
이번 장에서는 아마존 S3(Simple Storage Service)와 유사한 객체 저장소 서비스를 설계한다.
S3는 AWS가 제공하는 서비스로 RESTful API 기반 인터페이스로 이용 가능한 객체 저장소다.
객체 저장소에 대해 더 자세히 살펴보기 전, 일반적으로 저장소란 어떤 시스템인지 알아보고, 몇 가지 용어를 정의해본다.
저장소 시스템 101
개략적으로 보면 저장소 시스템에는 3가지 부류가 있다.
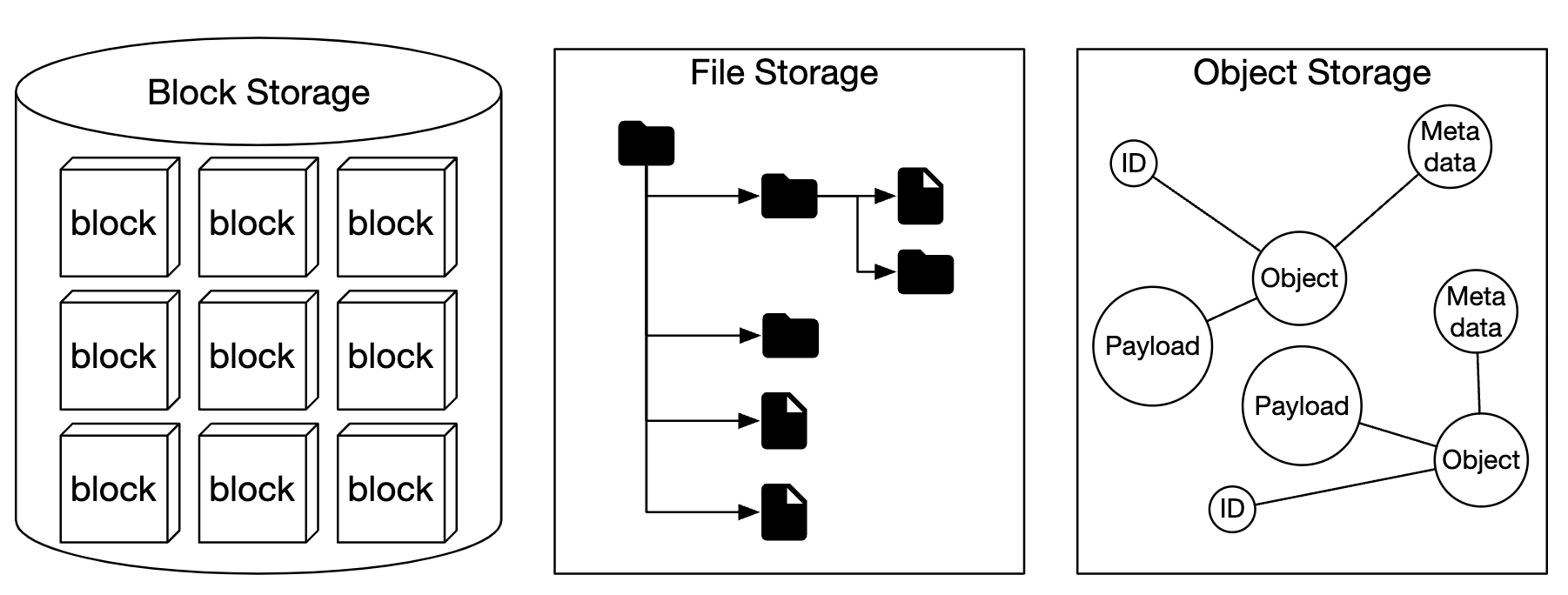
블록 저장소
HDD, SSD 처럼 서버에 물리적으로 연결되는 형태의 드라이브는 블록 저장소에 가장 흔한 형태이다.
블록저장소는 원시 블록(raw block)을 서버에 볼륨 형태로 제공하는 가장 유연하고 융통성 높은 저장소다.
- 서버는 원시 블록을 포맷한 다음 파일 시스템으로 이용하거나 애플리케이션에 블록 제어권을 넘겨 버릴 수도 있다.
- 데이터베이스나 가상 머신 엔진 같은 애플리케이션은 원시 블록을 직접 제어하여 최대한의 성능을 끌어낸다.
서버에 물리적으로 직접 연겨로디는 저장소에 국한되지 않는다.
- 고속 네트워크를 통해 연결될 수도 있다.
- 업계 표준 연결 프로토콜은 FC(Fiber Channel)이나 ISCSI를 통해 연결될 수도 있다.
개념적으로 보면 네트워크를 통해 연결되는 블록 저장소도 원시 블록을 제공한다는 점에서 다르지 않으며, 서버 입장에서 보면 물리적으로 연결된 블록 저장소와 마찬가지로 동작한다.
파일 저장소
파일 저장소는 블록 저장소 위에 구현된다.
- 파일과 디렉터리를 손쉽게 다루는 데 필요한, 더 높은 수준의 추상화를 제공한다.
- 데이터는 계층적으로 구성되는 디렉터리 안에 보관된다.
파일 저장소는 가장 널리 사용되는 범용 저장소 솔루션으로, SMB/CIFS나 NFS와 같은 파일 수준 네트워크 프로토콜을 사용하면 하나의 저장소를 여러 서버에 동시에 붙일 수도 있다.
파일 저장소를 사용하는 서버는 블록을 직접 제어하고, 볼륨을 포맷하는 등의 까다로운 작업을 신경 쓸 필요가 없다.
- 단순하기 때문에 폴더나 파일을 같은 조직 구성원에 공유하는 솔루션으로 사용하기 좋다.
객체 저장소
새로운 형태의 저장소로 데이터 영속성을 높이고 대규모 애플리케이션을 지원하며 비용을 낮추기 위해 의도적으로 성능을 희생한다.
- 실시간으로 갱신할 필요가 없는 상대적으로 차가운(cold) 데이터 보관에 초점을 맞추며, 데이터 아카이브나 백업에 주로 쓰인다.
모든 데이터를 수평적 구조 내에 객체로 보관한다.
- 계층적 디렉터리 구조는 제공하지 않는다.
데이터 접근은 보통 RESTful API를 사용하며, 다른 유형의 저장소에 비해 상대적으로 느리다.
비교
| 블록 저장소 | 파일 저장소 | 객체 저장소 | |
|---|---|---|---|
| 저장된 내용의 변경 가능성 | Y | Y | N(새로운 버전의 객체를 추가하는 것은 가능) |
| 비용 | 고 | 중 ~ 고 | 저 |
| 성능 | 중 ~ 고 혹은 최상 | 중 ~ 고 | 저 ~ 중 |
| 데이터 일관성 | 강력 | 강력 | 강력 |
| 데이터 접근 | SAS/iSCSI/FC | 표준 파일 접근, CIFS/SMB, NFS | RESTful API |
| 규모 확장성 | 중 | 고 | 최상 |
| 적합한 응용 | 가상머신, 데이터베이스 같은 높은 성능이 필요한 애플리케이션 | 범용적 파일 시스템 접근 | 이진 데이터, 구조화되지 않은 데이터 |
용어 정리
객체 저장소의 핵심 개념을 먼저 이해할 필요가 있다.
- 버킷(bucket)
- 객체를 보관하는 논리적 컨테이너
- 버킷 이름은 전역적으로 유일해야 함(globally unique)
- 데이터를 업로드하려면 우선 버킷부터 만들어야 함
- 객체(Object)
- 버킷에 저장하는 개별 데이터
- 데이터(페이로드라고도 함)와 메타데이터를 가짐
- 객체 데이터로는 어떤 것도 가능함
- 메타데이터는 객체를 기술하는 이름-값 쌍
- 버전(version)
- 한 객체의 여러 버전을 같은 버킷 안에 둘 수 있도록 하는 기능
- 버킷마다 별도 설정 가능
- 객체를 복구할 수 있도록 함
- URI(Uniform Resource Identifier)
- 객체 저장소는 버킷과 객체에 접근할 수 있도록 하는 RESTful API를 제공하기 때문에 각 객체는 해당 API URI를 통해 고유하게 식별할 수 있다.
- SLA(서비스 수준 협약, Service-Level Agreement)
- 서비스 제공자와 클라이언트 사이에 맺어지는 계약
- 여러 AZ(availability zone)에 걸쳐 99.999999999%의 객체 내구성을 제공
- 하나의 가용성 구역 전체가 소실되어도 데이터 복원 가능
- 연간 99.9%의 가용성 제공
- 서비스 제공자와 클라이언트 사이에 맺어지는 계약
1단계: 문제 이해 및 설계 범위 확정
- 다음 기능을 제공하는 S3와 유사한 객체 저장소 시스템 설계
- 버킷 생성
- 객체 업로드 및 다운로드
- 객처 버전
- 버킷 내 객체 목록 출력 기능(aws s3 ls)
- 아주 큰 객체(수 GB 이상)와 다량의 소형 객체(수 KB 정도)를 효율적으로 저장할 수 있어야함
- 매년 추가되는 데이터는 100PB
- 99.9999%의 데이터 내구성과 99.99% 서비스 가용성을 보장
비기능 요구사항
- 100PB 데이터
- 식스 나인(six nines, 99.9999%) 수준의 데이터 내구성
- 포 나인(four nines, 99.99%) 수준의 서비스 가용성
- 저장소 효율성
- 높은 수준의 안정성과 성능은 보증하되 저장소 비용의 최대한 낮춰야함
대략적 규모 추정
객체 저장소는 디스크 용량이나 초당 디스크 IO(IOPS)가 병목이 될 가능성이 높다.
- 디스크 용량: 객체 크기는 다음 분포를 따른다.
- 객체 가운데 20%는 그 크기가 1MB 미만의 작은 객체
- 60% 정도의 객체는 1MB ~ 64MB 정도의 중간 크기 객체
- 나머지 20% 정도는 64MB 이상의 대형 객체
- IOPS
- SATA 인터페이스를 탑재하고 7200rpm을 지원하는 하드 디스크 하나가 초당 100 ~ 150 임의 데이터 탐색을 지원할 수 있다고 가정(100 ~ 150 IOPS)
이 가정에 기반하여 시스템이 저장 가능한 객체 수를 가늠할 수 있다.
100PB = 100 * 1000 * 1000 * 1000MB = 10MB(10^11 * 0.4) / (0.2 * 0.5MB + 0.6 * 32MB + 0.2 * 200MB) = 6억 8천만 개- 모든 객체의 메타데이터 크기가 대략 1KB라고 가정하면 메타데이터 정보를 저장하기 위해 약 0.68TB 필요함
2단계: 개략적 설계안 제시 및 동의 구하기
객체 저장소의 속성
설계를 진행하기 전 설계안에 영향을 끼칠 수 있는 객체 저장소의 몇 가지 속성을 살펴본다.
- 객체 불변성(object immutability)
- 객체 저장소와 다른 두 가지 유형의 저장소 시스템의 가장 큰 차이는 객체 저장소에 보관되는 객체들은 변경이 불가능하다는 것이다.
- 삭제한 다음 새 버전 객체로 완전히 대체할 수는 있어도 그 값을 점진적으로 변경할 수는 없다.
- 키-값 저장소(key-value store)
- 객체 저장소를 사용하는 경우 해당 객체의 URI를 사용하여 데이터를 가져올 수 있다.
- 이때 URI는 키이고 데이터는 값에 해당하므로 키-값 저장소로 볼 수 있다.
- 저장은 1회, 읽기는 여러번
- 링크드인에서 조사한 결과에 따르면 객체 저장소에 대한 요청 가운데 95%가 읽기 요청
- 소형 및 대형 객체 동시 지원
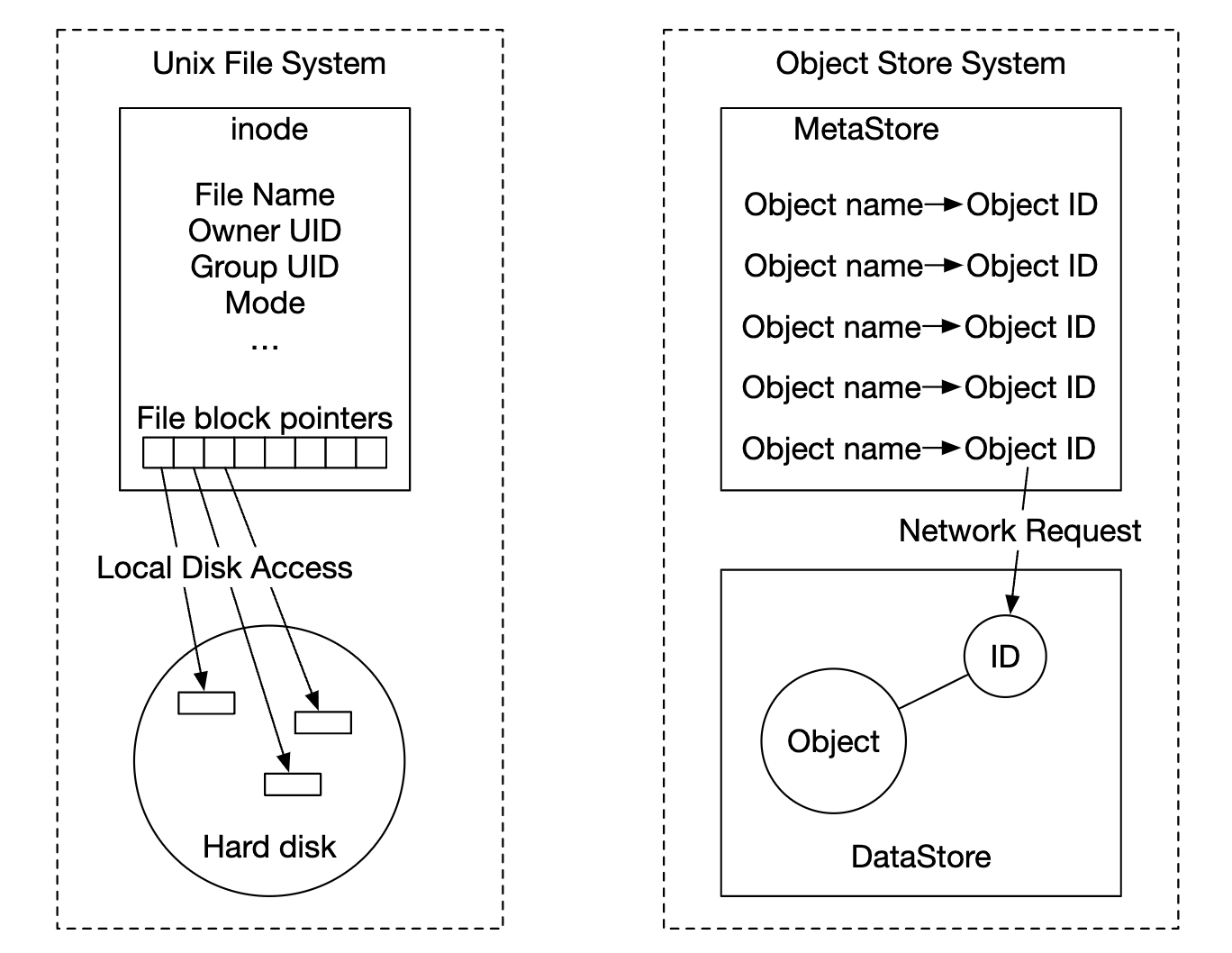
객체 저장소의 설계 철학은 UNIX 파일 시스템의 설계 철학과 아주 비슷하다.
- 파일을 로컬 파일 시스템에 저장하면 파일의 이름과 데이터는 같은 곳에 저장되지 않음
- 아이노드(inode)라고 불리는 자료 구조에 보관되고 파일의 데이터는 디스크의 다른 위치로 들어감
- 아이노드에는 파일 블록 포인터 목록(디스크상의 위치를 가르킴)이 들어감
객체 저장소의 동작 방식도 비슷하다.
- 객체 저장소의 메타데이터 저장소는 아이노드에 해당
- 파일 블록 포인터 대신 네트워크를 통해 데이터 저장소에 보관된 객체를 요청하는 데 필요한 식별자가 보관
- 데이터 저장소는 하드 디스크에 해당
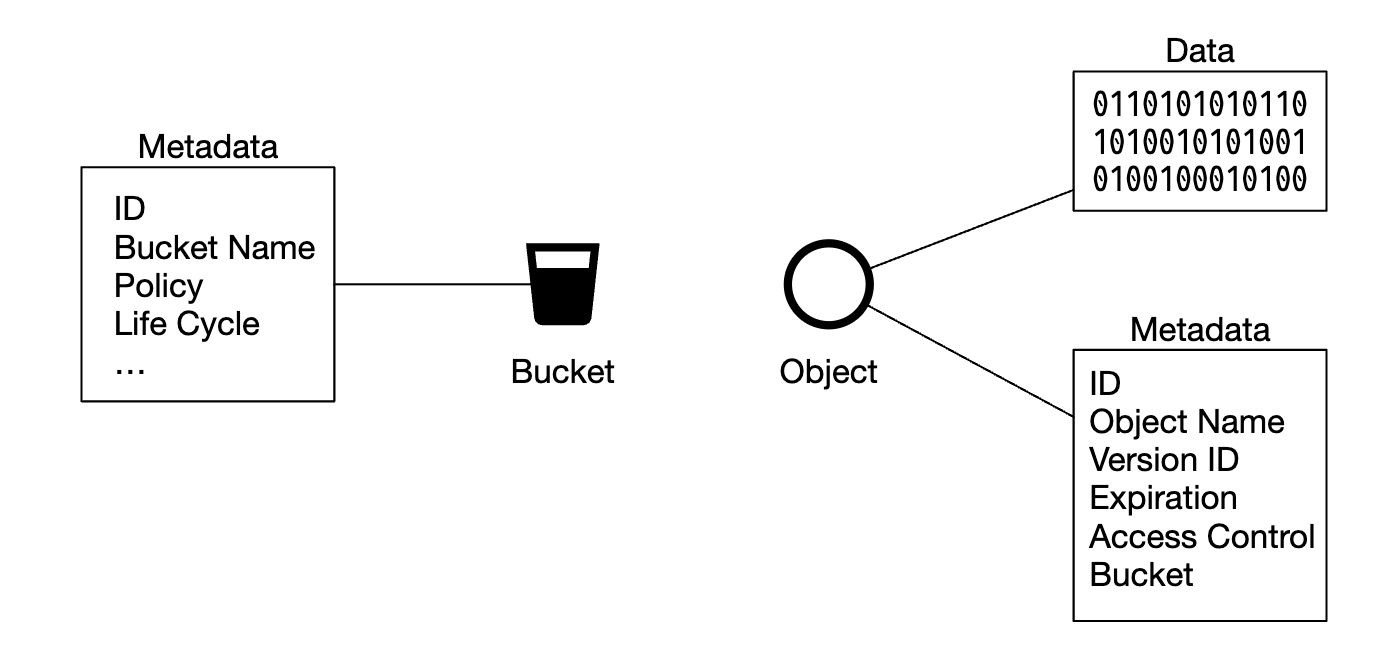
메타데이터와 객체의 실제 데이터를 분리하면 설계가 단순해진다.
- 데이터 저장소에 보관되는 데이터는 불변
- 메타데이터 저장소에 보관되는 데이터는 변경 가능
이렇게 분리해 두면 그 두 컴포넌트를 독립적으로 구현하고 최적화 할 수 있다.
개략적 설계안
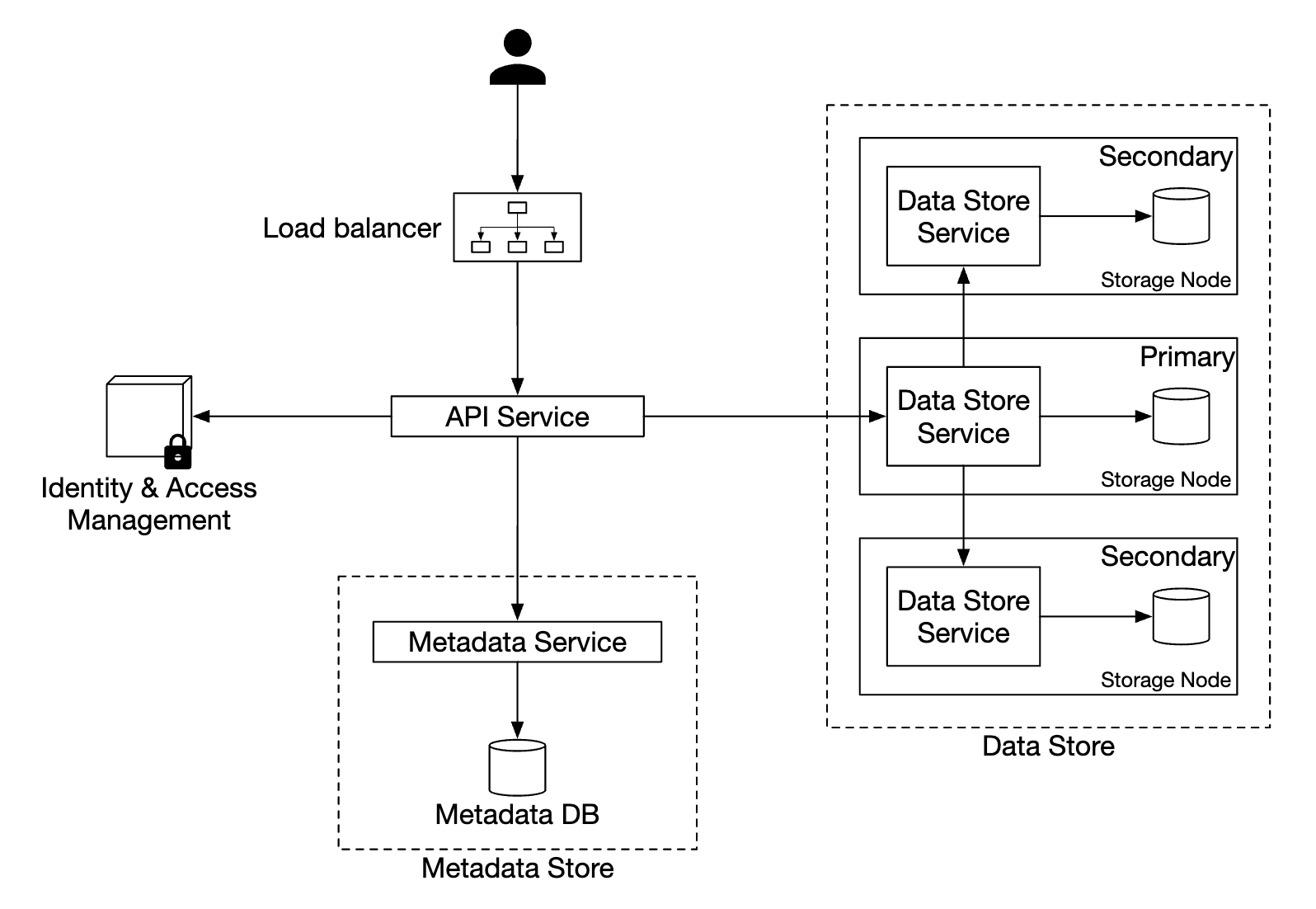
- 로드밸런서
- 요청을 API 서버들에 분산
- API 서비스
- IAM 서비스, 메타데이터 서비스, 저장소 서비스에 대한 호출을 조율하는 역할 담당
- 무상태 서비스이므로 수평적인 규모 확장이 가능
- IAM 서비스
- 인증, 권한 부여, 접근 제어 등을 중앙에서 맡아 처리
- 데이터 저장소
- 실제 데이터를 보관하고 필요할 때마다 읽어가는 장소
- 모든 데이터 관련 연산은 객체 ID(UUID)를 통함
- 메타데이터 저장소
- 객체 메타데이터를 보관
메타데이터 저장소와 데이터 저장소는 논리적은 구분이 뿐이며 구현 방법은 여러가지 있을 수 있다.
- RGW(Ceph’s Rados Gateway)는 독립적인 메타데이터 저장소를 두지 않고 객체 버킷을 포함한 모든 객체는 하나 이상의 라도스 객체로 저장됨
객체 업로드
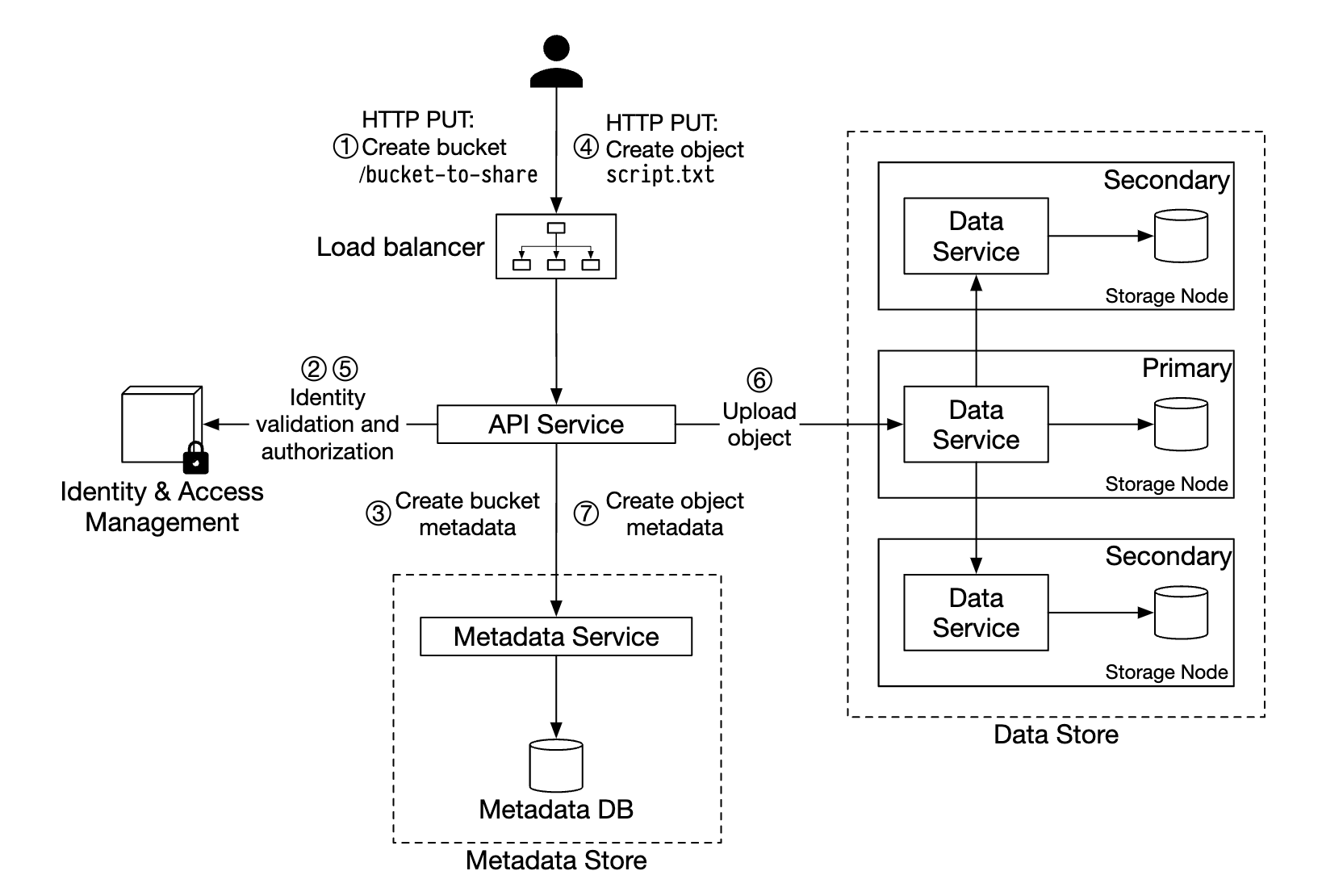
- 클라이언트는
bucket-to-share버킷을 생성하기 위한HTTP PUT요청을 보낸다. - API 서비스는 IAM을 호출하여
WRITE권한을 가졌는지 확인한다. - API 서비스는 메타데이터 데이터베이스에 버킷 정보를 등록하기 위해 메타데이터 저장소를 호출한다.
- 버킷 정보가 만들어지면 그 사실을 알리는 메시지가 클라이언트에 전송된다.
- 버킷이 만들어지고 나면 클라이언트는
script.txt객체를 생성하기 위한HTTP PUT요청을 보낸다. - API 서비스는 해당 사용자 신원 및
WRITE권한을 확인한다. - 문제가 없다면
HTTP PUT요청 body에 실린 객체 데이터를 데이터 저장소로 보낸다.- 데이터 저장소는 해당 데이터를 객체로 저장하고 해당 객체의 UUID를 반환한다.
- API 서비스는 메타데이터 저장소를 호출하여 새로운 항목을 등록한다.
object_id: UUIDbucket_id: 해당 객체가 속한 버킷object_name
객체 다운로드
버킷은 디렉터리 같은 계층 구조를 지원하지 않지만 버킷 이름과 객체 이름을 연결하면 폴더 구조를 흉내 내는 논리적 계층을 만들수는 있다.
- 객체 이름을
script.txt대신bucket-to-share/script.txt로 설정한다.
앞서 언급한 대로 데이터 저장소는 객체 이름을 보관하지 않으며 object_id(UUID)를 통한 객체 연산만 지원한다.
따라서 객체를 다운로드 하려면 객체 이름을 우선 UUID로 변환해야 한다.
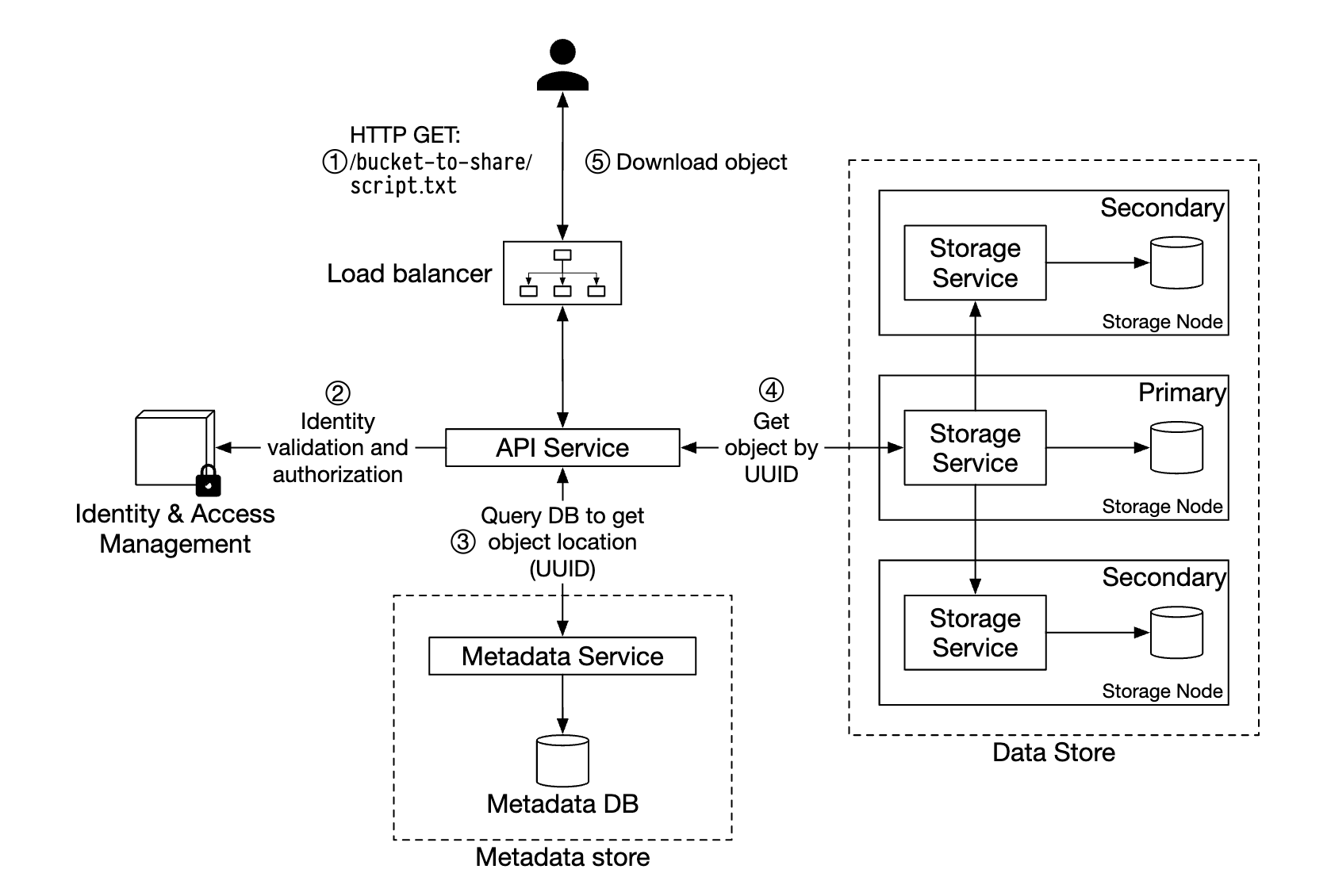
- 클라이언트는 요청을 로드밸런서로 보내고, 로드밸런서는 이 요청을 API 서버로 보낸다.
- API 서버는 IAM을 통해
READ권한 확인한다. - 권한이 있다면 해당 객체의 UUID를 메타데이터 자장소에서 가져온다.
- 해당 UUID를 이용해 ㄱ데이터 저장소에서 객체 데이터를 가져온다.
HTTP GET요청에 대한 응답으로 해당 객체 데이터를 반환한다.
3단계: 상세 설계
데이터 저장소
API 서비스는 사용자의 요청을 받으면 그 요청을 처리하기 위해 다른 내부 서비스들을 호출한다.
객체를 저장하거나 가져오는 작업은 데이터 저장소를 호출하여 치리한다.
데이터 저장소의 개략적 설계
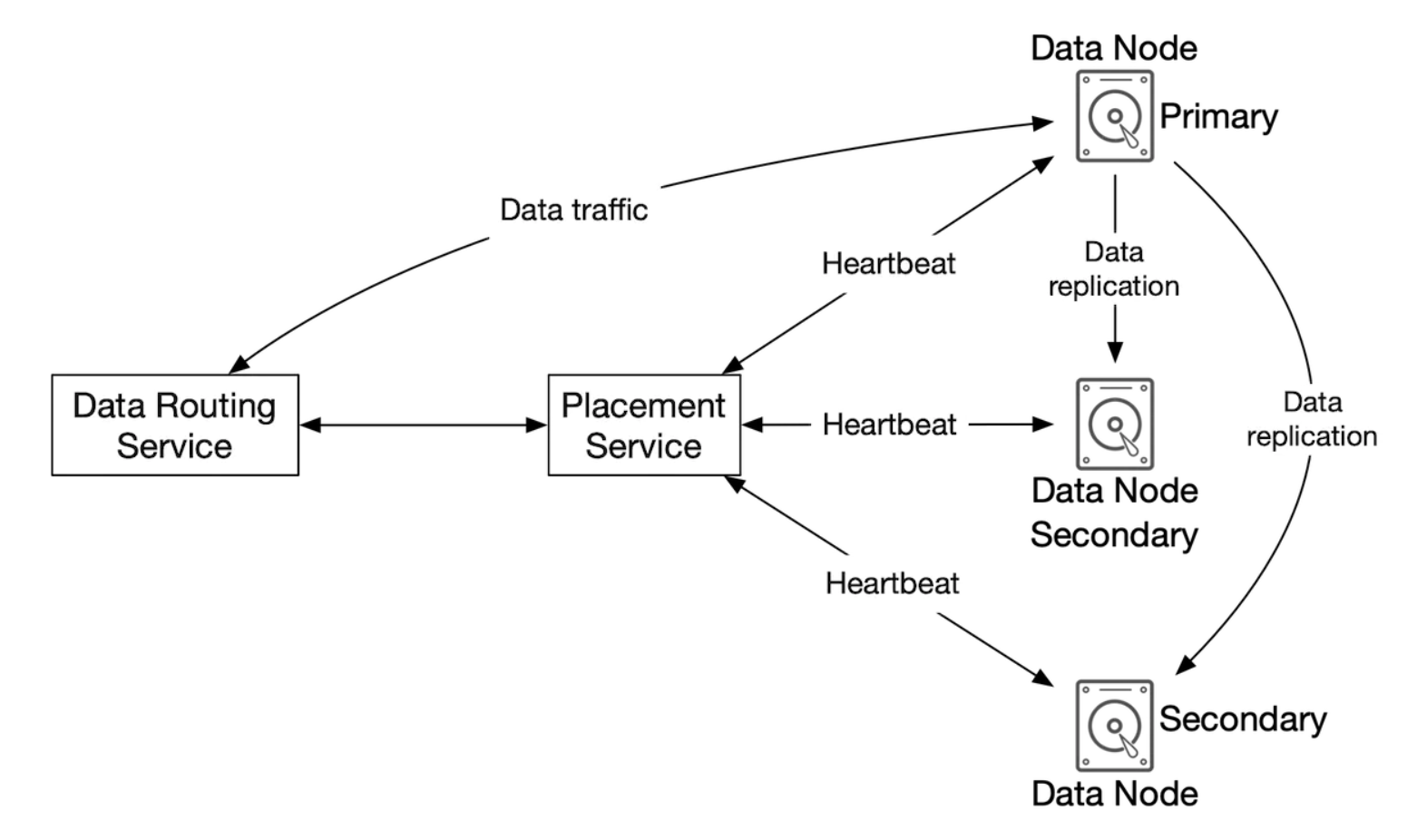
세 가지 주요 컴포넌트로 구성된다.
데이터 라우팅 서비스
데이터 노드 클러스터에 접근하기 위한 RESTful 또는 gRPC 서비스르 제공한다.
더 많은 서버를 추가하여 쉽게 규모를 확장할 수 있는 무상태 서비스다.
- 배치 서비스(placement service)를 호출하여 데이터를 저장할 최적의 데이터 노드를 판단
- 데이터 노드에서 데이터를 읽어 API 서비스에 반환
- 데이터 노드에 데이터 기록
배치 서비스
어느 데이터 노드에 데이터를 저장할 지 결정하는 역할을 담당한다.
- 데이터 노드에는 주 데이터 노드와 부 데이터 노드가 있다.
배치 서비스는 내부적으로 가상 클러스터 지도(virtual cluster map)를 유지하는데, 믈러스터의 물리적 형상 정보가 보관된다.
- 이 지도에 보관되는 데이터 노드의 위치 정보를 이용하여 데이터 사본이 물리적으로 다른 위치에 놓이도록 한다.
- 물리적인 분리는 높은 데이터 내구성을 달성하는 핵심 요소이다.
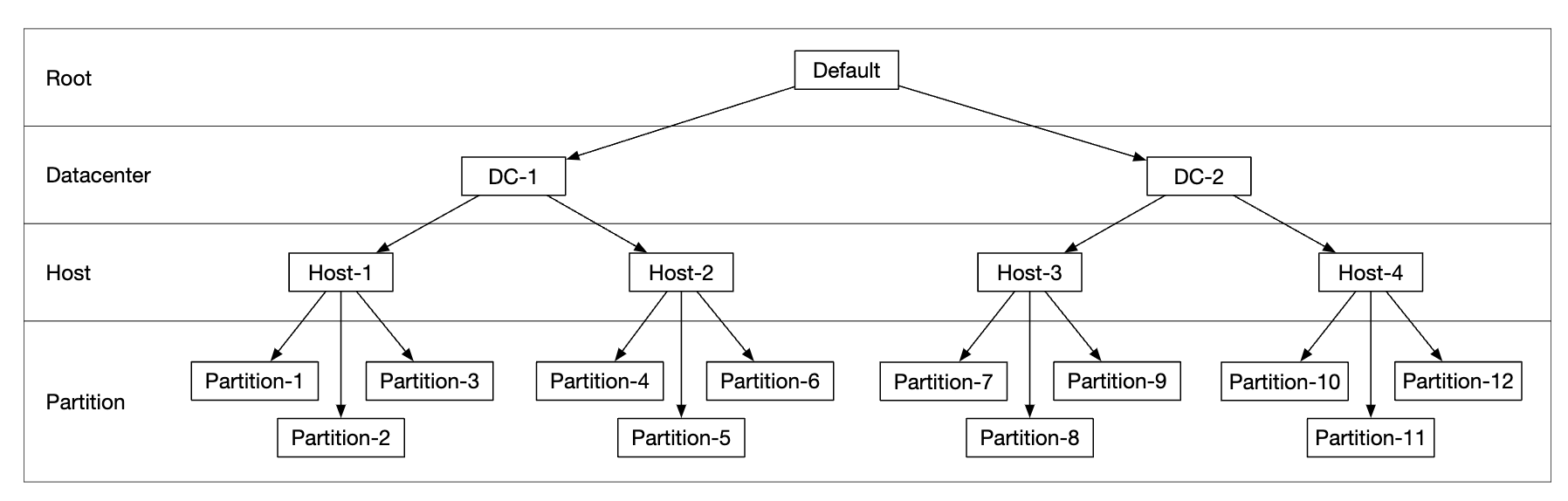
배치 서비스는 모든 데이터 노드와 지속적으로 박동 메시지를 주고받으며 상태를 모니터링 한다.
- 15초의 유예 기간(grace period) 동안 박동 메시지에 응답하지 않는 데이터 노드는 지도에 죽은 노드로 표시한다.
배치 서비스는 아주 중요한 서비스이므로 5개에서 7개의 노드를 갖는 배치 서비스 클러스터를 팩서스(Paxos)나 래프트(Raft) 같은 합의 프로토콜을 사용하여 구축살 것을 권장한다.
- 7개 노드로 구성된 배치 서비스 클러스터는 최대 3개까지의 노드 장애는 감내할 수 있다.
데이터 노드
실제 객체 데이터가 보관되는 곳으로 여러 노드에 데이터를 복제함으로써 데이터의 안정성과 내구성을 보증한다.(다중화 그룹, replication group)
각 데이터 노드에는 배치 서비스에 주기적으로 박동 메시지를 보내는 서비스 데몬(service daemon)이 돈다.
박동 메시지에는 다은과 같은 정보가 들어있다.
- 해당 데이터 노드에 부착된 디스크 드라이브(HDD/SSD) 수
- 각 드라이브에 저장된 데이터의 양
배치 서비스는 못 보던 데이터 노드에서 박동 메시지를 처음 받으면 해당 노드에 ID를 부여하고 가상 클러스터 지도에 추가한 다음, 아래 정보를 반환한다.
- 해당 데이터 노드에 부여한 고유 식별자
- 가상 클러스터 지도
- 데이터 사본을 보관할 위치
데이터 저장 흐름
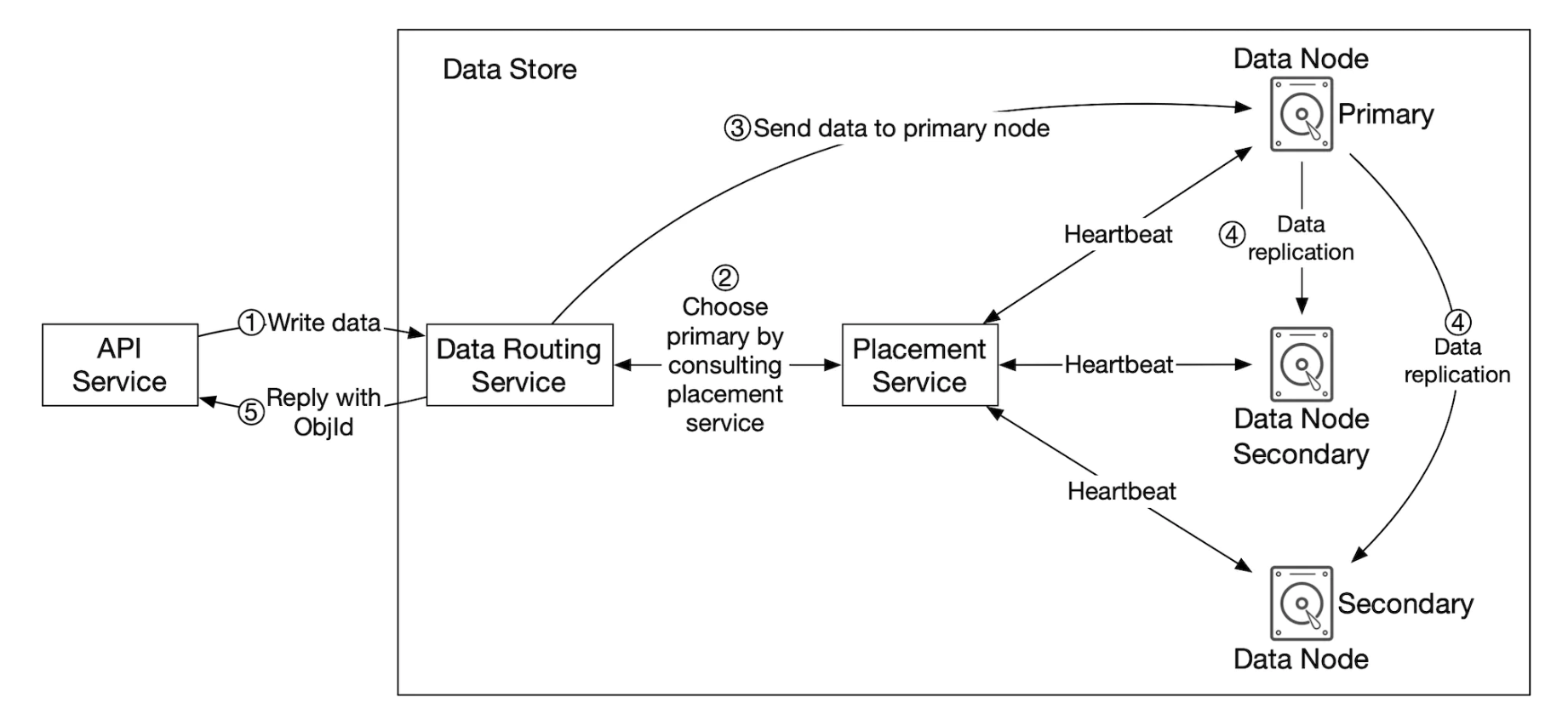
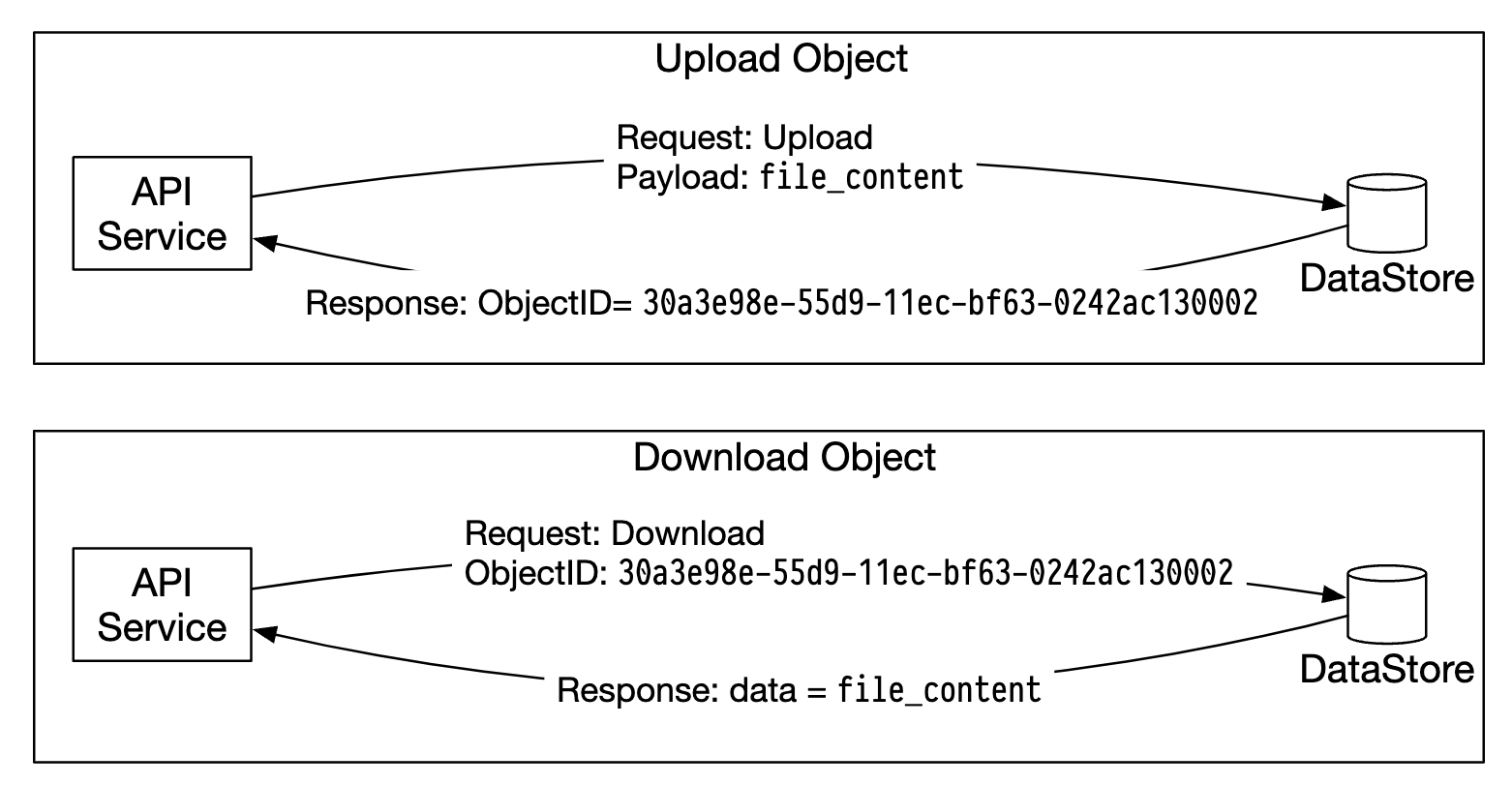
- API 서비스는 객체 데이터를 데이터 저장소로 포워딩한다.
- 데이터 라우팅 서비스는 해당 객체에 UUID를 할당하고 배치 서비스에 해당 객체를 보관할 데이터 노드를 질의한다.
- 배치 서비스는 가상 클러스터 지도를 확인하여 데이터를 보관할 주 데이터 노드를 반환한다.
- 데이터 라우팅 서비스는 저장할 데이터를 UUID와 함께 주 데이터 노드에 직접 전송한다.
- 주 데이터 노드는 데이터를 자기 노드에 지격적으로 저장하면서 두 개의 부 데이터 노드에 다중화한다.
- 주 데이터 노드는 데이터를 모든 부 데이터 노드에 성공적으로 다중화하고 나면 데이터 라우팅 서비스에 응답을 보낸다.
- 객체의 UUID(객체 ID)를 API 서비스에 반환한다.
2단계는 배치 서비스에 UUID를 입력으로 주고 질의하면 해당 객체에 대한 다중화 그룹이 반환된다는 뜻이다.
- 계산 결과는 결정적(deterministric)이어야 한다.
- 다중화 그룹이 추가되거나 삭제되는 경우에도 유지되어야 한다.
- 안정해시를 주로 사용한다.
4단계는 응답을 반환하기 전 데이터를 모든 부 노드에 다중화하여 모든 데이터 노드에 강력한 데이터 일관성을 보장한다.
- 가장 느린 사본에 대한 작업이 완료될 때까지 응답을 반환하지 못하므로, 지연 시간 측면에서는 손해이다.
데이터 일관성과 지연 시간의 관계
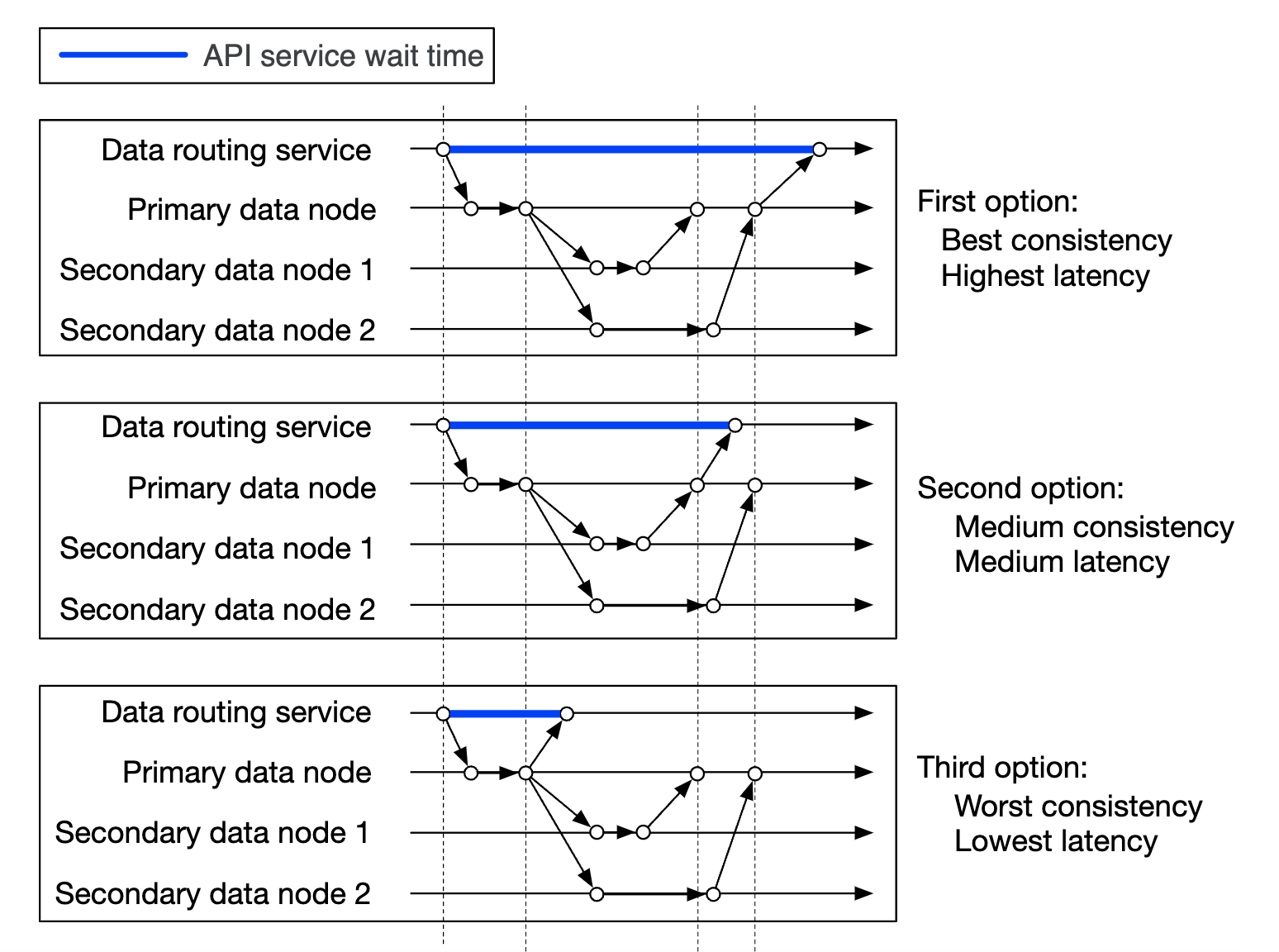
- 데이터를 세 노드에 전부 보관하면 성공적으로 보관하였다고 간주
- 데이터 일관성 측면에서는 최선이지만 응답 지연은 가장 높다.
- 데이터르 주 데이터 및 두 개 부 노드 가운데 하나에 성공적으로 보관하면 성공적으로 저장하였다고 간주
- 중간 정도의 데이터 일관성 및 응답 지연을 제공
- 데이터를 주 데이터에 보관하고 나면 성공적으로 저장했다고 간주
- 데이터 일관성 측면에서는 최악이지만 응답 지연은 가장 낮다.
2, 3은 모두 결과적 일관성(eventual consistency)의 한 형태로 볼 수 있다.
데이터는 어떻게 저장되는가
가장 단순한 방안은 각각의 객체를 개별 파일로 저장하는 것 이지만 작은 파일이 많아지면 성능이 떨어진다.
- 낭비되는 데이터 블록 수가 늘어난다.
- 파일 시스템은 보통 4KB의 디스크 블록으로 파일을 저장하는데 크기가 작아도 하나의 블록을 모두 사용한다.
- 시스템의 아이노드(inode) 용량 한계를 초과할 수 있다.
- 사용 가능한 아이노드 수는 디스크가 초기화 되는 순간 결정되고, 작은 파일의 수가 매우 많아지면 전부 소진될 수 있다.
- 파일 시스템 메타데이터를 공격적으로 캐싱하는 전략을 취하더라도 아주 많은 양의 아이노드를 효과적으로 처리하지 못한다.
따라서 작은 객체를 개별 파일 형태로 저장하는 방안은 현실에서는 쓸모없으며, 작은 객체들을 큰 파일 하나로 모아서 처리해야한다.
- 개념적으로는 WAL(Write-Ahead Log)와 같이 객체를 저장할 때 이미 존재하는 파일에 추가하는 방식
- 용량 임계치에 도달한 파일(보통 수 GB)은 읽기 전용 파일로 변경하고 새로운 파일을 만든다.
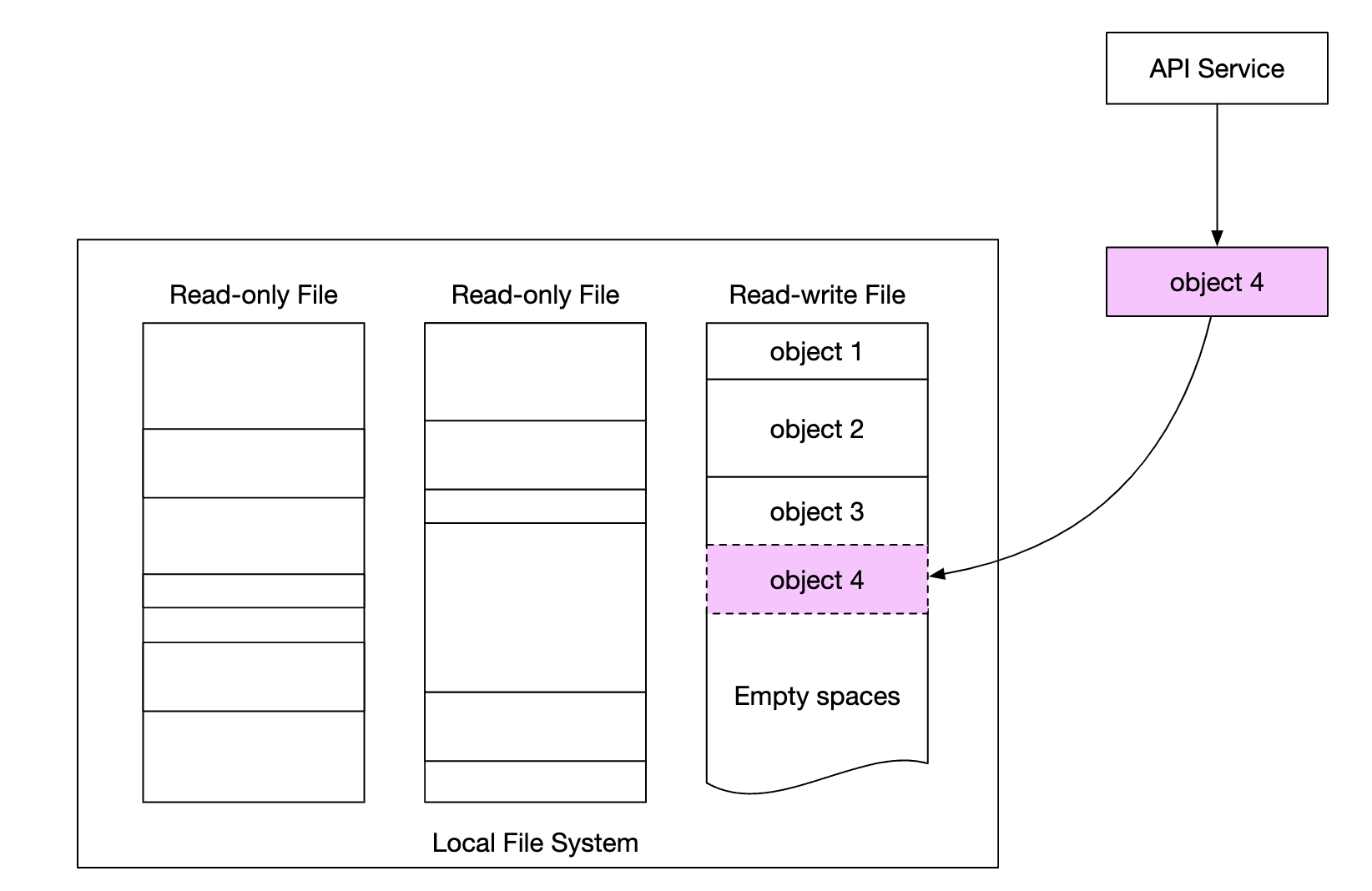
- 읽기-쓰기 파일에 대한 쓰기 연산은 순차적으로 이루어져야 함
- 객체는 파일에 일렬로 저장됨
- 여러 CPU 코어가 쓰기 연산을 병렬로 진행하더라도 객체 내용이 뒤섞이면 안된다.
- 파일에 객체를 기록하기 위해 순서를 기다려야 한다.
- 쓰기 대역폭이 심각하게 줄어들기 때문에 서버에 오는 요청을 처리하는 코어별로 전담 읽기-쓰기 파일을 두는 것이 좋다.
객체 소재 확인
각각의 데이터 파일 안에 많은 작은 객체가 들어 있다면 데이터노드가 UUID로 객체를 찾기 위해 다음 정보가 필요하다.
- 객체가 보관된 데이터 파일
- 데이터 파일 내 객체 오프셋
- 객체 크기
classDiagram
class object_mapping {
object_id
file_name
start_offset
object_size
}
이 정보를 저장하는 데 두 가지 방법이 있다.
- 파일 기반 키-값 저장소(ex. RocksDB)
- SSTable에 기반한 방법으로 쓰기 연산 성능은 좋지만 읽기 성능은 느리다.
- 관계형 데이터베이스
- B+ 트리 기반 저장 엔진을 이용하며 읽기 연산 성능은 좋지만 쓰기 성능은 느리다.
객체 저장소의 데이터는 한 번 기록된 후에는 변경되지 않고, 읽기 연산이 매우 많이 발생하므로 읽기 연산 성능이 좋은 관계형 데이터베이스가 더 나은 선택이다.
객체 위치를 저장하는 테이블의 데이터 양은 막대하므로, 하나의 거대 클러스터에 모든 데이터 노드를 저장하는 방안도 가능하지만 관리가 까다롭다.
하지만 데이터 노드에 저장되는 위치 데이터를 다른 데이터 노드와 공유할 필요가 없기 때문에 데이터 노드마다 관계형 데이터베이스를 설치하는 방안이 가능하다.
- SQLite는 이런 경우 딱 만는 파일 기반 관계형 데이터베이스이다.
개선된 데이터 저장 흐름
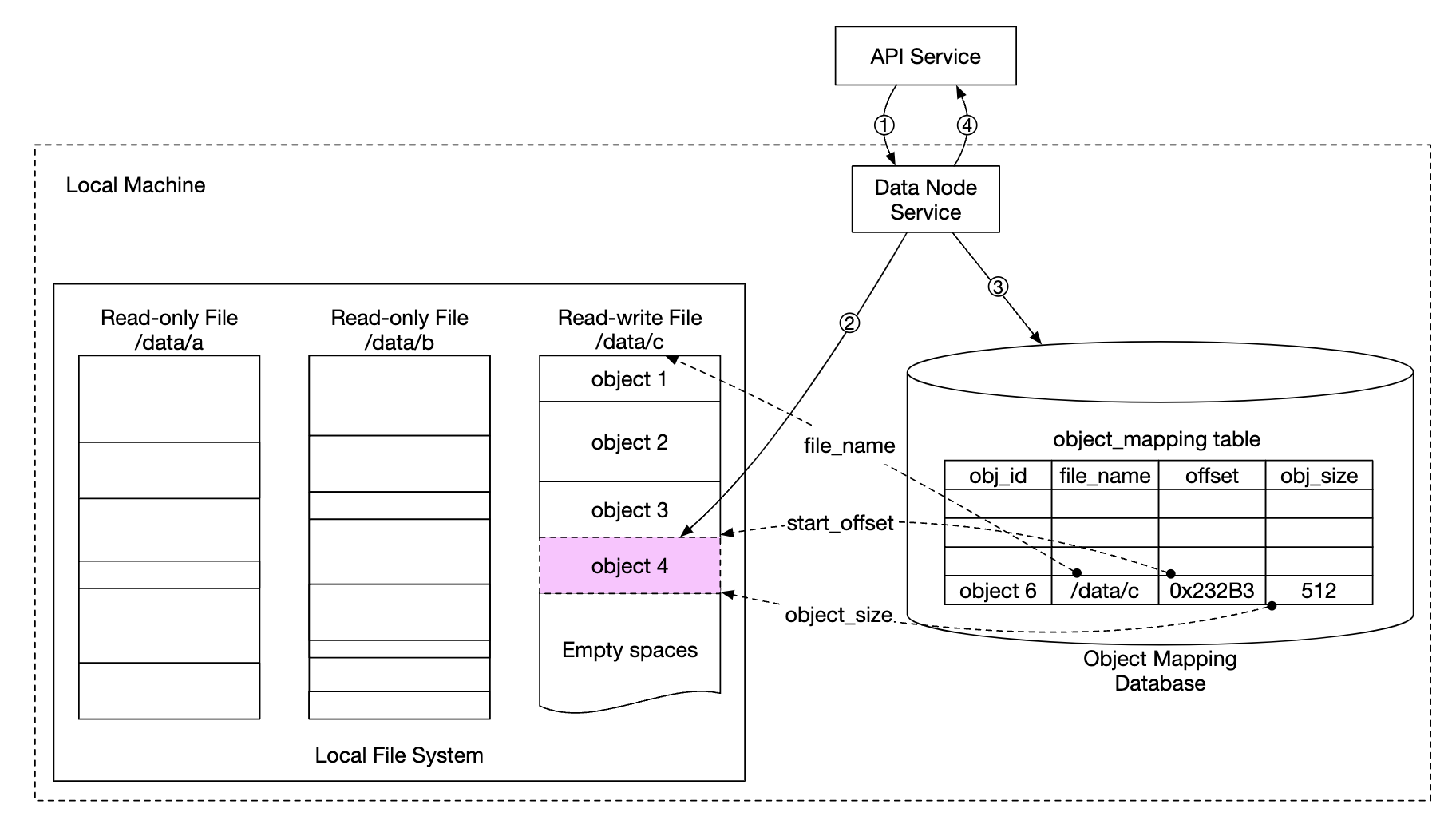
- API 서비스는 새로운 객체를 저장하는 요청을 데이터 노드 서비스에 전송한다.
- 데이터 노드 서비스는 새로운 객체를 읽기-쓰기 파일
/data/c의 마지막 부분에 추가한다. - 해당 객체에 대한 새로운 레코드를
object_mapping테이블에 추가한다. - 데이터 노드 서비스는 API 서비스에 해당 객체의 UUID를 반환한다.
데이터 내구성
데이터 안정성은 데이터 저장 시스템에 아주 중요하다.
식스 나인 수준의 데이터 내구성을 제공하는 저장소 시스템을 만들려면 장애가 발생할 모든 경우를 세심하게 살핀 다음 데이터를 적절히 다중화해야한다.
하드웨어 장애와 장애 도메인
기록 매체 종류와 관계없이, 하드 디스크 장애는 필할 수 없기 때문에 드라이브 한 대로 원하는 내구성 목표를 달성 불가능하다.
내구성을 높이는 검증된 방법은 데이터를 여러 대의 하드 드라이브에 복제하여 어떤 드라이브에서 발생한 장애가 전체 데이터 가용성에 영향을 주지 않도록 하는 것 이다.
본 설계안에서는 데이터를 3중 복제 한다.
- 회전식 드라이브 연간 장애율이 0.81%라면 3중 복제했을 때 내구성은
1 - 0.0081^3 = ~0.999999이다.
완전한 내구성 평가를 위해서는 여러 장애 도메인의 영향을 복합적으로 고려할 필요가 있다.
장애 도매인
중요한 서비스에 문제가 발생했을 때 부정적인 영향을 받는 물리적 또는 논리적 구획
대규모의 장애 도메인 사례로는 데이터센터의 가용성 구역(Availability Zone, AZ)가 있다.(다른 데이터센터와 물리적 인프라를 공유하지 않는 독립적 데이터센터 하나)
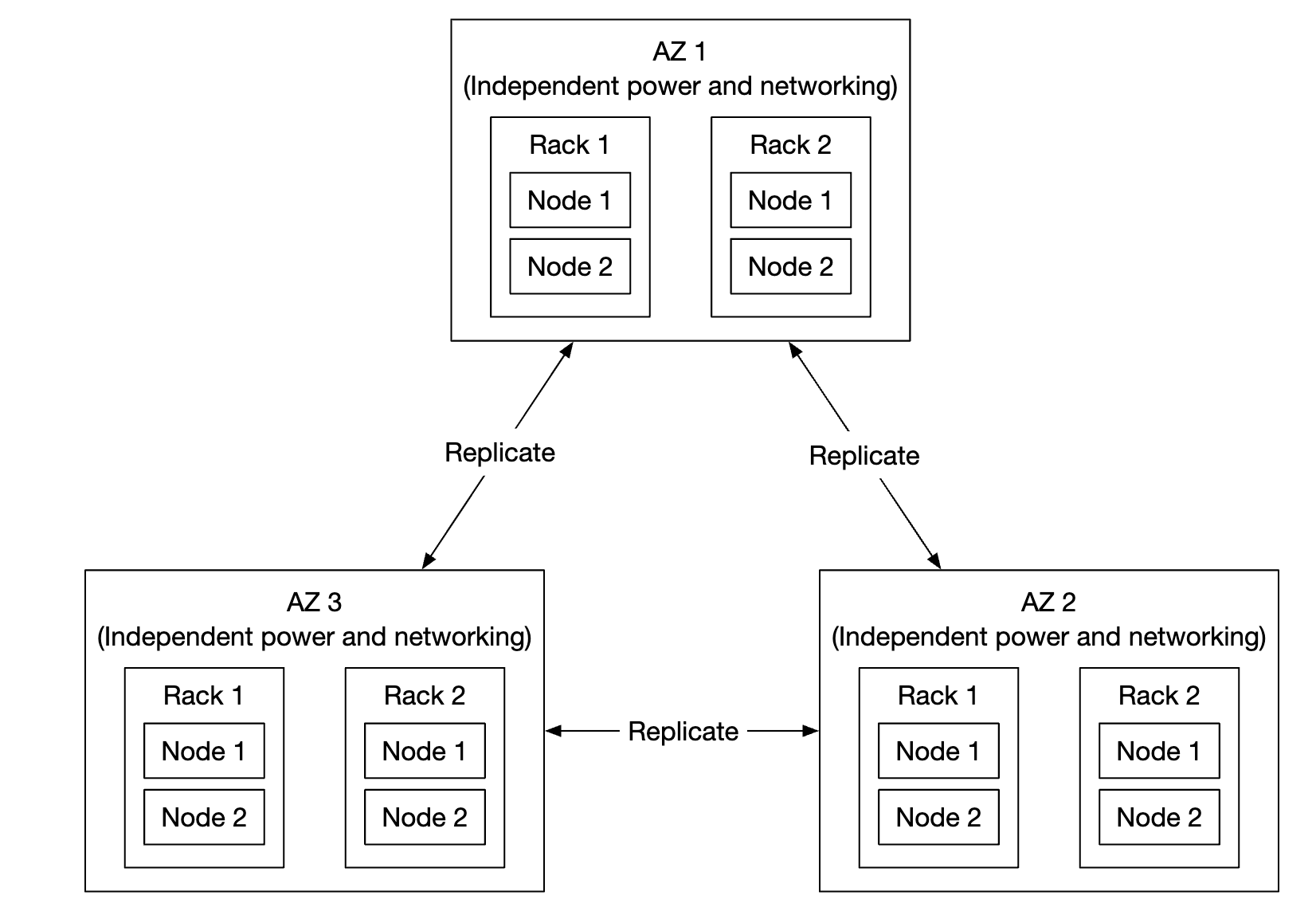
데이터를 여러 AZ에 복제해 놓으면 장애 여파를 최소화할 수 있다.
소거 코드
소거 코드(erasure coding)라는 방안으로 내구성을 달성하는 방안도 고려할 수 있다.
데이터를 작은 단위로 분할하여 다른 서버에 배치하는 한편, 그 가운데 일부가 소실되었을 때 복구하기 위한 패리티(parity)라는 정보를 만들어 중복성(redundancy)를 확보한다.
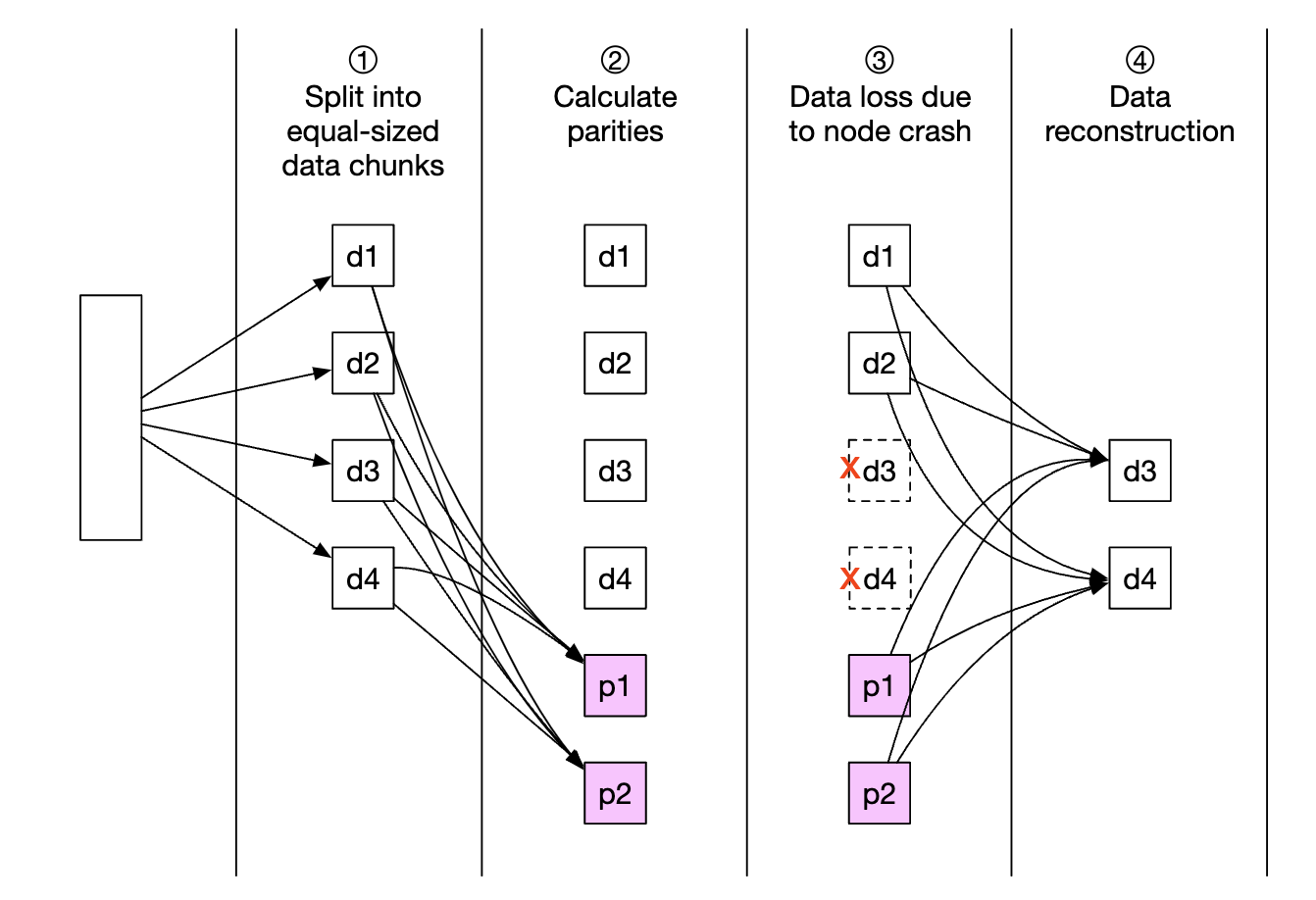
장애가 생기면 남은 데이터와 패리티를 조합하여 소실된 부분을 복구한다.
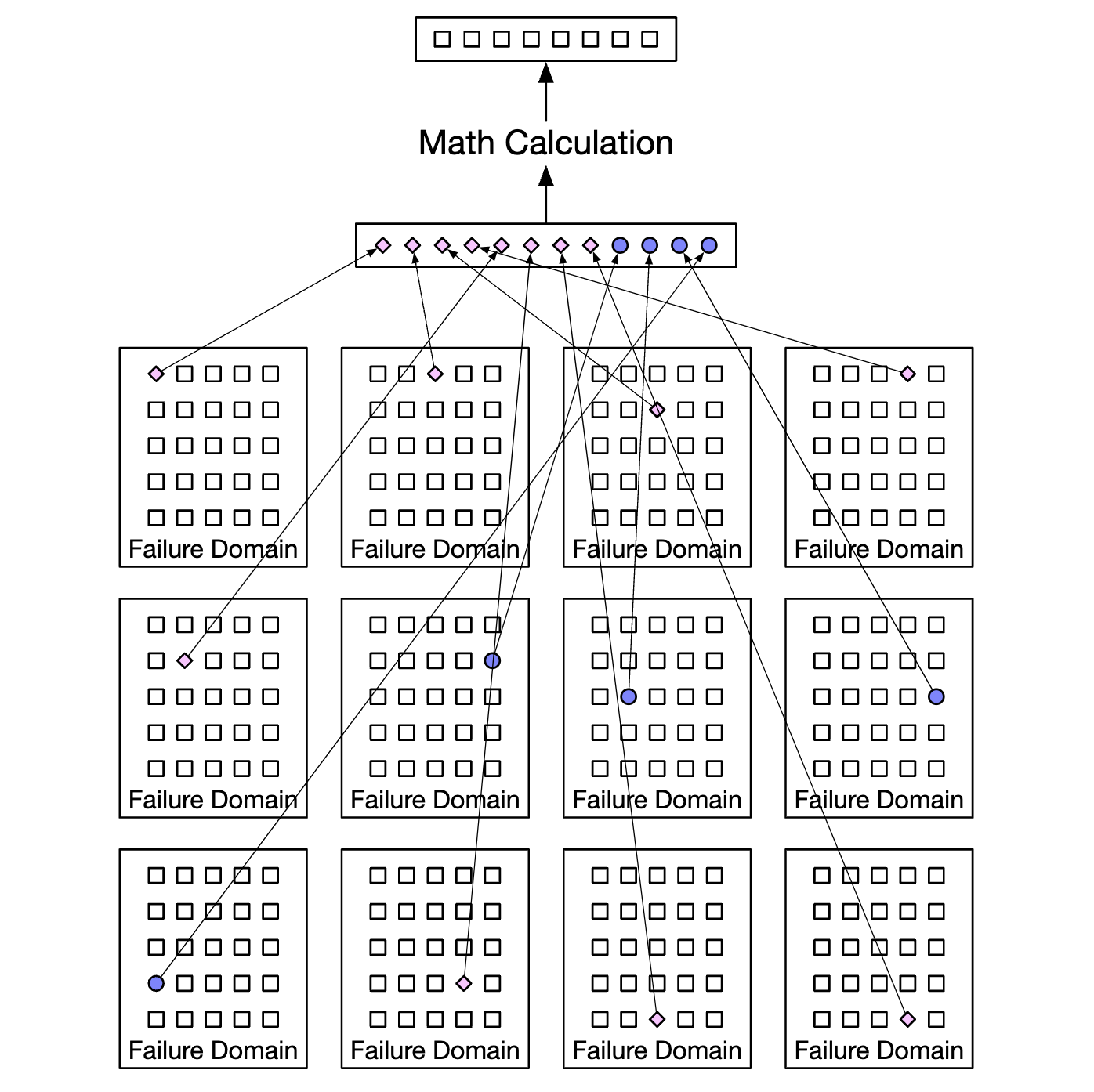
- 원본 데이터는 8조각으로 분할하고 4개의 패리티를 계산
- 그 결과로 만들어진 12조각의 데이터는 전부 같은 크기로, 12개의 장애 도메인에 분산
소거 코드 이며느이 수식으로 최대 4대 노드에 장애가 동시에 발생하더라도 원본 데이터를 복원해 낼 수 있다.
데이터를 다중화 할 경우 데이터 라우터는 객체 데이터를 하나의 건강한 노드에서 읽으면 충분하겠지만 소거 코드를 사용하면 최대 8개의 건강한 노드에서 데이터를 가져와야 한다.
- 응답 지연은 높아지는 대신 내구성은 향상되고 저장소 비용은 낮아진다.
- 객체 저장소는 저장 비용이 대부분이어서 고려할 가치가 있다.
- 소거 코드를 사용하면 2개 데이터 블록에 하나의 패리티 블록이 필요하므로 저장 공간이 50% 더 필요하다.
- 3중 복제 다중화 방안을 채택한다면 200%
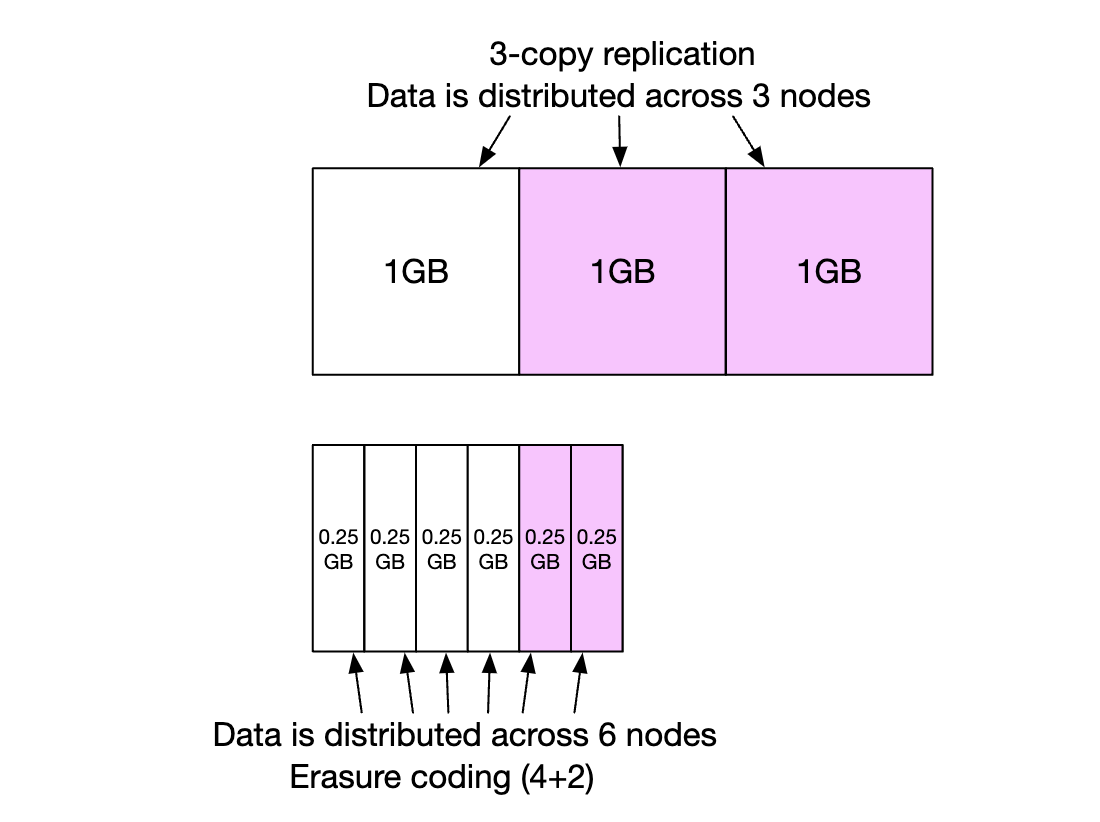
소거 코드를 사용하면 노드의 연산 장애 발생률이 0.81%라고 했을 때 11 나인 내구성을 달성할 수 있다.
비교
| 다중화 | 소거 코드 | |
|---|---|---|
| 내구성 | 3중 복제시 4-nines | 8+4 소거 코드 사용시 11-nines |
| 저장소 효율성 | 200% 오버헤드 | 50%의 오버헤드 |
| 계산 자원 | 계산이 필요없음 | 패리티 계산에 많은 계산 자원 소모 |
| 쓰기 성능 | 데이터를 여러 노드에 복제하므로 추가로 필요한 계산은 없음 | 데이터를 디스크에 기록하기 전에 패리티 계산이 필요하므로 쓰기 연산의 응답 지연 증가 |
| 읽기 성능 | 장애가 발생하지 않은 노드에서 데이터를 읽음 | 데이터를 읽어야할 때마다 클러스터 내의 여러 노드에서 데이터를 가져와야 함. 장애가 발생한 경우 빠진 데이터를 먼저 복원해야하므로 지연 시간 증가 |
- 응답 지연이 중요한 애플리케이션에서는 다중화 방안이 좋을 수 있다.
- 저장소 비용이 중요한 애플리케이션에서는 소거 코드가 좋을 수 있다.
소거 코드는 비용 효율과 내구성 측면에서 매력적이지만 데이터 노드의 설계 측면에서는 까다롭다.
정확성 검증
대규모 시스템의 경우 데이터 훼손 문제는 디스크에 국한되지 않고, 메모리의 데이터가 망가지는 일도 자주 일어난다.
메모리 데이터가 훼손되는 문제는 프로세스 경계에 데이터 검증을 위한 체크섬을 두어 해결할 수 있다.
체크섬
데이터 에러를 발견하는 데 사용되는 작은 크기의 데이터 블록
원본 데이터의 체크섬을 알면 전송 받은 데이터의 정확성은 해당 데이터의 체크섬을 다시 계산한 후 다음과 절차로 확인한다.
- 새로 계산한 체크 섬이 원본 체크섬과 다르면 데이터가 만가진 것이다.
- 같은 경우에는 아주 높은 확률로 데이터는 온전하다고 볼 수 있다.
- 100%는 아니지만 아주 낮다.
좋은 체크섬 알고리즘은 입력이 조금이라도 달라지면 크게 달라진 체크섬을 내놓는다.
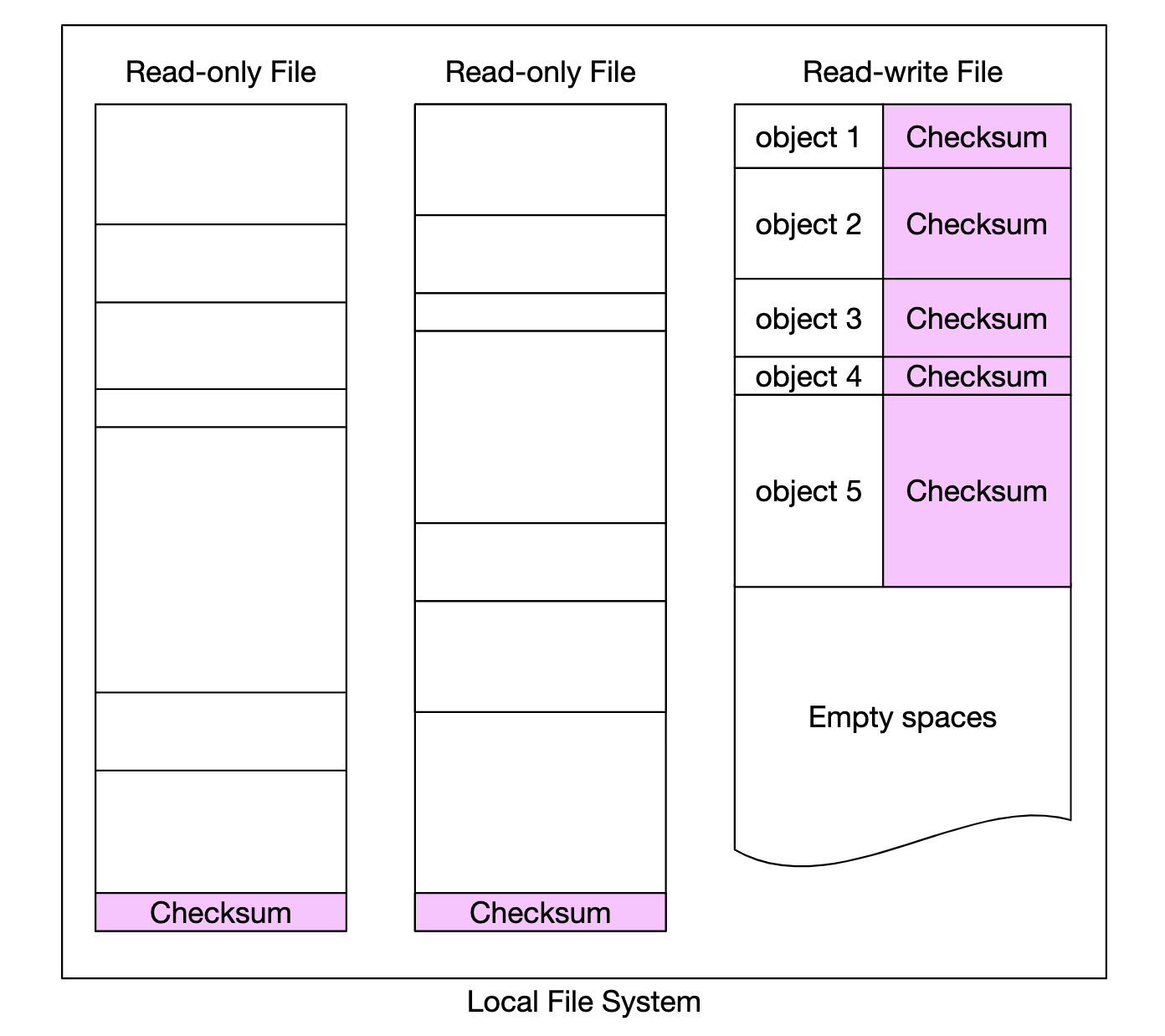
체크섬은 객체 데이터 끝에 두며, 파일을 읽기 전용으로 전환하기 직전에 전체 파일의 체크섬을 계산한 후 파일 끝에 추가한다.
(8 + 4) 소거 코드와 체크섬 확인 매커니즘을 동시에 활용하는 경우 객체 데이터를 읽을 때마다 다음 절차를 수행한다.
- 객체 데이터와 체크섬을 가져온다.
- 수신된 데이터의 체크섬을 계산한다.
- 두 체크섬이 일치하면 데이터에는 에러가 없다고 간주한다.
- 체크섬이 다르면 망가진 것 이므로 다른 장애 도메인에서 데이터를 가져와 복구를 시도한다.
- 데이터 8조각을 전부 수신할 때 까지 1과 2를 반복한 후, 원래 객체를 복원한 다음 클라이언트에게 보낸다.
메타데이터 데이터 모델
스키마
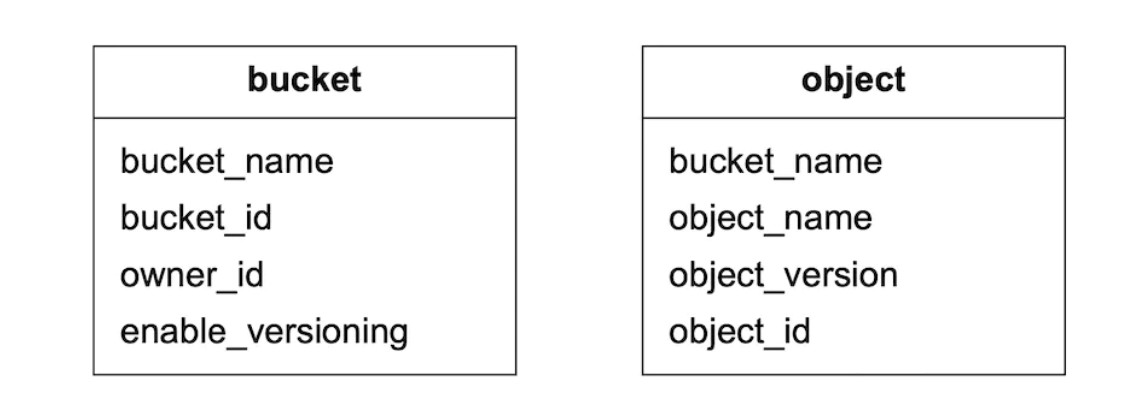
이 데이터베이스 스키마는 다음 3가지 질의를 지원해야한다.
- 객체 이름으로 객체 ID 찾기
- 객체 이름에 기반하여 객체 삽입 또는 삭제
- 같은 접두어를 갖는 버킷 내의 모든 객체 목록 확인
bucket 테이블 규모 확장
보통 한 사용자가 만들 수 있는 버킷의 수에는 제한이 있으므로, 테이블의 크기는 작기 때문에 최신 데이터베이스 서버 한 대에 충분히 저장할 수 있다.
- 백만명 고객이 10개의 버킷을 가지고 있고, 레코드가 10KB라면 10GB 정도 필요함
하지만 모든 읽기 요청을 처리하기에는 CPU 용량이나 네트워크 대역폭이 부족할 수 있으므로, 데이터베이스 사본을 만들어 읽기 부하를 분산한다.
object 테이블의 규모 확장
object 테이블에는 객체 메타데이터가 보관되는데, 설계안이 다루는 규모의 경우 객체 메타데이터를 데이터베이스 서버 한 대에 보관하기는 불가능하므로 샤딩을 통해 확장해야한다.
- 테이블을 샤딩할 때
bucket_id을 샤딩키로 사용하게되면, 핫스팟 샤드를 지원하지 못하므로 좋은 방안은 아니다. object_id를 기준으로 샤딩하면 부하를 균등하게 분산할 수는 있지만 URI를 기준으로 동작하는 질의 1, 2를 효율적으로 지원하지 못한다.
대부분의 메타데이터 관련 연산이 객체 URI를 기준으로 하는 특성을 고려하여 bucket_name과 object_name을 결합하여 샤딩에 사용한다.
bucket_name과 데이터를 균등하게 분산하기위해object_name의 순서쌍을 해싱한 값을 샤딩키로 사용한다.
버킷 내 객체 목록 확인
객체 저장소는 객체를 파일 시스템처럼 계층적 구조로 보관하지 않는다.
s3://mybucket/abc/d/e/f/file.txt와 같은 경로가 있다면
mybucket은 버킷 이름abc/d/e/f/file.txt는 파일 이름
S3는 사용자가 버킷 내 객체들을 잘 정리할 수 있도록 접두어(prefix)라는 개념을 지원한다.
접두어는 객체 이름의 시작 부분 문자열을 일컫는데, 잘 사용한다면 디렉터리와 비슷하게 데이터를 잘 정리할 수 있다.
하지만 접두어는 디렉터리가 아니므로 어떤 접두어에 대응되는 객체 목록을 얻으려 하면 오직 해당 접두어로 시작하는 이름의 객체만 반환될 것이다.
s3://mybucket/abc/d/e/f/file.txt의 접두어는abc/d/e/f
S3가 제공하는 목록 출력 명령어는 보통 다음과 같이 쓰인다.
- 어떤 사용자가 가진 모든 버킷 목록 출력
1aws s3 list-buckets - 주어진 접두어를 가진 같은 버킷 내 모든 객체 목록 출력
1aws s3 ls s3://mybucket/abc/ - 주어진 접두어를 가진, 같은 버킷 내 모든 객체를 재귀적으로 출력
1aws s3 ls s3://mybucket/abc/ --recursive
단일 데이터베이스 서버
단일 데이터베이스 서버로 목록 출력 명령어를 어떻게 지원하는지 살펴본다.
| |
목록 출력 명령어의 두번째 명령과 같이 해당 접두어 이후에 더 많은 샐래시 기호가 포함된 이름을 가진 객체들을 디렉터리처럼 보이도록 묶는 작업은 애플리케이션에서 담당한다.
분산 데이터베이스
메타데이터 테이블을 샤딩하면 어떤 샤드에 데이터가 있는지 모르므로 목록 출력 기능을 구현하기 어렵다.
가장 단순한 해결책은 검색 질의를 모든 샤드에 돌린 다음 결과를 취합하는 것 이지만 페이지 나눔(pagination) 기능을 구현하기 복잡하다.
객체가 여러 샤드에 나눠져 있으므로, 샤드마다 반호나하는 객체 수는 제각각이다.
- 어떤 샤드에는 한 페이지를 꽉 채울 객체가 있을 수 있지만, 적거나 없는 샤드도 있을 수 있다.
애플리케이션 코드는 모든 샤드의 질의 결과를 받아 취합한 다음 정렬하여 그중 10개만 추려야한다.
- 이번에 반환할 페이지에 포함되지 못한 객체는 다음에 다시 고려해야하므로, 샤드마다 추적해야하는 오프셋이 달라질 수 있다.
따라서 서버는 모든 샤드의 오프셋을 추적하여 커서에 결부시킬수 있어야 하므로 관리가 어려워진다.
이 문제를 해결할 방법은 있으나 객체 저장소는 규모와 내구성 최적화에 치중하고, 객체 목록 출력 명령의 성능을 보장하는 것은 우선순위가 낮다.
그 사실을 감안하여 버킷 ID로 샤딩하는 별도 테이블에 목록 데이터를 비정규화할 수 있다.
- 객체 목록을 출력할 때는 이 테이블에 있는 데이터만 사용한다.
- 목록 질의문을 한 대의 데이터베이스 서버로 돌릴 수 있으므로, 구현을 단순하게 만들 수 있다.
객체 버전
객체 버전은 버킷 안에 한 객체의 여러 버전을 둘 수 있도록 하는 기능으로 실수로 지우거나 덮어 쓴 객체를 쉽게 복구할 수 있다.
문서를 수정한 다음 같은 버킷 안에 같은 이름으로 저장했다면
- 버전 기능이 없으면
- 해당 문서의 이전 메타데이터는 새 메타데이터로 완전히 대체된다.
- 이전 문서는 삭제된 것으로 표시되고, 쓰레기 수집기가 회수한다.
- 버전 기능이 있으면
- 객체 저장소는 해당 문서의 모든 이전 버전을 메타데이터 저장소에 유지한다.
- 이전 버전에 삭제 표시를 할 수 있다(안해도 된다.)
버전이 다른 객체 업로드
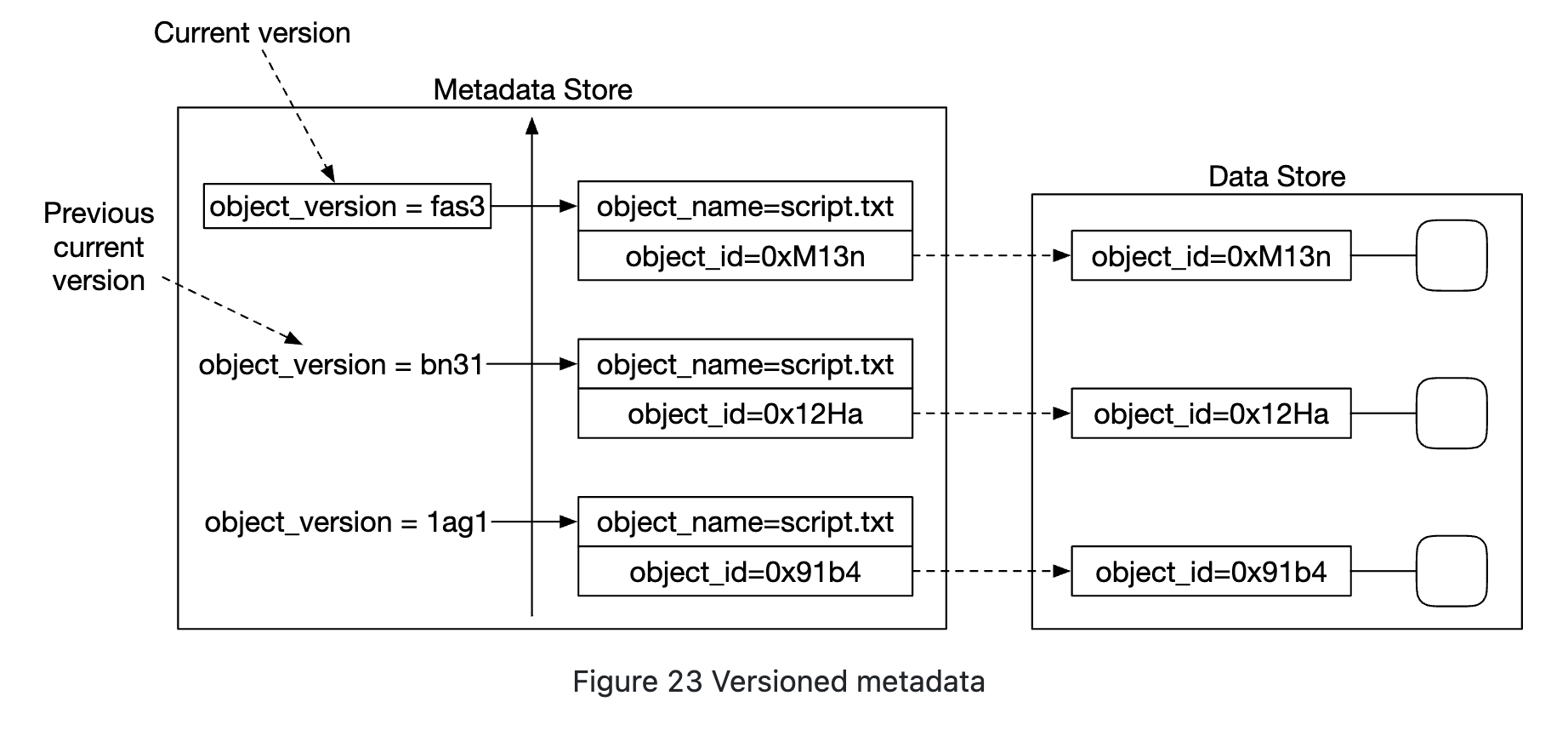
버전 기능을 지원하기 위해 메타데이터 저장소의 객체 테이블에는 object_version이라는 컬럼이 있고, 버전 기능이 활성화 되었을 경우에만 사용한다.
- 기존 레코드를 덮어쓰는 대신,
bucket_id,object_name은 같지만object_id,object_version은 새로운 값인 레코드를 추가한다.object_id: 새 객체의 UUIDobject_version: 새로운 레코드가 테이블에 추가될 때 만들어지는 TIMEUUID 값
메타데이터 저장소로 어떤 데이터베이스를 선택하건, 특정 객체의 현재 버전을 조회하는 연산은 효과적으로 처리될 수 있어야 한다.
객체 삭제
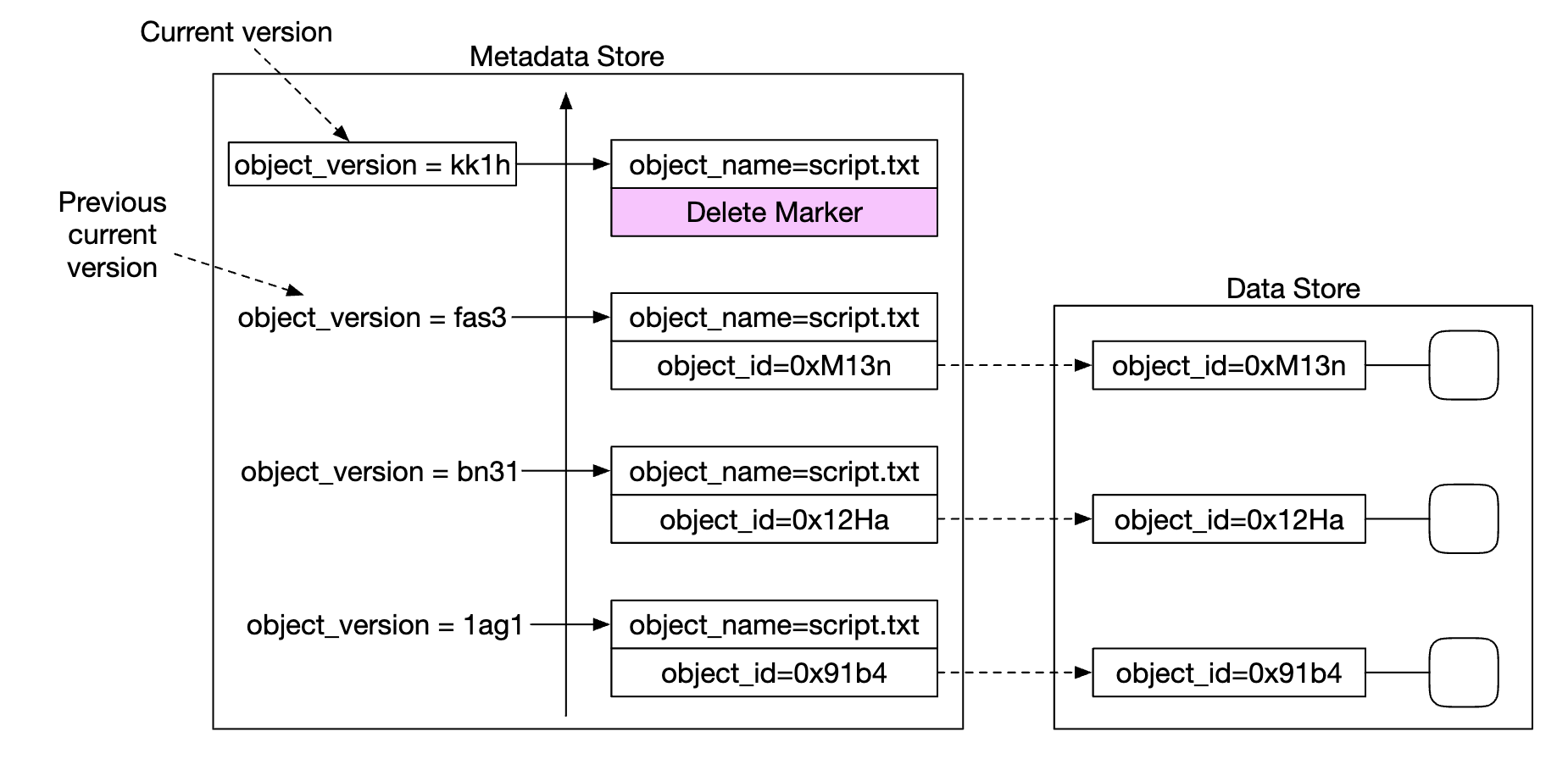
객체를 삭제할 때는 해당 객체의 모든 버전을 버킷 안에 그대로 둔 채 삭제 표식만 추가한다.
삭제 표식은 객체의 새로운 버전으로 삽입되는 순간 해당 객체의 새로운 현재 버전이 된다.
- 현재 버전 객체(삭제된 버전)를 가져오는
GET요청은 보내면404 Object Not Found오류가 반환된다.
큰 파일의 업로드 성능 최적화
큰 파일(몇 GB 이상)을벜닛에 직접 업로드하는 것도 가능은 하지만 시간이 매우 오래 걸릴 것이다.
업로드 중간 네트워크 문제가 생기면 다시 업로드 해야한다는 문제도 있다.
따라서 큰 객체는 작게 쪼갠 다음 독립적으로 업로드하는 것이 더 나은 방법이다.
멀티파트(multipart) 업로드
크기가 큰 대상을 쪼개 독립적으로 업로드한 후 모든 조각이 업로드되면 그 조각을 모아 원본을 복원하는 방법
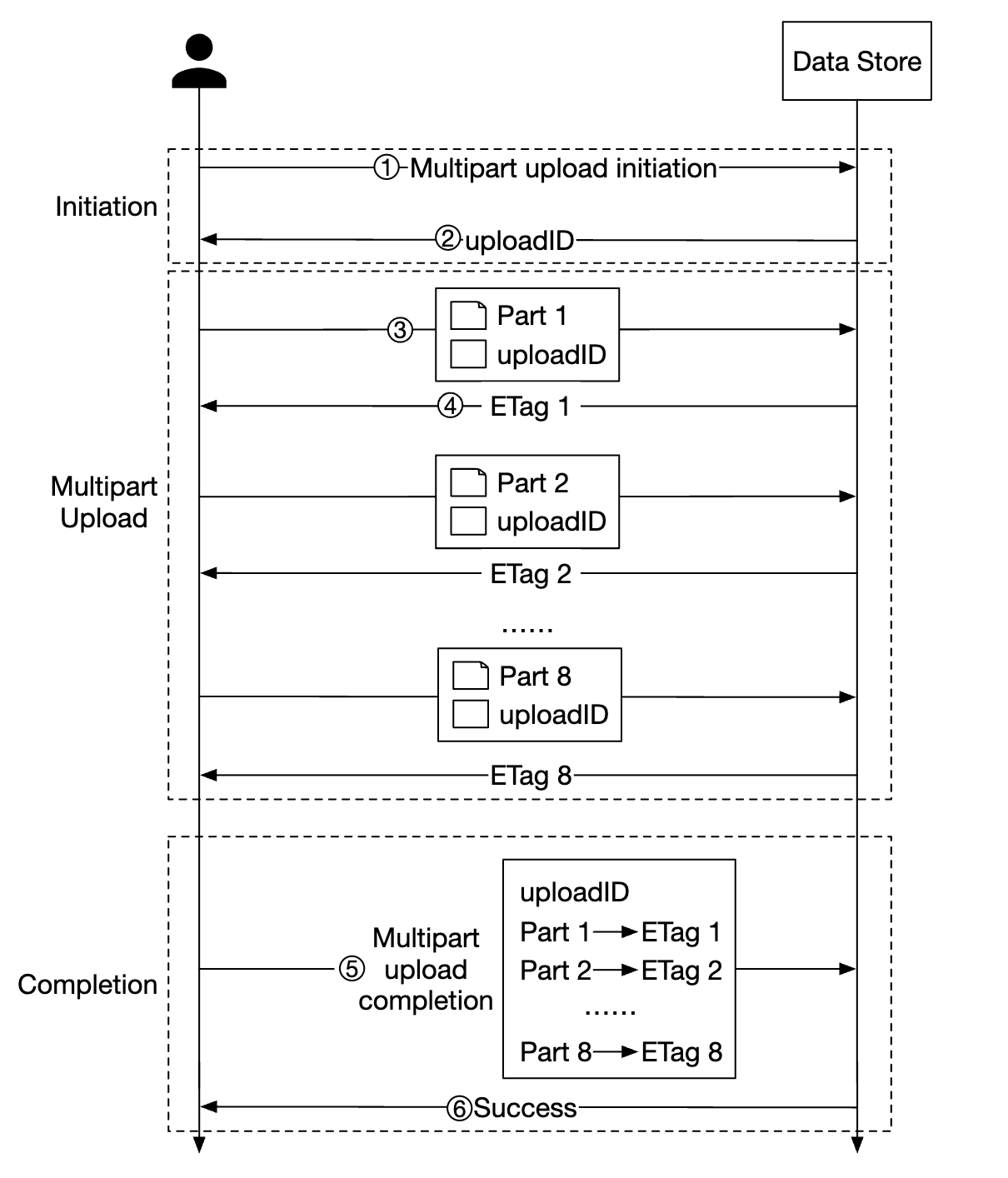
객체 조립이 끝난 뒤에는 조각들은 더이상 쓸모가 없어지므로 이러한 조각을 삭제하여 저장 용량을 확보하는 쓰레기 수집 프로세스를 구현할 필요가 있을 수 있다.
쓰레기 수집
쓰레기 수집(garbage collection)은 더 이상 사용되지 않는 데이터에 할당된 저장 공간을 자동으로 회수하는 절차이다.
본 시스템은 다음과 같은 경우 쓰레기 데이터가 생길 수 있다.
- 객체의 지연된 삭제(lazy object deletion)
- 삭제했다고 표시는 하지만 실제로 지우지는 않는다.
- 갈 곳 없는 데이터(orphaned data)
- 반쯤 업로드된 데이터, 또는 취소된 멀티 파트 업로드 데이터
- 훼손된 데이터(corrupted data)
- 체크섬 검사에 실패한 데이터
쓰레기 수집기는 객체를 데이터 저장소에 바로 지우지 않고 정리(compaction) 메커니즘을 주기적으로 실행하여 지운다.
쓰레기 수집기는 사용되지 않는 사본에 할당된 저장 공간을 회수하는 역할도 담당한다.
- 데이터를 다중화하는 경우 객체는 주 저장소 노드에서 뿐 아니라 부 저장소 노드에서도 지워야 한다.
- (8+2) 소거 코드를 사용하는 경우 12개 노드에서 전부 지워야한다.
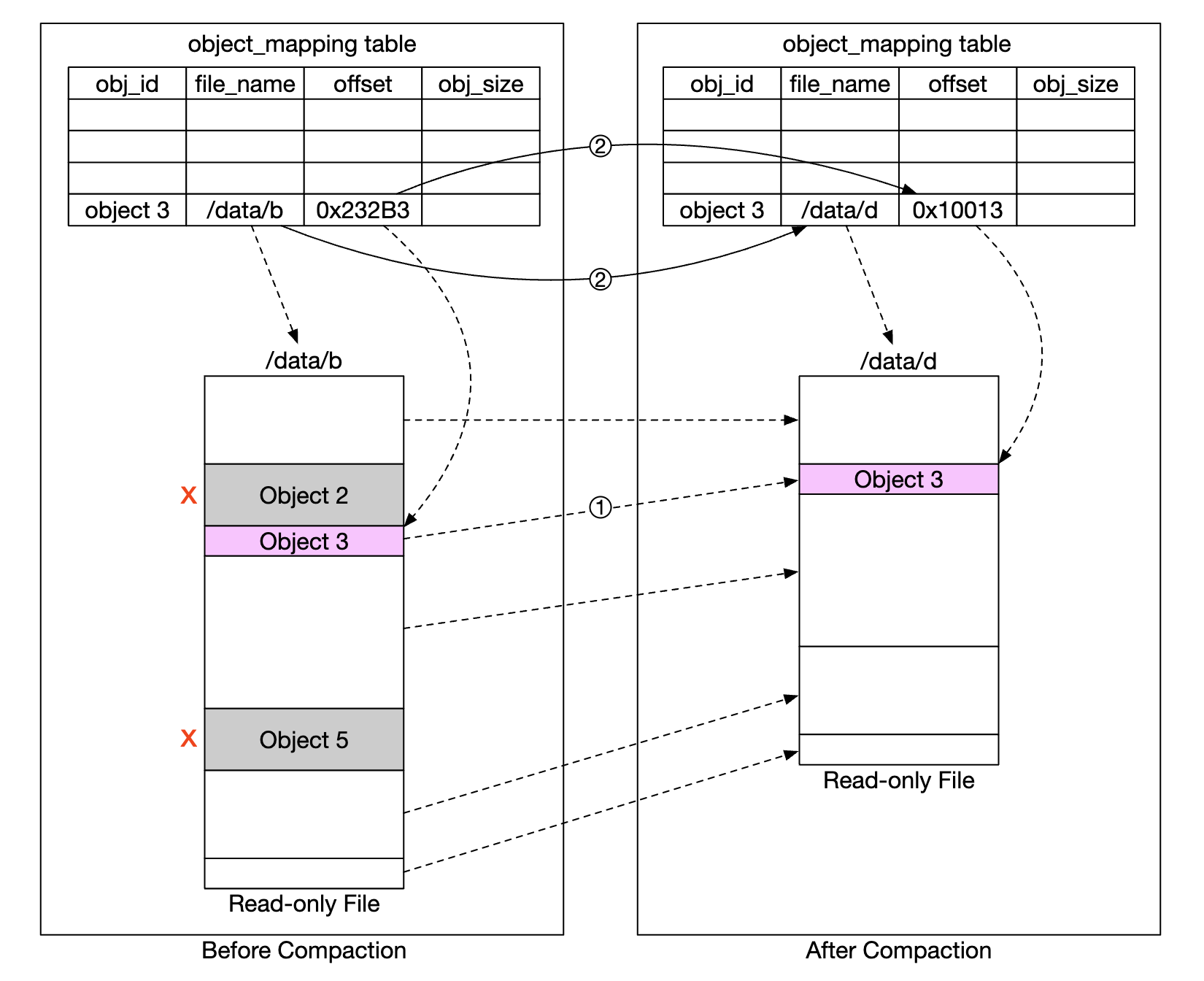
- 쓰레기 수집기는
/data/b의 객체를/data/d로 복사한다. - 모든 객체를 복사한 다음
object_mapping테이블을 갱신한다.- 객체 3의 경우
file_name과start_offset값은 새 위치를 가리키도록 수정된다. - 데이터 일관성을 위해 같은 트랜잭션 안에서 연산을 수행하는 것이 바람직하다.
- 객체 3의 경우
정리 후 새 파일의 크기는 종전보다 작다.
작은 파일을 많이 만들지 않기 위해 쓰레기 수집기는 보통 압출할 읽기 전용 파일이 많아질 때가지 기다리며, 압축을 진행하면서 여러 읽기 전용 파일에 기록된 객체를 하나의 파일로 모은다.
4단계: 마무리
- 블록 저장소, 파일 저장소, 객체 저장소의 차이
- 객체 업로드, 다운로드, 버킷 내 객체 목록 표시, 객체 버전 등의 기능의 구현
- 데이터 저장소와 메타데이터 저장소 구현
- 데이터 저장소에 어떻게 영속적으로 저장되는지
- 데이터 안정성과 내구성을 높이는 두 가지 방안(다중화, 소거 코드)
- 멀티파트 업로드
- 쓰레기 수집 장법