
이번 장에서는 지메일, 아웃룩 같은 대규모 이메일 서비스를 설계해본다.
1단계: 문제 이해 및 설계 범위 확정
현대적 이메일 서비스는 다양한 기능을 갖춘 복잡한 시스템으로 발전했다. 따라서 짧은시간에 설계는 불가능하므로 질문을 통해 설계 범위를 좁혀야한다.
인증- 이메일 발송/수신
- 모든 이메일 가져오기
- 읽음 여부에 따른 이메일 필터링
- 제목, 발신인, 메일 내용에 따른 검색 기능
- 스팸 및 바이러스 방지 기능
- 프로토콜
- SMTP, POP, IMAP 등과 같은 서비스 제공자 전용 프로토콜이 있으나 HTTP 사용한다고 가정
- 첨부파일 지원
비기능적 요구사항
- 안정성
- 이메일 데이터는 소실되어선 안된다.
- 가용성
- 이메일과 사용자 데이터를 여러 노드에 자동으로 복제하여 가용성을 보장해야한다.
- 부분적으로 장애가 발생해도 시스템은 계속 동작해야 한다.
- 확정성
- 사용자 수가 늘어나더라도 감당할 수 있어야 한다.
- 사용자나 이메일이 많아져도 시스템 성능은 저하되지 않아야 한다.
- 유연성과 확장성
- 새 컴포넌트를 더하여 쉽게 기능을 추가하고 성능을 개선할 수 있는 유연하고 확장성 높은 시스템이어야 한다.
- POP나 IMAP 같은 기존 이메일 프로토콜은 기능이 매우 제한적이므로, 요구사항을 만족하기 위해 맞춤형 프로토콜이 필요할 수 있다.
개략적인 규모 추정
- 10억 사용자
- 한 사람이 하루에 보내는 평균 이메일 수는 10건 가정
QPS = 10^9 * 10 / 10^5 = 100,000
- 한 사람이 하루에 수신하는 이메일 수는 평균 40건 가정
- 메일 하나의 메타데이터는 평균 50KB로 가정(첨부파일 X)
- 메타데이터는 데이터베이스에 저장한다고 가정
- 1년간 메타데이터를 유지하기 위한 스토리지 요구사항은
10억 사용자 * 하루 40건 * 365일 * 50KB = 730PB
- 1년간 메타데이터를 유지하기 위한 스토리지 요구사항은
- 첨부 파일을 포함하는 이메일의 비율은 20%, 평균 크기는 50KB 가정
- 1년간 첨부 파일을 보관하는 데 필요한 저장 용량은
10억 사용자 * 하루 40건 * 365 * 20% * 500KB = 1,460PB
- 1년간 첨부 파일을 보관하는 데 필요한 저장 용량은
많은 데이터를 처리해야하므로 분산 데이터베이스 솔루션이 필요하다.
2단계: 개략적 설계안 제시 및 동의 구하기
이메일 서버에 대해 알아야 할 기본적인 사항과 더불어 서버가 시간이 흐름에 따라 어떻게 진화하는지 논의한다.
그 후 분산 이메일 서버의 개략적인 설계안을 살펴본다.
이메일 101
이메일을 주고받는 프로토콜에는 대부분 POP, IMAP, SMTP 같은 프로토콜을 사용해왔다.
이메일 프로토콜
- SMTP(Simple Mail Transfer Protocol)
- 이메일을 한 서버에서 다른 서버로 보내는 표준 프로토콜
- POP(Post Office Protocol)
- 이메일을 가져오는 목적으로 널리 사용
- 이메일 클라이언트가 원격 메일 서버에서 이메일을 수신하고 다운로드하기 위해 사용하는 표준 프로토콜
- 단말로 다운로드된 이메일은 서버에서 삭제
- 결과적으로 한 대 단말에서만 이메일을 읽을 수 있음
- 이메일을 확인하기 위해 전부 내려받아야 함
- 용량이 큰 첨부 파일이 붙은 이메일은 읽으려면 시간이 오래걸림
- IMAP(Internet Mail Access Protocol)
- 이메일을 가져오는 목적으로 널리 사용
- POP과 달리 클리하지 않으면 메시지는 다운로드 되지 않으며, 메일 서버에서 지워지지도 않음
- 여러 단말에서 이메일을 읽을 수 있음
- 개인 이메일 계정에서 가장 널리 사용되는 프로토콜
- 이메일을 실제로 열기 전에는 헤더만 다운로드
- 인터넷 속도가 느려도 잘 동작함
- HTTPS
- 메일 전송 프로토콜은 아니지만 웹 기반 이메일 시스템의 메일함 접속에 이용될 수 있음
- ex) 아웃룩의 액티브 싱크
DNS - 도메인 이름 서비스
수신자 도메인의 메일 교환기 레코드(Mail Exchange, MX) 검색에 이용된다.
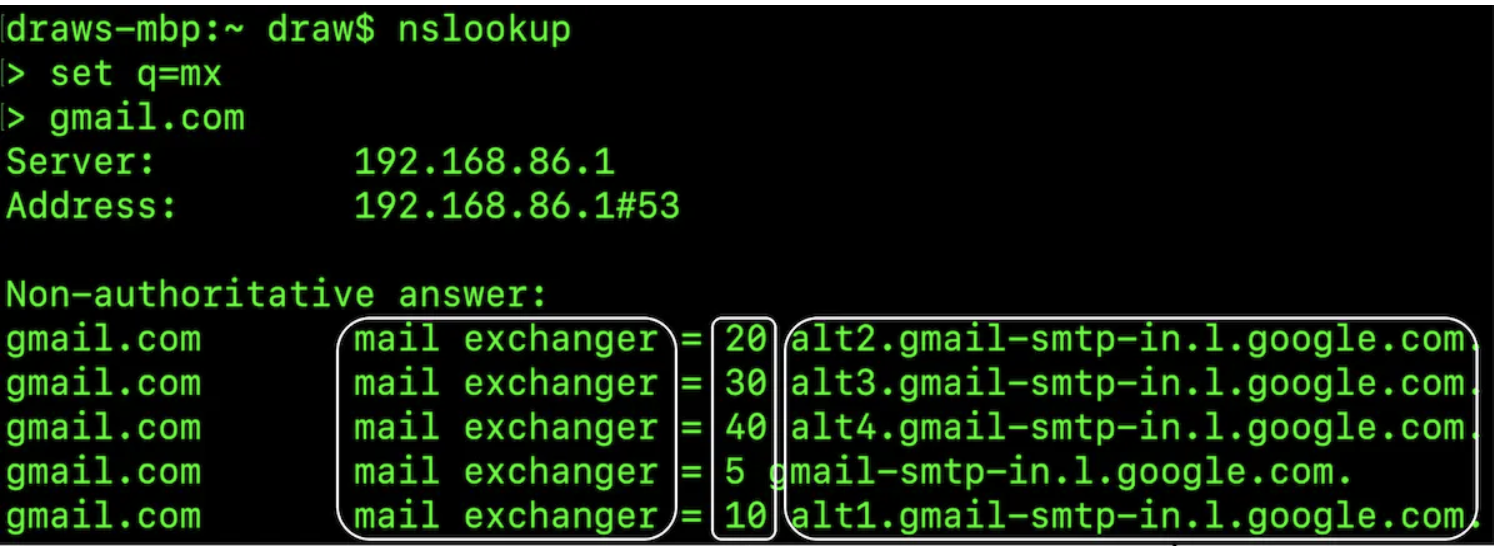
- 숫자는 우선순위 값으로 선호도를 나타내어 값이 낮으면 높은 우선순위로 처리됨
첨부 파일
첨부 파일은 이메일 메시지와 함께 전송되며 일반적으로 Base64 인코딩을 활용한다.
일반적으로 첨부 파일에는 크기 제한이 있고, 설정 가능한 수치로, 개인 계정이냐 기업 계정이냐에 따라 다르게 설정된다.(필요한 만큼 알아서 설정한다)
- 아웃룩 20MB, 지메일 25MB
MIME( Multi-purpose Internet Mail Extension)
인터넷을 통해 첨부 파일을 전송할 수 있도록 하는 표준 규격
전통적 메일 서버
분산 메일 서버에 알아보기 전 기존 메일 서버의 역사와 동작 방식에 대해 살펴본다.
전통적인 메일 서버는 보통 서버 한 대로 운용되는, 사용자가 많지 않을 때 잘 동작하는 시스템이다.
전통적 메일 서버 아키텍처
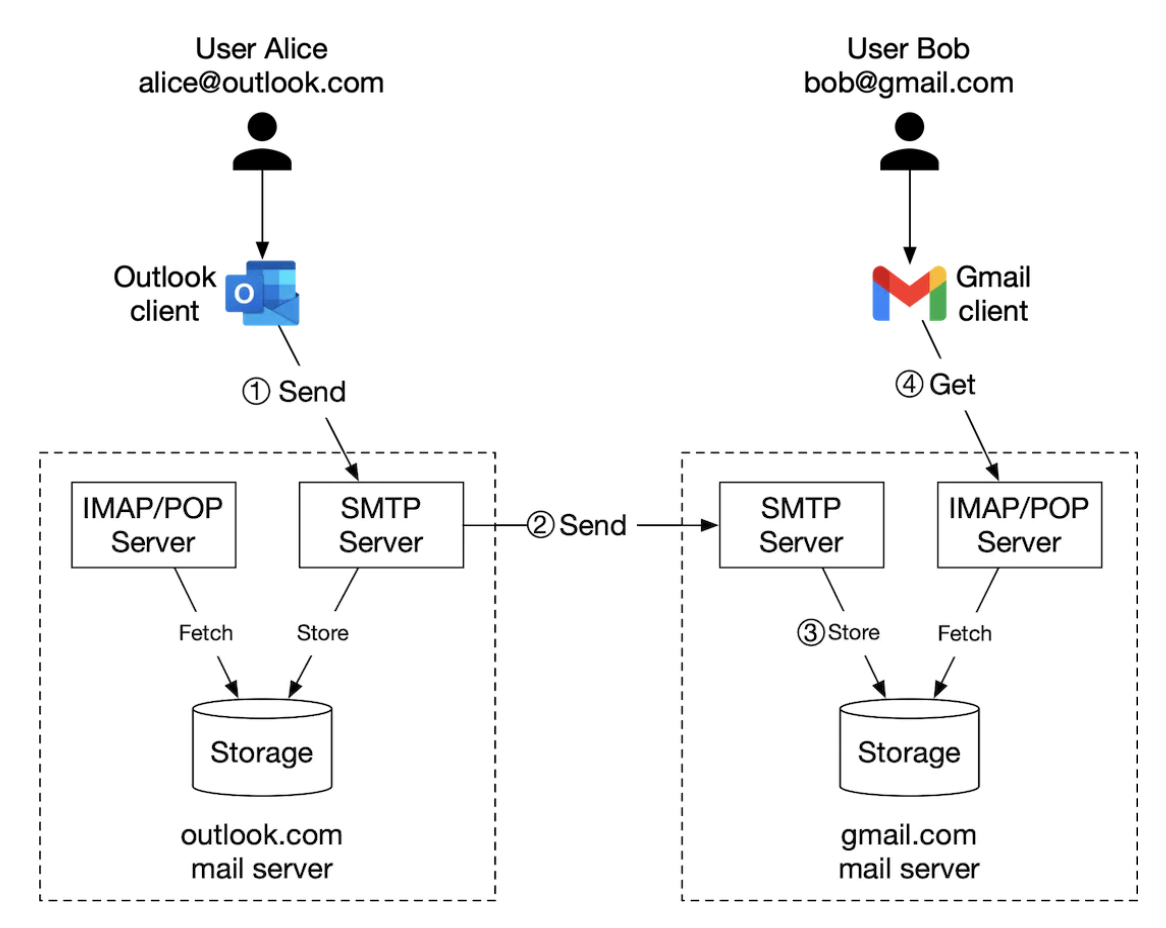
- 보내기 버튼을 누르면 메일 서버로 전송된다.(SMTP)
- 메일 서버는 DNS 질의를 통해 수신 SMTP 서버를 찾고 해당 서버로 이메일을 보낸다(SMTP)
- 메일을 수신한 서버는 이메일을 저장하고 수신자가 읽어갈 수 있도록 한다.
- 수신자가 로그인하면 IMAP/POP 서버를 통해 새 이메일을 가져온다.
저장소
전통적 메일 서버는 이메일을 파일 시스템의 디렉터리에 저장한다.
각각의 이메일은 고유한 이름을 가진 별도 파일로 보관도며, 각 사용자의 설정 데이터와 메일함은 사용자 디렉터리에 보관한다.
- 이러한 디렉터리 구조를 Maildir 이라고 함
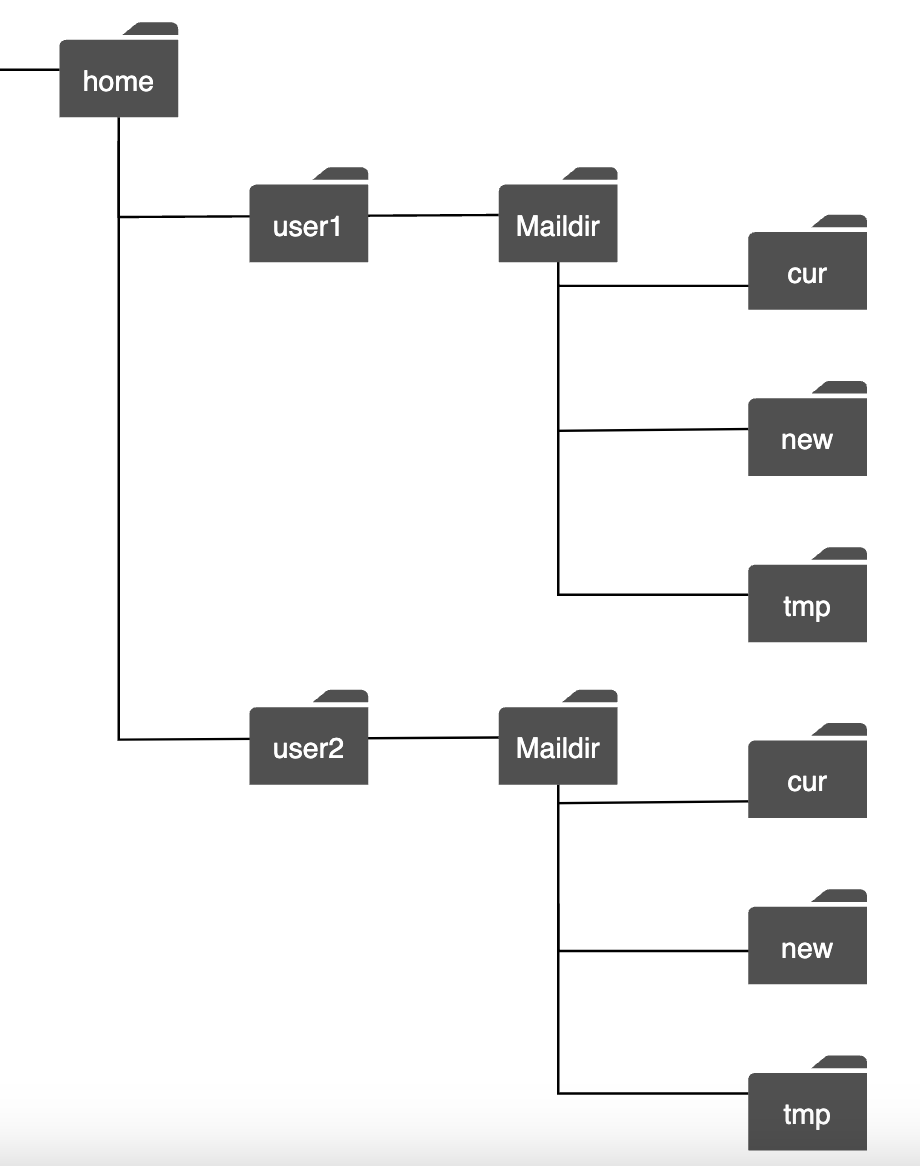
파일과 디렉터리를 활용하는 방안은 사용자가 많지 않을 때는 잘 동작하나 디스크 I/O로 인한 병목으로 인해 수십억 개의 이메일을 검색하고 백업하는 목적으로 활용하기에는 곤란했다.
그리고 이메일을 서버의 파일 시스템에 보관하였기 때문에 가용성과 안정성 요구사항도 만족할 수 없었기 때문에 더 안정적인 분산 데이터 저장소 계층이 필요했다.
- 디스크 손상, 서버 장애 등
이메일 기능은 1960년대에 발명된 이래로 텍스트 중심에서 멀티미디어, 메일 스레드, 검색, 레이블 등 다양한 기능을 지원하도록 발전해 왔지만, POP, IMAP, SMTP 같은 이메일 프로토콜은 이러한 기능을 지원하도록 설계되지 않았기 때문에 확장할 수 없었다.
분산 메일 서버
분산 메일 서버는 현대적 사용 패턴을 지원하고 확장성과 안정성 문제를 해결한다.
이메일 API
이메일 API의 의미는 메일 클라이언트, 이메일 생명주기 단계마다 달라질 수 있다.
- 모바일 단말 클라이언트를 위한 SMTP/POP/IMAP API
- 송신 측 메일 서버와 수신 측 메일 서버 간의 SMTP 통신
- 대화형 웹 기반 이메일 애플리케이션을 위한 HTTP 기반 RESTful API
이 책에서는 가장 중요한 API만 다루며, 웹메일 통신에는 일반적으로 HTTP 프로토콜이 쓰인다.
POST /v1/messages
To, Tc, Bcc 헤더에 명시된 수신자에게 메시지를 전송한다.
GET /v1/folders
주어진 이메일 계정에 존재하는 모든 폴더를 반환한다.
| |
GET /v1/folders/{:folder_id}/messages
주어진 폴더 아래의 모든 메시지를 반환한다.
- 단순화한 명세로 페이지네이션을 지원해야 하는 등 훨씬 복잡할 수 있다.
GET /v1/messages/{:message_id}
주어진 특정 메시지에 대한 모든 정보를 반환한다.
메시지는 이메일 애플리케이션의 핵심 구성 요소이다.
- 발신자, 수신자, 메시지 제목, 본문, 첨부 파일 등의 정보로 구성
분산 메일 서버 아키텍처
전통적인 이메일 서버가 단일 장비 위에서만 동작하도록 설계되었기 때문에 한 대 이상의 서버로 규모를 늘리는 것은 까다롭다.
- 여러 서버 사이에 데이터를 동기화하는 것은 어려운 작업이다.
- 수신자 메일 서버에서 이메일이 스팸으로 잘못 분류되지 않도록 하려면 까다로운 문제들을 풀어야한다.
이번 절에서는 클라우드 기술을 활용하여 이러한 문제를 쉽게 푸는 방법을 알아본다.
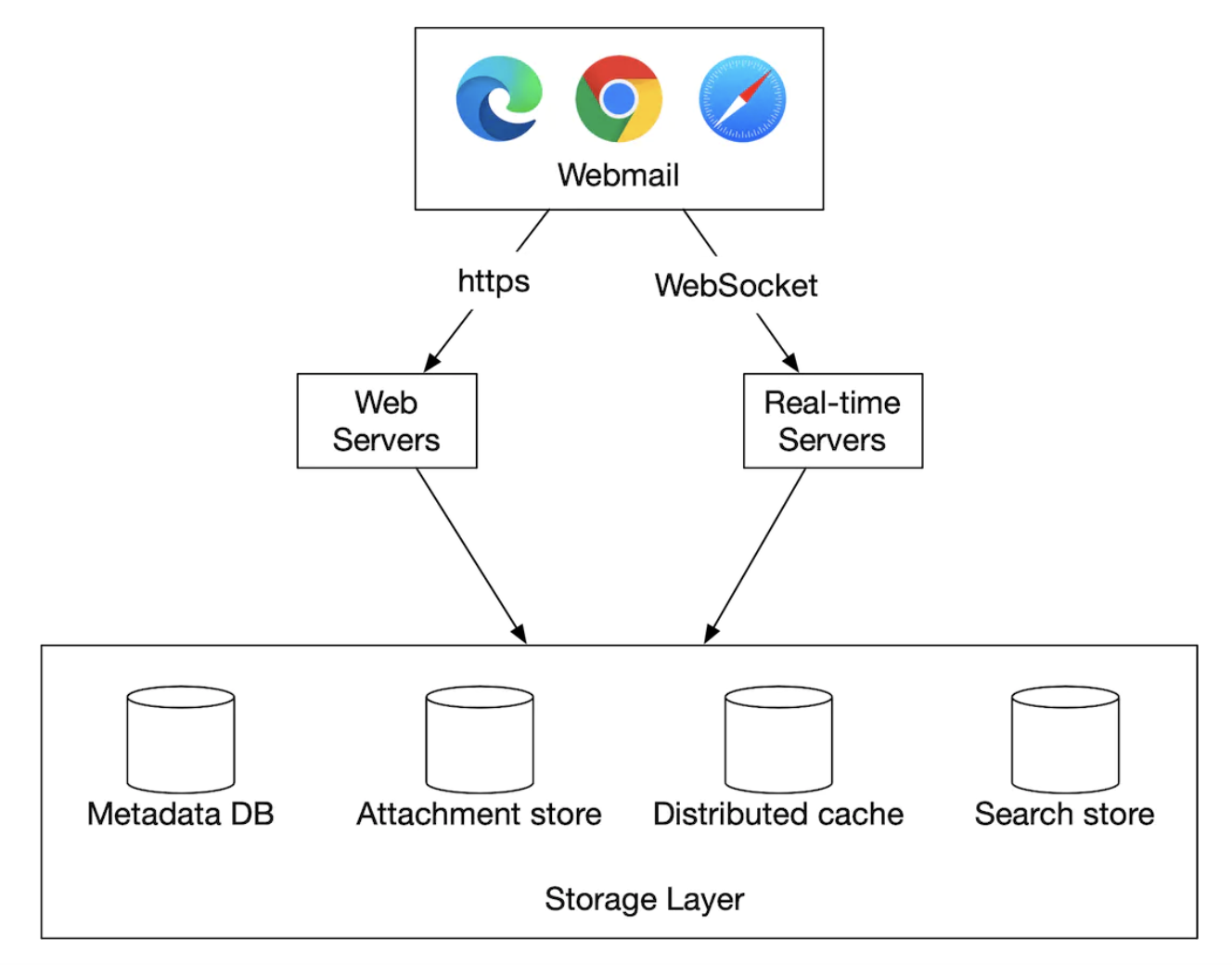
- 웹메일
- 사용자는 웹브라우저를 사용해 메일을 받고 보냄
- 웹서버
- 사용자가 이용하는 요청/응답 서비스로, 로그인, 가입, 사용자 프로파일 등에 대한 관리 기능을 담당
- 본 설계안에서는 이메일 발송, 폴더 목록 확인, 폴더 내 모든 메시지 확인 등
- 실시간 서버
- 새로운 이메일 내역을 클라이언트에 실시간으로 전달한다.
- 지속성 연결을 맺고 유지해야하므로 상태 유지 서버다.
- 롱폴링, 웹소켓 등
- 웹소켓이 좀 더 우아하지만 브라우저 호환성 문제가 있을 수 있다.
- 기본적으로는 웹 소켓을 쓰되 여의치 않으면 롱 폴링을 백업으로 이용할 수 있다.
- 메타데이터 데이터베이스
- 이메일 제목, 본문, 발신인, 수신인 목록 등 메타 데이터를 저장하는 데이터베이스
- 첨부 파일 저장소
- 아마존 S3(Simple Storage Service) 같은 객체 저장소를 사용할 것이다.
- 이미지나 동영상 등의 대용량 파일을 저장하는 데 적합하고 확장이 용이한 인프라이다.
- 첨부파일 크기는 25MB로 제한한다.
- 아마존 S3(Simple Storage Service) 같은 객체 저장소를 사용할 것이다.
- 분산 캐시
- 최근에 수신된 이메일은 자주 읽을 가능성이 높으므로 클라이언트로 하여금 메모리에 캐시해 두도록 하면 메일을 표시하는 시간을 많이 줄일 수 있다.
- 레디스
- 리스트와 같은 다양한 기능을 제공하고, 규모 확장이 용이하다.
- 검색 저장소
- 검색 저장소는 분산 문서 저장소이다.
- 고속 텍스트 검색을 지원하는 역 인덱스를 자료 구조로 사용한다.
카산드라가 첨부 파일 저장소로 적합하지 않은 이유
- 카산드라가 BLOB 자료형을 지원하고 해당 자료형이 지원하는 데이터의 최대 크기가 2GB이긴 하지만 실질적으로는 1MB 이상의 파일은 지원하지 못한다.
- 카산드라에 첨부 파일을 저장하면 첨부 파일이 너무 많은 메모리를 사용하게되어 레코드 캐시를 사용하기 어렵다.
이메일 전송 절차
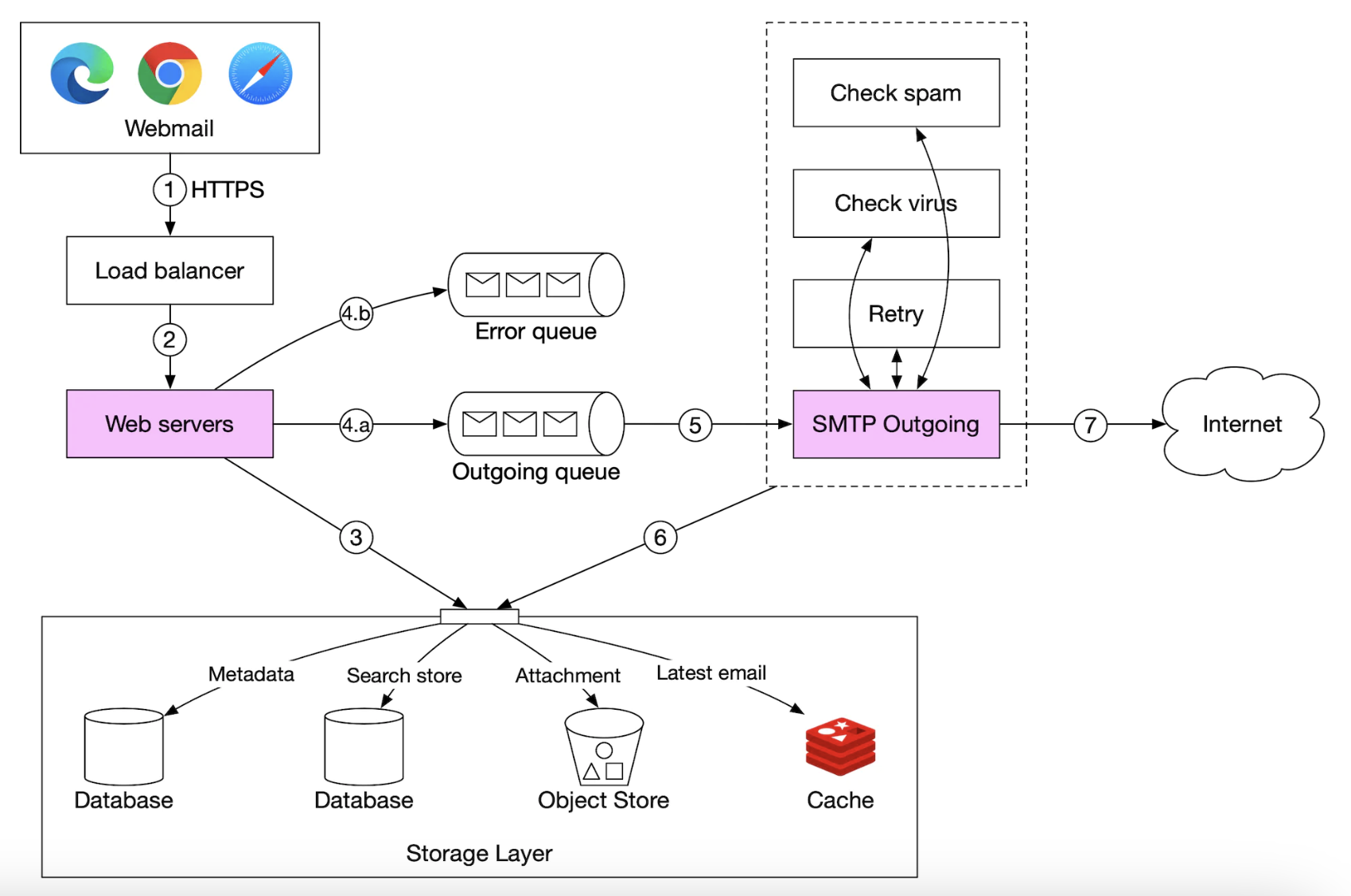
- 사용자가 웹에서 메일을 정송하면 요청은 로드밸런서로 전송된다.
- 로드벨런서가 처리율 제한 한도를 넘지 않는 선에서 요청을 웹 서버로 전달한다.
- 웹 서버는 다음 역할을 담당한다.
- 기본적인 이메일 검증
- 이메일 크기 한도 같은 사전 미리 정의된 규칙을 사용하여 수신된 이메일을 검사한다.
- 수신자 이메일 주소 도메인이 송신자 이메일 주소 도메인과 같은지 검사
- 이메일 내용의 스팸 여부와 바이러스 감염 여부를 검사
- 검사를 통과한 이메일은 송신인의 보낸 편지함과 수신인의 받은 편지함에 저장
- 수신인 측 클라이언트는 RESTful API를 사용하여 이메일을 바로 가져올 수 있어 4단계 이후는 수행할 필요가 없다.
- 기본적인 이메일 검증
- 메시지 큐
- 기본적인 검증을 통과한 이메일은 외부 전송 큐로 전달된다.
- 첨부 파일의 크기가 너무 큰 이메일의 경우 첨부 파일을 객체 저장소에 따로 저장하고 해당 저장 위치에 대한 참조 정보만 저장한다.
- 기본적인 검증에 실패한 이메일은 에러 큐에 보관한다.
- 기본적인 검증을 통과한 이메일은 외부 전송 큐로 전달된다.
- 외부 전송 담당 SMTP 작엄 프로세스는 외부 전송 큐에서 메시지를 꺼내어 이메일의 스팸 및 바이러스 감염 여부를 확인한다.
- 검증 절차를 통과한 이메일은 저장소 계층 내의 보낸 편지함에 저장된다.
- 외부 전송 담당 SMTP 작업 프로세스가 수신자의 메일 서버로 메일을 전송한다.
외부 전송 큐에 보관되는 모든 메시지에는 이메일을 생성하는 데 필요한 모든 메타데이터가 포함되어 있다.
분산 메시지 큐는 비동기적 메일 처리를 가능케 하는 핵심적 컴포넌트이다.
- 웹 서버에서 외부 전송 담당 SMTP 프로세스를 분리함으로 전송용 SMTP 프로세스의 규모를 독립적으로 조정할 수 있게 된다.
외부 전송 큐의 크기를 모니터링 할 때 메일이 처리되지 않고 큐에 오랫동안 남아 있으면 그 이유를 분석해야한다.
- 수신자 측 메일 서버에 장애 발생
- 나중에 메일을 다시 전송해야 한다.
- ex) 지수적 백오프(Exponential Backoff)
- 이메일을 보낼 큐의 소비자 수가 불충분
- 더 많은 소비자를 추가하여 처리 시간을 단축하는 방법을 생각해 볼 수 있다.
이메일 수신 절차
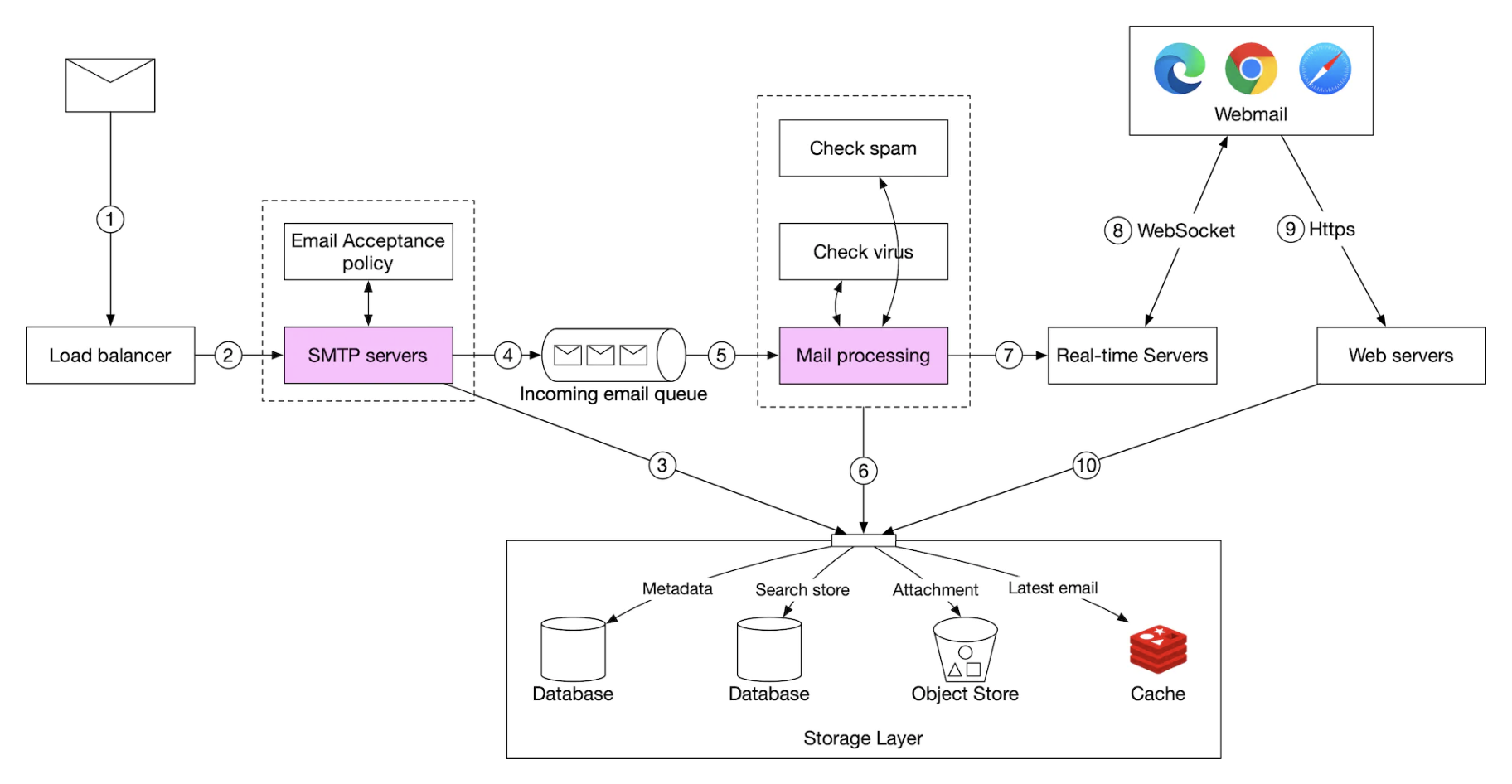
- 이메일이 SMTP 로드밸런서에 도착
- 트래픽을 여러 SMTP 서버로 분산
- SMTP 연결에는 이메일 수락 정책을 구성하여 적용 가능
- 유효하지 않은 이메일은 방송하도록 하여 불필요한 이메일 처리를 피할 수 있음
- 이메일의 첨부 파일이 큐에 들어가기 너무 큰 경우 첨부 파일 저장소(S3)에 보관
- 이메일을 수신 이메일 큐에 넣는다
- 메일 처리 작업 프로세스와 SMTP 간 결합도를 낮추어 각자 독립적으로 규모 확장이 가능하도록 함
- 수신 이메일이 폭증하는 경우 버퍼 역할도 하게됨
- 메일 처리 작업 프로세스(worker)는 스팸 메일을 걸러내고 바이러스를 차단하는 등의 다양한 역할 담당
- 이후 처리는 검증 작업이 끝난 이메일을 대상으로 처리
- 이메일을 메일 저장소, 캐시, 객체 저장소 등에 보관
- 수신자가 온라인 상태일 경우 실시간 서버로 전달
- 실시간 서버는 수신자 클라이언트가 새 이메일을 실시간으로 받을 수 있도록 하는 웹소켓 서버
- 오프라인 상태 사용자의 이메일은 저장소 계층에 보관
- 온라인 상태가 되면 클라이언트가 웹 서버에 RESTful API를 통해 열결됨
- 새로운 이메일을 저장소 계층에서 가져와 클라이언트에 반환
3단계: 상세 설계
몇 가지 핵심 요소에 대해 더 자세히 알아보고 규모 확장 방안을 점검한다.
메타데이터 데이터베이스
이메일 메타데이터의 특성을 알아보고 올바른 데이터베이스와 데이터 모델을 고르는 문제, 이메일 스레드 지원 방안에 대해 알아본다.
이메일 메타데이터의 특성
- 이메일의 헤더는 일반적으로 작고, 빈번하게 이용
- 이메일 본문의 크기는 다양하지만 사용 빈도는 낮음
- 일반적으로 한 번만 읽음
- 이메일 가져오기, 읽은 메일로 표시, 검색 등의 이메일 관련 작업은 사용자 별로 격리 수행되어야함
- 어떤 사용자의 이메일은 해당 사용자만 읽을 수 있어야함
- 이메일에 대한 작업도 그 사용자만이 수행할 수 있어야함
- 데이터 신선도는 데이터 사용 패턴에 영향을 미침
- 사용자는 보통 최근 메일만 읽음
- 만들어진 지 16일 이하에 발생하는 읽기 질의 비율은 전체 질의의 82%에 달함
- 데이터의 높은 안정성이 보장되어야 함
- 데이터 손실은 용납되지 않음
올바른 데이터베이스의 선정
지메일이나 아웃룩 정도의 규모가 되면 시스템의 부하로 인해, 초당 입/출력 연산 빈도(Input/Output Operations Per Second, IOPS)를 낮추기 위한 맞춤 제장 데이터베이스를 사용한다.
올바른 데이터베이스 선택은 쉽지 않은데, 가능한 모든 선택지를 미리 살펴보면 도움이 된다.
관계형 데이터베이스
관계형 데이터베이스를 고르는 주된 동기는 이메일을 효율적으로 검색할 수 있다는 장점 때문이다.
- 이메일 헤더와 본문에 대한 인덱스를 만들면 효율적으로 검색할 수 있다.
하지만 관계형 데이터베이스는 데이터 크기가 작을 때 적합하다.
- 이메일은 수 KB보다 크고 HTML이 포함되면 쉽게 100KB를 넘어간다.
- BLOB 자료형을 쓰면 큰 이메일도 처리할 수 있으나, 비정형 BLOB에 대한 검색 질의 성능은 좋지 않다.
- BLOB이 고정된 크기 페이지를 연결하여 큰 데이터를 저장하도록 하고 있어 해당 컬럼의 데이터를 접근할 때마다 많은 디스크 I/O가 발생한다
따라서 관계형 데이터베이스는 바람직하지 않다.
분산 객체 저장소
이메일의 원시 데이터를 그대로 아마존 S3 같은 객체 저장소에 보관하는 방법도 고려할 수 있다.
하지만 객체 저장소는 백업 데이터를 보관하기에는 좋지만 이메일의 읽음 표시, 키워드 검색, 이메일 스레드 드의 기능을 구현하기에 그다지 좋지 않다.
NoSQL 데이터베이스
지메일은 구글 빅테이블을 저장소로 사용하는데 충분히 실현 가능한 방안이다.
하지만 빅테이블은 오픈소스로 공개되어 있지 않고 이메일 검색을 빅테이블 위에서 어떻게 구현했는지는 공개되어있지않다.
카산드라가 좋은 대안이 될 수도 있지만 대형 이메일 서비스 제공 업체 가운데 카산드라를 사용하는 곳은 아직 확인된 바가 없다.
위 후보들을 봤을 때 본 설계안이 필요로 하는 기능을 완벽히 지원하는 데이터베이스는 없다고 봐도 좋을 것 같다.
이러한 이유로 대형 이메일 서버스 업체는 대체로 독자적인 데이터베이스 시스템을 만들어 사용한다.
이러한 데이터베이스를 설계하기엔 시간이 부족하므로, 해당 데이터베이스가 아래와 같은 조건을 충족해야 한다는 점을 설명할 수 있어야한다.
- 어떤 단일 컬럼의 크기는 한 자리수의 MB 정도일 수 있다.
- 강력한 데이터 일관성이 보장되어야 한다.
- 디스크 I/O가 최소화되도록 설계되어야 한다.
- 가용성이 아주 높아야 하고 일부 장애를 감내할 수 있어야 한다.
- 증분 백업(incremental backup)이 쉬워야 한다.
데이터 모델
데이터를 저장하는 한 가지 방법은 user_id를 파티션 키로 사용하여 특정한 사용자의 데이터는 항상 같은 샤드에 보관하는 것이다.
- 메시지를 여러 사용자와 공유할 수 없지만 요구사항과는 관계 없다.
기본 키는 파티션 키(partition key)와 클러스터 키(clustering key)의 두 가지 부분으로 구성된다.
- 파티션 키
- 데이터를 여러 노드에 분산하는 기준
- 데이터가 모든 노드에 균등하게 분산되도록 하는 파티션 키를 골라야함
- 클러스터 키
- 파티션에 속한 데이터를 정렬하는 기준
개략적으로 이메일 서비스의 데이터 계층은 다음과 같은 질의를 지원해야 한다.
- 주어진 사용자의 모든 폴더를 구한다.
- 특정 폴더 내의 모든 이메일을 표시한다.
- 메일을 생성, 삭제, 조회한다.
- 읽은 메일 전부, 또는 읽지 않은 메일 전부를 가져온다.
- 이메일 스레드를 전부 가져온다.

질의 1: 특정 사용자의 모든 폴더 질의
파티션 키는 user_id다. 따라서 어떤 사용자의 모든 폴더는 같은 파티션 안에 있다.
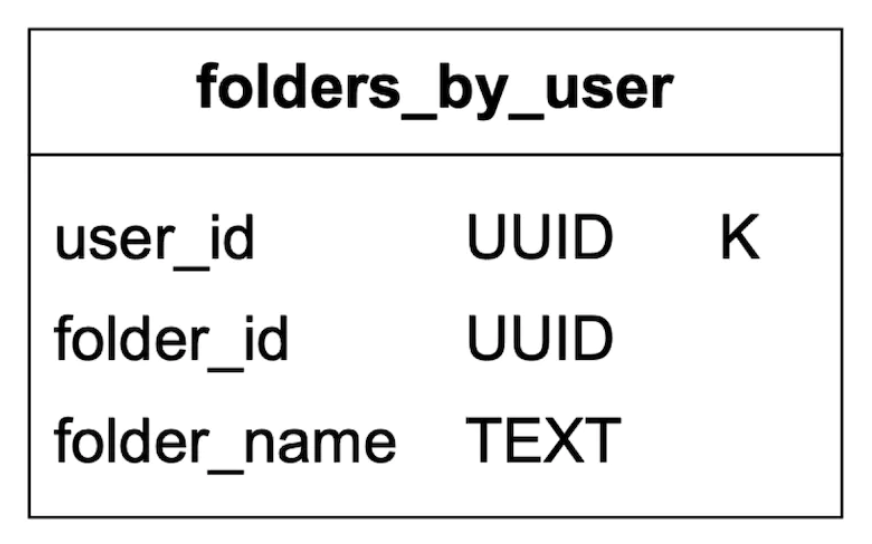
질의 2: 특정 폴더에 속한 모든 이메일 표시
사용자가 자기 메일 폴더를 열면 이메일은 가장 최근 이메일부터 오래된 것 순으로 정렬되어 표시된다.
같은 폴더에 속한 모든 이메일이 같은 파티션에 속하도록 하려면 <user_id, foler_id> 형태의 복합 파티션 키를 사용해야 한다.

email_id의 자료형은 TIMEUUID로 이메일을 시간순으로 정렬하는 데 사용되는 클러스터 키다.
질의 3: 이메일 생성/삭제/수신
이메일 상세 정로를 가져오는 방법을 살펴본다.
| |
이 질의를 지원하기 위해 두 테이블이 필요하다.
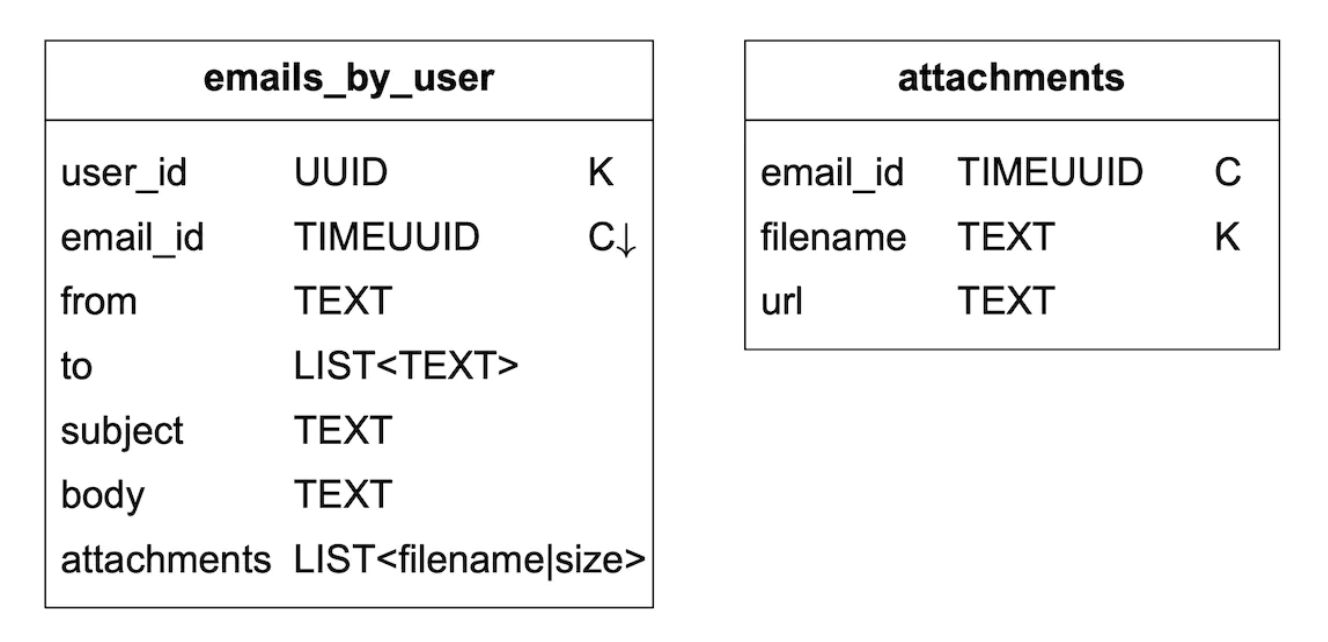
한 이메일에는 여러 첨부 파일이 있을 수 있으므로, email_id, filename 필드를 같이 사용하면 모든 첨부 파일을 질의할 수 있다.
질의 4: 읽은, 또는 읽지 않은 모든 메일
관계형 데이터베이스로 도메인 모델을 구현하는 경우, 읽은 메일 전부는 다음과 같이 질의할 수 있다.
| |
본 설계안의 데이터모델은 NoSQL로 보통 파티션 키와 클러스터 키에 대한 질의만 허용하므로 emails_by_folder 테이블의 is_read 필드는 이에 해당하지 않기 때문에 대부분의 NoSQL 데이터베이스에서는 위 쿼리를 실행할 수 없다.
이 문제를 해결하기 위한 방법으로 주어진 폴더에 속한 모든 메시지를 가져온 다음 애플리케이션 단에서 필터링 해줄 수 있다.
- 대규모 서비스에는 적합하지 않다.
따라서 이런 문데는 NoSQL 데이터베이스 테이블을 비정규화(denormalization)하여 해결하는 것이 보통이다.
emails_by_folder테이블을 두 테이블로 분할한다.read_emails: 읽은 상태의 모든 이메일을 보관unread_eamils: 읽지 않은 모든 이메일을 보관
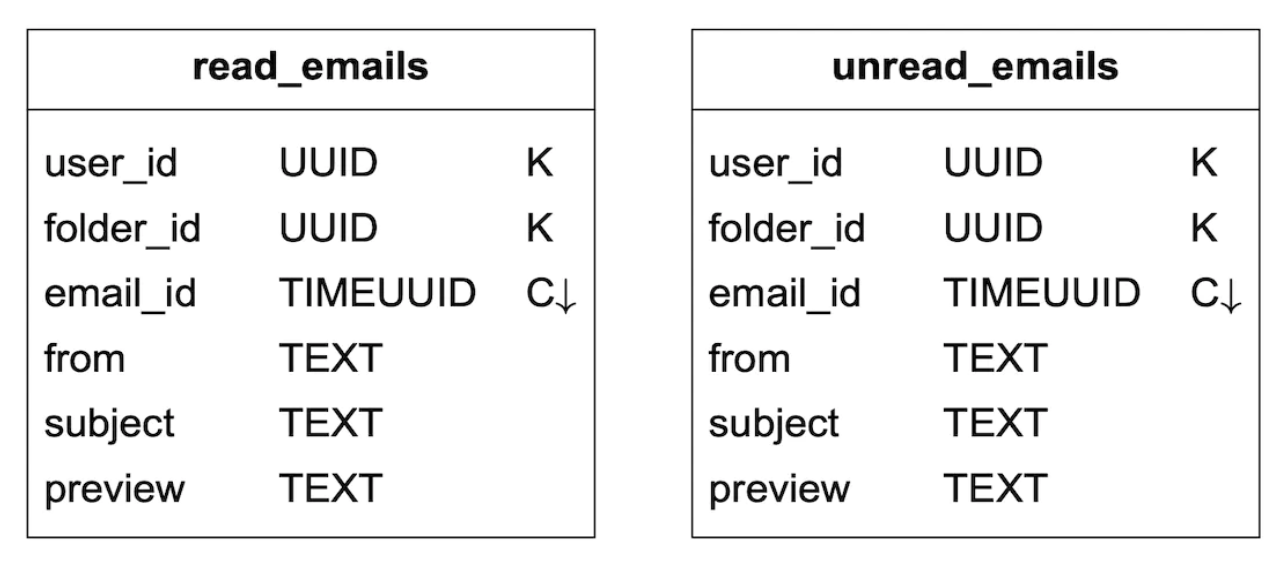
특정 폴더 안의 읽지 않은 모든 메일을 가져오는 질의는 다음과 같이 표현될 수 있다.
| |
이러한 비정규화는 흔한 관행으로, 애플리케이션 코드가 좀 더 복잡해지고 관리하기 까다로워지지만, 질의 성능은 대규모 서비스에 어울리는 수준으로 개선한다.
보너스: 이메일 스레드 가져오기
이메일 스레드는 많은 이메일 클라이언트가 지원하는 기능으로 모든 답장을 최초 메시지에 스레드로 엮어 보여주는 기능이다.
사용자가 특정한 대화에 관련된 모든 메일을 한 번에 확인할 수 있게된다.
- 전통적으로 JWZ 같은 알고리즘을 통해 구현한다.
| |
- Message-Id
- 메시지 식별자
- 메시지를 보내는 클라이언트가 생성
- In-Reply-To
- 어떤 메시지가 어떤 메시지에 대한 답신인지 나타내는 식별자
- References
- 스레드에 관계된 메시지 식별자 목록
이 필드들로 이메일 클라이언트는 타래 내의 모든 메시지가 사전에 메모리에 로드되어 있는 경우 전체 대화 스레드를 재구성해 낼 수 있게된다.
일관성 문제
높은 가용성을 달성하기 위해 다중화에 의존하는 분산 데이터베이스는 데이터 일관성과 가용성 사이에서 타협적인 결정을 내릴 수 밖에 없다.
이메일 시스템의 경우 데이터의 정확성이 아주 중요하므로, 모든 메일함은 반드시 하나의ㅏ 주 사본을 통해 서비스된다고 가정해야한다.
따라서 장애가 발생하면 클라이언트는 다른 사본을 통해 주 사본이 복원될 때까지 동기화/갱신 작업을 완료할 수 없다.
- 일관성을 위해 가용성을 희생한다.
이메일 전송 가능성
메일 서버를 구성하고 이메일을 보내는 것은 쉽지만 특정 사용자의 메일함에 실제로 메일이 전달되도록 하는 것은 어려운 문제이다.
이메일이 스팸 폴더에 들어가 버리면 수신자가 메일을 읽을 가능성은 아주 낮아진다.
- 연구에 따르면 메일 가운데 50%가 그팸으로 분류된다.
새로 구성한 메일 서버는 인터넷에서 좋은 평판을 쌓을 기회가 전혀 없었기 때문에 보내는 메일이 대부분 스팸 폴더로 떨어진다.
따라서 이메일의 전송 가능성을 높이기 이ㅜ해서 다음과 같은 요소들을 고려한다.
- 전용 IP
- 전용 IP 주소를 사용하라
- 대부분의 이메일 서비스 사업자는 아무 이력이 없는 IP 새로운 IP 주소에서 온 메일을 무시한다.
- 범주화
- 범주가 다른 이메일은 다른 IP 주소를 통해 보내라
- 마케팅 목적의 메일을 중요한 이메일과 같은 서버에서 발송하면 ISP가 모든 이메일을 판촉 메일로 분류할 수도 있다.
- 발신인 평판
- 새로운 이메일 서버의 IP 주소는 사용 빈도를 서서히 올리는 것이 좋다.
- 그래야 좋은 평판이 쌓여 해당 IP 주소에서 발송되는 메일을 스팸으로 분류할 가능성이 낮아진다.
- 아마존 SES에 따르면 새로운 IP 주소를 메일 발송해 아무 문제 없이 쓸 수 있게 되는 데는 대략 2 ~ 6주가 소요된다.
- 스팸 발송자의 신속한 차단
- 스팸을 뿌리는 사용자는 서버 평판을 심각하게 훼손하기 전에 시스템에서 신속히 차단한다.
- 피드백 처리
- 불만 신고가 접수되는 비율을 낮추고 스팸 계정을 신속히 차단하기위해서는 ISP 측에서의 피드백을 쉽게 받아 처리할 수 있는 경로를 만드는 것이 중요하다.
- 이메일이 전달되지 못하거나 사용자로부터 불만 신고가 접수된 경우 다음과 같은 일들이 벌어질 수 있다.
- 경성 반송(hard bounce)
- 수신인의 이메일 주소가 올바르지 않아 ISP가 전달을 거부한 경우
- 연성 반송(soft bounce)
- ISP 측의 이메일 처리 자원 부족 등의 이유로 일시적으로 이메일을 전달할 수 없었던 경우
- 불만 신고(complaint)
- 수신인이 스팸으로 신고 버튼을 누르는 경우
- 경성 반송(hard bounce)
- 이메일 인증
- 2018년도 데이터 유출 조사 보고서에 따르면 ㅍ피싱이나 프리텍스팅이 전체 유철 사고에서 차지하는 비중은 93%에 달한다.
- 보편적으로 SPF(Sender Policy Framework), DKIM(DomainKeys Identified Mail), DMARC(Domain-based Message Authentication, Reporting and Conformance) 등으로 피싱에 대응한다.
명심해야할 점은 이메일이 목적지에 성공적으로 도착하도록 하기 어렵다는 사실이다. 도메인 지식은 물론 ISP와 좋은 관계를 유지할 필요도 있다.
검색
기본적인 이메일 검색은 보통 이메일 제목이나 본문에 특정 키워드가 포함되었는지 찾는 것을 뜻하며, 고급 기능에는 발신인, 제목, 읽지 않음 같이 메일 속성에 따른 필터링 기능이 포함된다.
검색 기능을 제공하려면 이메일이 전송, 수신, 삭제 될 때마다 색인(indexing) 작업을 수행해야 한다.
그에 반해 검색은 사용자가 검색 버튼을 누를 때만 실행되므로, 이메일 시스템의 검색 기능에서는 쓰기 연산이 읽기 연산보다 훨씬 많이 발생한다.
검색 기능을 지원하기 위해 일래스틱서치(ElasticSearch)를 이용하는 방안과 데이터 저장소에 내장된 기본 검색 기능을 활용하는 방안의 두 가지 선택지를 비교해본다.
방안 1: 일래스틱서치
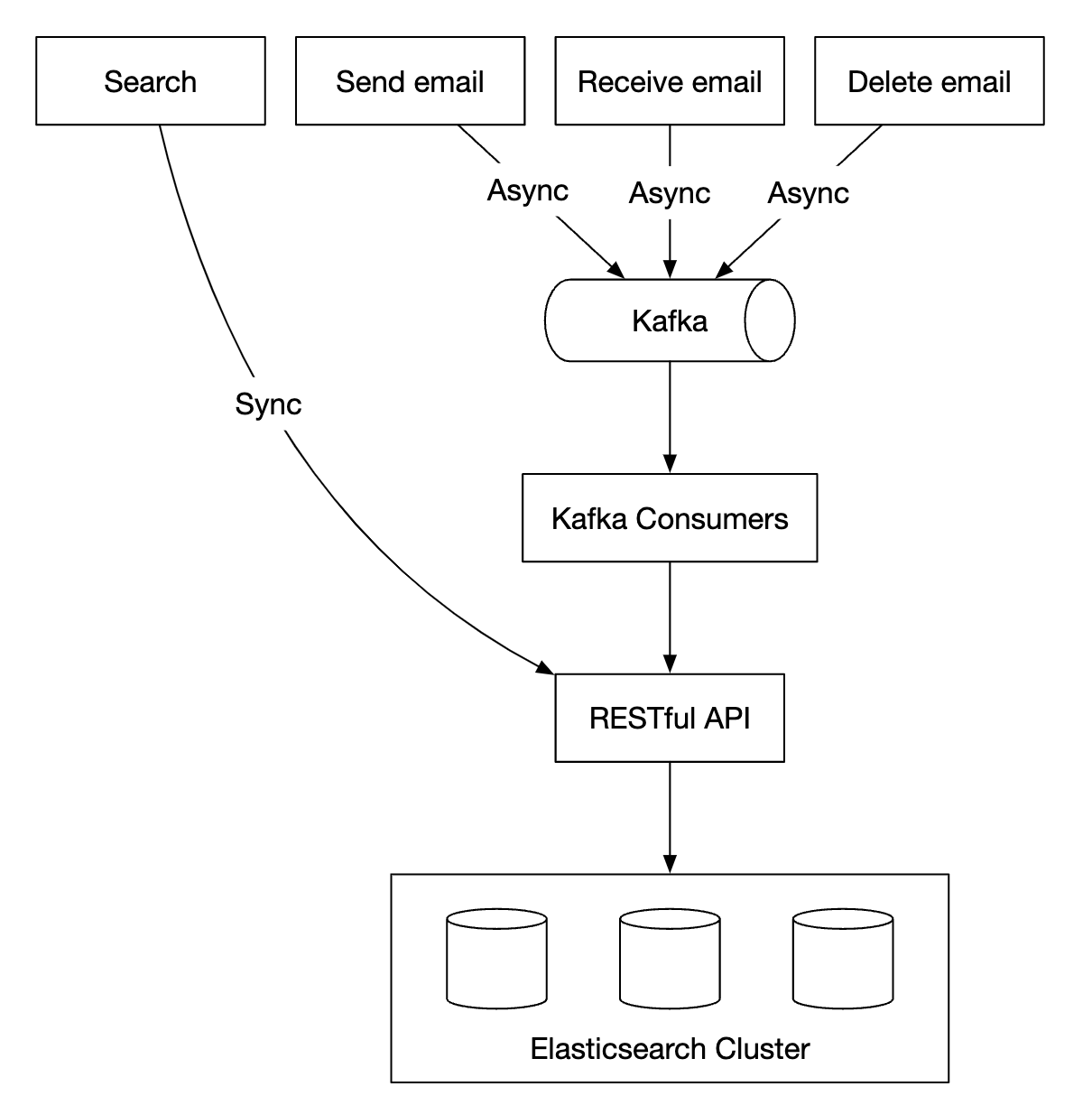
질의가 대부분 사용자의 이메일 서버에서 실행되므로 user_id를 파티션 키로 사용하여 같은 사용자의 이메일은 같은 노드에 묶어 놓는다.
- 사용자가 검색 버튼을 누른 다음 결과가 수신될 때 까지 기다리므로, 검색 요청은 동기 방식으로 처리되어야 한다.
- 이메일 전송, 이메일 수신, 이메일 삭제 같은 이벤트는 처리 결과를 클라이언트로 전달할 필요는 없으며, 추가로 색인 작업이 필요하다.
본 설계안은 카프카를 활용하여 색인 작업을 시작하는 서비스와 실제로 색인을 수행할 서비스 사이의 결합도를 낮추는 방안을 채택한다.
- 일래스틱서치는 2021년 6월 기준으로 가장 널리 사용되고 있는 검색 엔진 데이터베이스이며 이메일 검색에 필요한 텍스트 기반 검색을 잘 지원한다.
일래스틱서치를 사용할 경우 주 이메일 저장소와 동기화를 맞추는 부분이 까다롭다.
방안 2: 맞춤형 검색 솔루션
대규모 이메일 서비스 사업자는 보통 자기 제품에 고유한 요구사항을 만족시키기 위해 검색 엔진을 자체적으로 개발해 사용한다.
매우 어렵고 범위를 넘어서기 때문에 자체적으로 검색 솔루션을 구현하는 경우 마주하게 될 주요 과제인 디스크 I/O 병목 문제를 살펴본다.
개략적 규모 추정 결과 메타 데이터와 첨부 파일은 매일 페타바이트 수준으로 저장소에 추가되며, 하나의 이메일 계정에 몇십 만개 넘는 이메일이 저장되는 것도 흔하다.
- 따라서 메일 색인 서버의 주된 병복은 보통 디스크 I/O다.
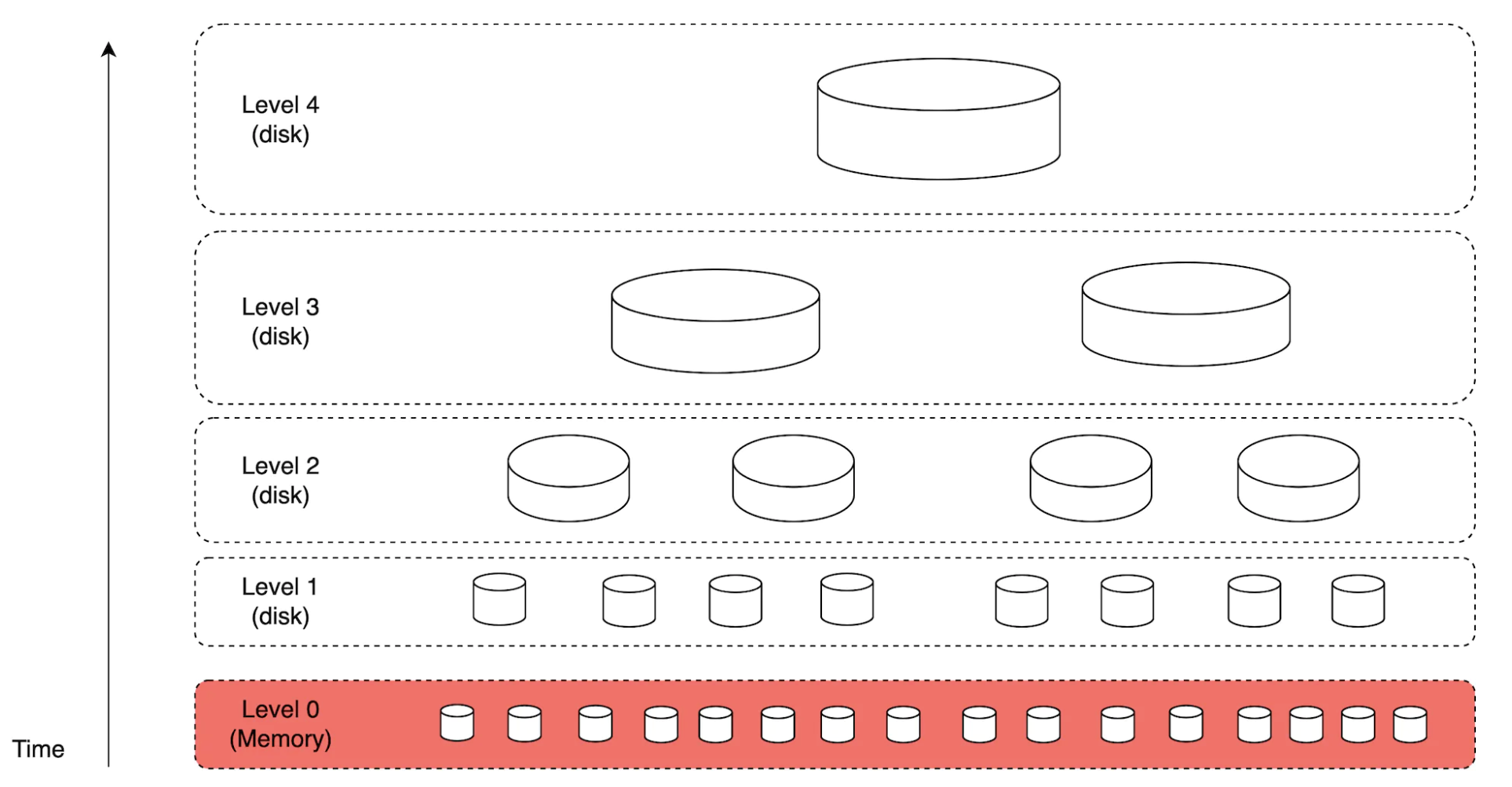
색인을 구축하는 프로세스는 다량의 쓰기 연산을 발생시킬 수 밖에 없으므로 LSM(Log-Structured Merge)트리를 사용하여 디스크에 저장되는 색인을 구조화하는 것이 바람직한 전략이다.
- 쓰기 경로는 순차적 쓰기 연산(sequential write)만 수행하도록 최적화 되어있다.
- 빅테이블이나 카산드라, RocksDB 같은 데이터베이스의 핵심 자료 구조다.
- 새로운 이메일이 도착하면 우선 메모리 캐시로 구현되는 0번 계층에 저장된다.
- 메모리에 보관된 데이터의 양이 사전에 정의된 임계치를 넘으면 데이터는 다음 계층에 병합된다.
자주 바뀌는 데이터를 그렇지 않은 데이터와 분리하는 효과도 얻을 수 있다.
- 이메일 데이터는 보통 바뀌지 않지만 메일 폴더의 정보는 상이한 필터링 규칙들 때문에 자주 바뀌는 경향이 있다.
- 데이터를 두 개 파트로 나누거 어떤 요청이 폴더 변경에 관한 것 이면 폴더 정보만 바꾸고 이메일 데이터는 내벼려둔다.
소규모의 이메일 시스템을 구축하는 경우 통합하기 쉽고 엔지니어링에 많은 노력이 필요하지 않은 일래스틱서치가 좋은 선택지이다.
대규모 시스템을 구축하는 경에도 일래스틱서치를 사용할 수 있겠지만 이메일 검색 인프라를 개발하고 관리하는 전담 팀이 필요할 수 있다.
지메일이나 아웃룩 규모의 이메일 시스템을 지원하려면 독립적인 검색 전용 시스템을 두기보다는 데이터베이스에 내장된 전용 검색 솔루션을 사용하는 것이 바람직할 수도 있다.
규모 확장성 및 가용성
각 사용자의 데이터 접근 패턴은 다른 사용자와 무고나하므로, 시스템의 대부분 컴포넌트는 수평적으로 규모 확장이 가능할 것으로 기대할 수 있다.
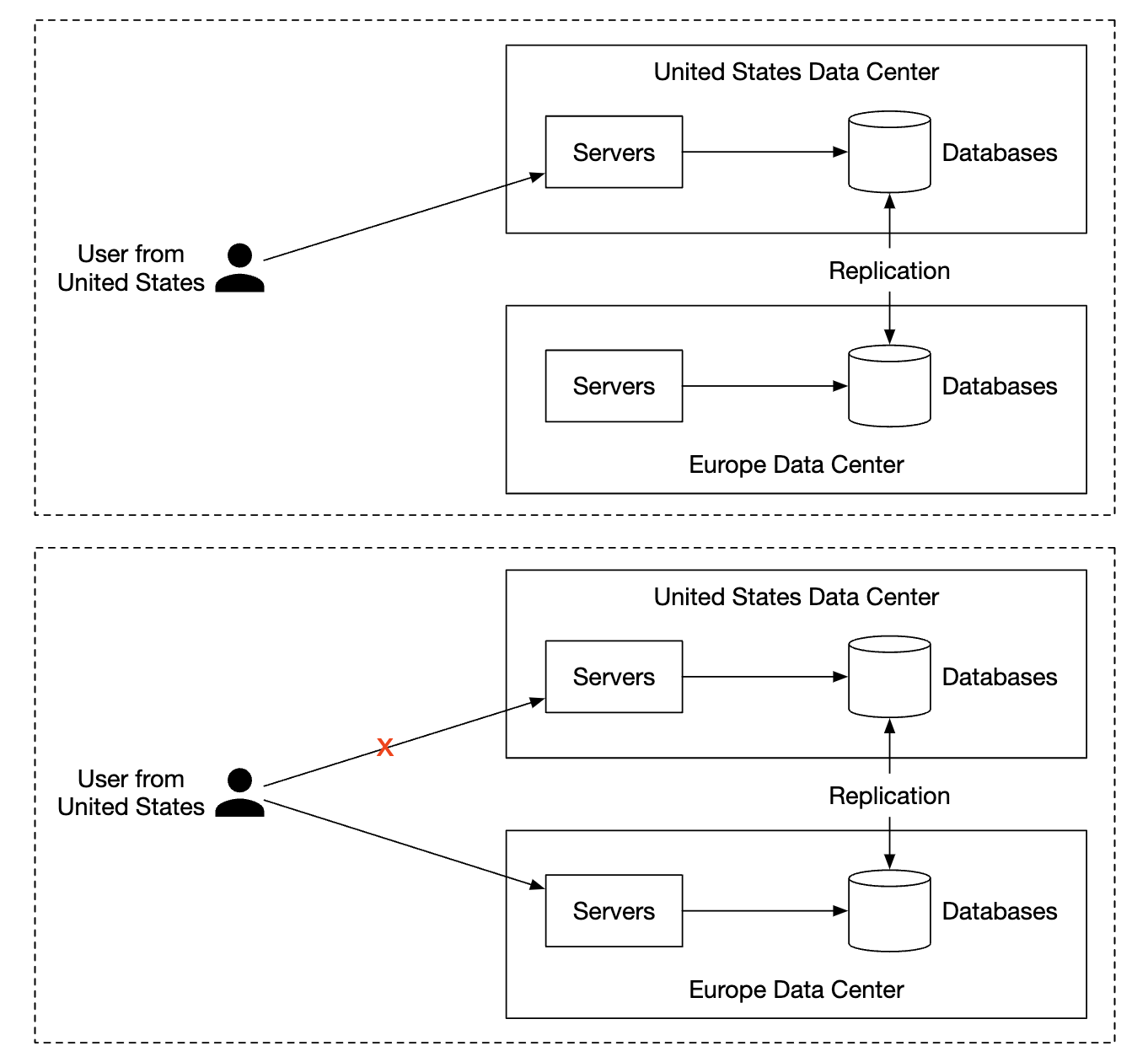
가용성을 향상시키기 위해서는 데이터를 여러 데이터센터에 다중화하는 것이 필요하다.
- 자신과 물리적으로 가까운 메일 서버와 통신한다.
- 네트워크 파티션 발생시 다른 데이터센터에 보관된 메시지를 이용한다.
4단계: 마무리
면접장에서 시간이 남는다면 추가로 논의해 볼 만한 주제로는 다음과 같은 것들이 있다.
- 결함 내성
- 노드 장애, 네트워크 문제, 이벤트 전달 지연 등의 문제에 어떻게 대처할지 살펴보면 좋을 것이다.
- 규정 준수
- 전 세계 다양한 시스템과 연동해야 하고 각 나라에는 준수해야할 법규가 있다.
- 보안
- 민감한 정보가 포함되므로 보안이 매우 중요하다.
- 피싱 방지, 안전 브라우징, 첨부 파일 사전 경고, 계정 안전, 기밀 모드, 이메일 암호화 등
- 최적화
- 같은 이메일이 여러 수신자에 전송되는 경우 동일한 첨부 파일이 있는지 확인하는 방식으로 최적화를 진행할 수 있다.