 개수
- 각 트리 노드는 하나의 단어, 또는 접두어 문자열을 나타낸다.
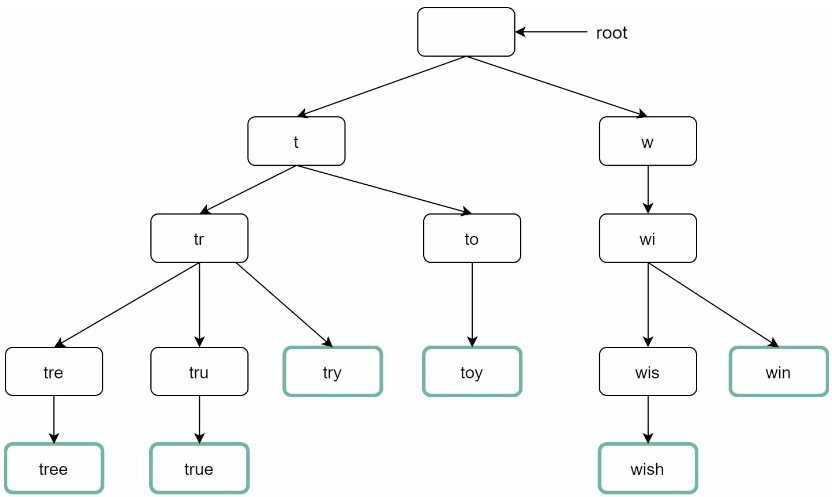
기본 트라이 자료구조는 노드에 문자들을 저장한다.
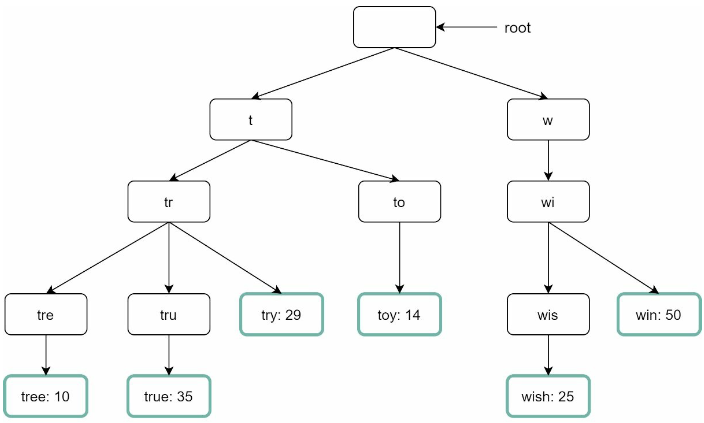
이를 이용 빈도에 따라 정렬된 결과를 위해 노드에 빈도 정보까지 함께 저장해야한다.
| query | frequency |
|---|---|
| tree | 10 |
| try | 29 |
| true | 35 |
| toy | 14 |
| wish | 25 |
| win | 50 |
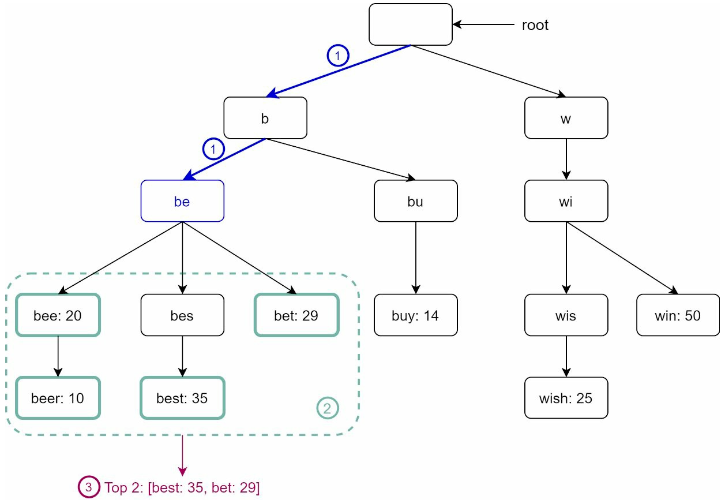
p: 접두어 길이n: 트라이 안에 있는 노드 개수c: 주어진 노드의 자식 노드 개수
가장 많이 사용된 질의어 k개는 다음과 같이 찾을 수 있다.
- 해당 접두어를 표현하는 노드를 찾는다.
O(p) - 해당 노드부터 시작하는 하위 트리를 탐색하여 모든 유효 노드를 찾는다.
O(c)- 유효한 검색 문자열을 구성하는 노드가 유효 노드
- 유효 노드들을 정렬하여 가장 인기 있는 검색어 k개를 찾는다.
O(clogc)
이 알고리즘의 시간 복잡도는 위의 각 단계에 소요된 시간의 합이다.
O(p) + O(c) + O(clogc)
직관적이지만 최악의 경우 k개 결과를 얻으려고 전체 트라이를 다 검색해야 하는 일이 생길 수 있다.
이러한 문제를 해결할 방법으로 두 가지 정도를 꼽을 수 있다.
- 접두어의 최대 길이 제한
- 각 노드에 인기 검색어 캐시
접두어 최대 길이 제한
사용자가 검색창에 긴 검색어를 입력하는 일은 거의 없다는 것을 이용한 방식으로, p값을 작은 정숫값으로 가정한다.
- 접두어 노드를 찾는 단계의 시간 복잡도가
O(p)에서O(작은 상수값) = O(1)로 바뀐다.
노드에서 인기 검색어 캐시
각 노드에 k개의 인기 검색어를 저장해 두면 전체 트라이를 검색하는 일을 방지할 수 있다.
- 5 ~ 10개 정도의 자동완성 제안을 표시하면 충분하므로, k는 충분히 작은 값이다.
이러한 방법은 검색어를 질의하는 시간 복잡도를 매우 낮출 수 있으나, 각 노드에 질의어를 저장할 공간이 많이 필요하게된다.
하지만 빠른 응답속도의 우선순위가 매우 높은 경우 저장공간을 희생할 만한 가치는 있다.
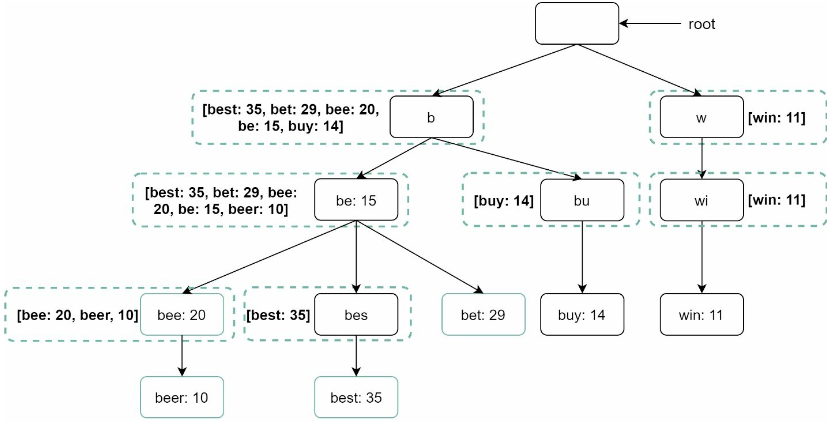
접두어 최대 길이 제한과 인기 검색어 캐시를 추가하면 아래와 같이 최적화 할 수 있다.
- 접두어 노드를 찾는 시간 복잡도가
O(1)로 바뀐다. - 최고 인기 검색어 5개를 찾는 질의의 시간 복잡도도
O(1)로 바뀐다.
각 단계의 시간 복잡도가 O(1)로 처리되므로, 최고 인기 검색어 k개를 찾는 전체 알고리즘의 복잡도도 O(1)이다.
데이터 수집 서비스
사용자가 검색창에 타이핑을 할 때마다 실시간으로 데이터를 수정하는 방식은 아래와 같은 문제점이 있다.
- 매일 수천만 건의 질의가 입력될 텐데, 그 때마다 트라이를 갱신하면 질의 서비스는 심각하게 느려진다.
- 트라이가 만들어지고 나면 인기 검색어는 그다지 자주 바뀌지 않을 것이다.
- 트라이는 자주 갱신할 필요가 없다.
이를 위한 규모 확장이 쉬운 데이터 수집 서비스를 만들려면 데이터가 어디서 오고 어떻게 이용되는지를 살펴야 한다.
- 트위터 같은 실시간 애플리케이션
- 제안되는 검색어를 항상 신선하게 유지할 필요가 있다.
- 구글 검색 같은 애플리케이션
- 그렇게 자주 바꿔줄 이유는 없다.
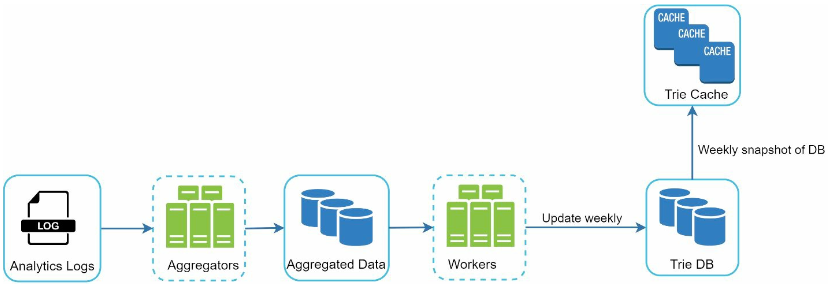
트라이를 만드는 데 쓰는 데이터는 보통 분석 서비스(Analytics)나 로깅 서비스(Logging service)를 이용하므로, 실시간으로 반영하지 않더라도 기본 구조는 바뀌지 않는다.
데이터 분석 서비스 로그
검색창에 입력된 질의에 관한 원본 데이터가 보관된다.
새로운 데이터가 추가될 뿐 수정은 이루어지지 않으며, 로그 데이터에는 인덱스를 걸지 않는다.
| query | time |
|---|---|
| tree | 2019-10-01 22:01:01 |
| … | … |
로그 취합 서버
로그는 보통 그 양이 엄청나고 데이터 형식도 제각각인 경우가 많다.
따라서 이 데이터를 잘 취합하여 우리 시스템이 쉽게 소비할 수 있도록 해야한다.
데이터 취합 방식은 자동완성 서비스의 제공 방식에 따라 달라질 수 있다.
- 실시간 애플리케이션
- 데이터 취합 주기를 짧게 가져간다.
- 대부분의 경우
- 일주일에 한 번 정도 로그를 취합해도 충분
취합된 데이터
| query | time | frequency |
|---|---|---|
| tree | 2019-10-01 | 12000 |
| … | … | … |
작업 서버
주기적으로 비동기적 작업을 실행하는 서버 집합으로, 트라이 자료구조를 만들고 트라이 데이터베이스에 저장하는 역할을 담당한다.
트라이 캐시
분산 캐시 시스템으로 트라이 데이터를 메모리에 유지하여 읽기 연산 성능을 높이는 역할을 한다.
- 매주 트라이 데이터베이스의 스냅샷을 떠서 갱신한다.
트라이 데이터베이스
지속성 저장소로 트라이 데이터베이스로 사용할 수 있는 선택지로는 다음의 두 가지가 있다.
- 문서 저장소(Document store)
- 새 트라이를 매주 만들 것이므로, 주기적으로 트라이를 직렬화하여 데이터베이스에 저장할 수 있다.
- 몽고디비(MongoDB) 등
- 키-값 저장소
- 트라이는 해시 테이블 형태로 변환 가능하다.
- 트라이에 보관된 모든 접두어를 해시 테이블 키로 변환
- 각 트라이 노드에 보관된 모든 데이터를 해시 테이블 값으로 변환
- 트라이 노드는 하나의
<키, 값>쌍으로 변환된다.
- 트라이는 해시 테이블 형태로 변환 가능하다.
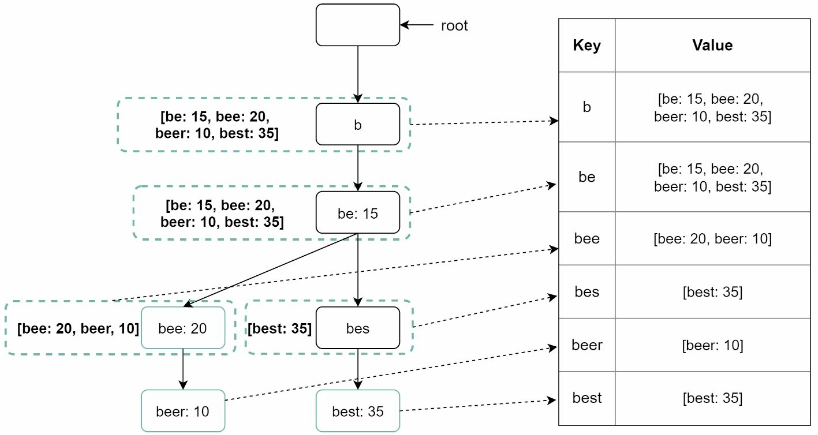
질의 서비스
개략적 설계안에서의 데이터베이스를 활용한 방식에서 개선된 새 설계안이다.
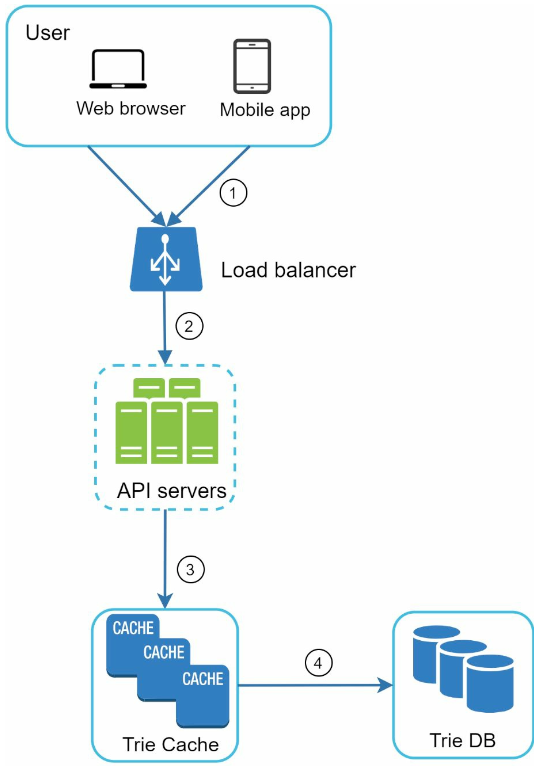
- 검색 질의가 로드밸런서로 전송된다.
- 로드밸런서는 해당 질의를 API 서버로 보낸다.
- 트라이 캐시에서 데이터를 가져와 해당 요청에 대한 자동완성 검색어 제안 응답을 구성한다.
- 데이터가 트라이 캐시에 없는 경우 데이터를 데이터베이스에서 가져와 캐시에 채운다.
- 다음에 같은 접두어에 대한 질의가 올 것을 대비하여 캐시를 갱신
- 캐시 미스는 캐서 서버의 메모리가 부족하거나 캐시 서버에 장애가 있어도 발생 가능
질의 서비스는 번개처럼 빨라야 한다. 이를 위해 다음과 같은 최적화 방안을 생각해 볼 수 있다.
- AJAX
- 비동기로 결과를 받아오므로, 페이지를 새로고침 할 필요가 없다.
- 브라우저 캐싱
- 자동완성 검색어 제안 결과는 짧은 시간에 바뀌지 않으므로, 제안된 검색어들을 브라우저 캐시에 넣어두면 후속 결과는 캐시에서 가져갈 수 있다.
- 구글은 제안된 검색어를 한 시간 동안 캐시해둔다.
cache-control헤더 값의private는 요청을 보낸 사용자의 캐시에만 보관된다는 의미(공용은 불가)max-age=3600한시간동안 유효
- 데이터 샘플링
- 모든 질의 결과를 로깅하도록 하면 CPU 자원과 저장공간을 많이 소진하므로, N개의 요청 가운데 1개만 로깅한다.
트라이 연산
트라이는 검색어 자동완성 시스템의 핵심이다.
트라이 생성
트라이를 갱신하는데는 두 가지 방법이 있다.
- 매주 한 번 갱신
- 새로운 트라이를 만든 후 기존 트라이를 대체
- 각 노드를 개별적으로 갱신
- 성능이 좋지 않다.
- 트라이가 작을경우 고려할 수 있다.
- 트라이 노드는 상위 노드에도 인기 검색어 질의 결과가 보관되므로 갱신시 모든 상위 노드도 갱신해야 한다.
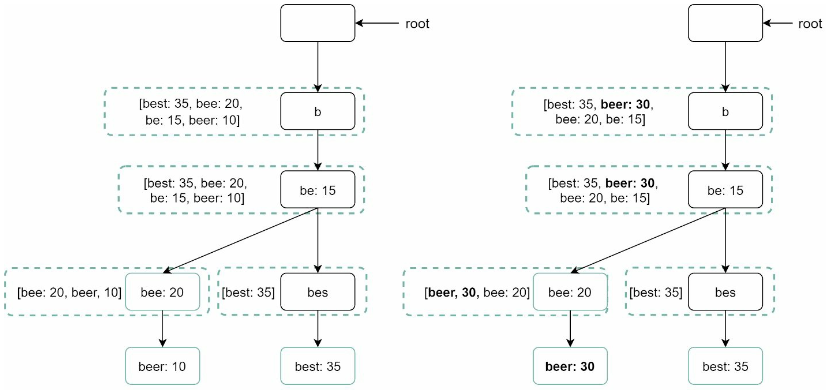
검색어 삭제
부적절한 질의어를 자동완성 결과에서 제거해야할 수 있다.
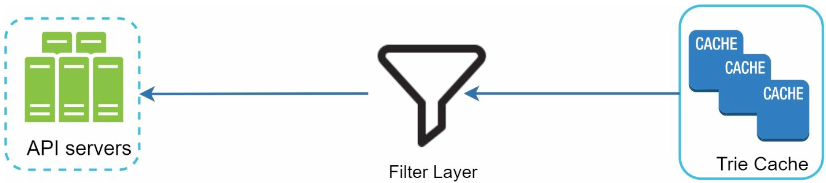
이를 위한 좋은 방법은 트라이 캐시 앞에 필터 계층(filter layer)를 두고 부적절한 질의어가 반환되지 않도록 하는 것이다.
- 필터 규칙에 따라 검색 결과를 자유롭게 변경할 수 있다.
- 데이터베이스에서 해당 검색어를 물리적으로 삭제하는 것은 다음 업데이트 사이클에 비동기적으로 진행한다.
저장소 규모 확장
트라이의 크기가 한 서버에 넣기 힘든 경우에 대응할 수 있도록 규모 확장성 문제를 고려해야한다.
간단하게 첫 글자를 기준으로 샤딩하는 방법을 생각해 볼 수 있다.
- 두 대 서버가 필요하다면
a~m까지 글자로 시작하는 검색어는 1번 서버, 나머지는 2번 서버에 저장 하는 식으로 … - 사용 가능한 서버는 최대 26대(영어 알파벳 개수)로 제한되므로, 그 이상 늘리려면 계층적인 샤딩이 필요하다.
aa~ag,ah~an…
이렇게 단순한 사딩은 단어의 알파벳 빈도수 문제(특정 알파벳으로 시작되는 단어가 몰려있다.)로 인해 데이터를 각 서버에 균등하게 배분하는것이 불가능하다.
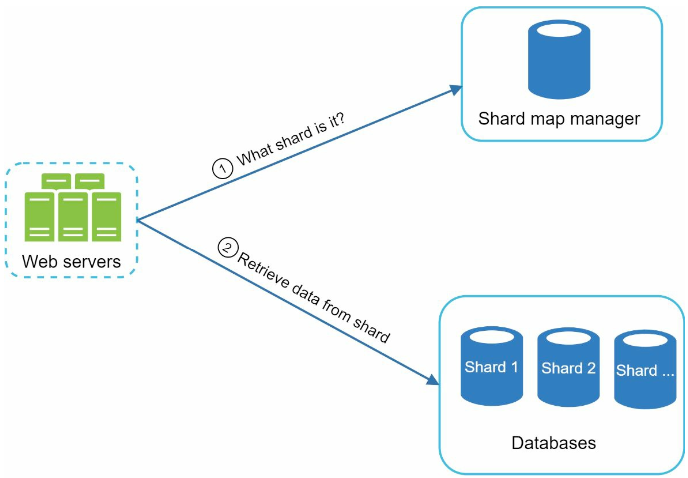
따라서 과거 질의 데이터의 패턴을 분석하여 알바벳 빈도수를 파악하고, 빈도수를 통해 샤딩하는 방식을 고려해야한다.
4단계: 마무리
- 다국어 지원이 가능하도록 하려면?
- 트라이에 유니코드 데이터를 저장한다.
- 국가별로 인기 검색어 순위가 다르다면?
- 국가별로 다른 트라이를 사용하도록 한다.
- 트라이를 CDN에 저장하여 응답속도를 높이는 방식도 고려할 수 있다.
- 실시간으로 변하는 검색어의 추이를 반영하려면?
- 현제 설계는 위와 같은 처리가 적절치 않다.
- 작업 서버가 매주 한 번 씩만 돈다.
- 때 맟춰 서버가 실행되어도, 트라이 구성에 많은 시간이 소요된다.
- 샤딩을 통해 작업 대상 데이터의 양을 줄인다.
- 순위 모델을 바꾸어 최근 검색어에 보다 높은 가중치를 준다.
- 데이터가 스트림 형태로 올 수 있다는 점, 즉 한번에 모든 데이터를 동시에 사용할 수 없을 가능성이 있다는 점을 고려해야한다.
- 데이터가 지속적으로 생성된다는 뜻으로 스트림 프로세싱을 위한 특별한 시스템이 필요하다.
- 아파치 하둡 맵리듀스, 아파치 스파크 스트리밍, 아파치 스톰, 아파치 카프가 등
- 데이터가 지속적으로 생성된다는 뜻으로 스트림 프로세싱을 위한 특별한 시스템이 필요하다.
- 현제 설계는 위와 같은 처리가 적절치 않다.