
이번 장은 페이스북이나 구글 규모에 걸맞는 광고 클릭 이벤트 집계 시스템(ad click event aggregation system)을 설계해본다.
기술적인 세부사항을 깊이 살펴보기 전 온라인 광고의 핵심 개념부터 살펴본다.
온라인 광고의 핵심적 혜택은 실시간 데이터를 통해 광고 효과를 정량적으로 측정할 수 있다는 점이다.
핵심 프로세스는 RTB(Real-Time Bidding)으로, 이 경매 절차를 통해 광고가 나갈 지면(inventory)을 거래한다.
flowchart LR
subgraph 지면수요자
direction LR
광고주 --> DSP[DSP: 수요자 플랫폼]
end
DSP --> 광고거래소
SSP --> 광고거래소
subgraph 지면공급자
direction RL
공급자 --> SSP[SSP: 공급자 플랫폼]
end
- 속도
- 보통 1초 내에 모든 프로세스가 마무리되어야 한다.
- 데이터 정확성
- 광고 클릭 이벤트 집계는 온라인 광고가 얼마나 효율적이었는지 측정하는 데 결정적인 역할을 한다.
- 광고주가 얼마나 많은 돈을 지불할지에 영향을 끼친다.
- 클릭 집계 결과에 따라 광고 캠페인 관리자는 예산을 조절할 수 있다.
- 타깃이나 키워드를 변경하는 등 공고 전략을 수정할 수 있다.
- CTR(Click-Through Rate, 클릭률), CVR(Conversion Rate, 전환률)
- 광고 클릭 이벤트 집계는 온라인 광고가 얼마나 효율적이었는지 측정하는 데 결정적인 역할을 한다.
1단계: 문제 이해 및 설계 범위 확정
기능 요구사항
- 지난 M분 동안의
ad_id클릭 수 집계 - 매분 가장 많이 클릭된 상위 100개 광고 아이디를 반환
- 다양한 속성에 따른 집계 필터링을 지원
- 데이터의 양은 페이스북이나 구글 규모
비기능 요구사항
- 집계 결과 정확성은 데이터가 RTB 및 광고 과금에 사용되므로 중요
- 지연되거나 중복된 이벤트를 적절히 처리할 수 있어야 함
- 견고성
- 부분적인 장애는 감내할 수 있어야함
- 지연 시간 요구사항
- 전체 처리 시간은 최대 수 분을 넘지 않아야함
개력적 추정
시스템 규모 및 풀어야 할 잠재적 문제점을 파악하기 이해 개략적인 규모를 추정해본다.
- DAU 10억
- 각 사용자는 하루에 평균 1개 광고를 클릭한다 가정
- 따라서 하루에 10억 건의 광고 클릭 이벤트 발생
광고 클릭 QPS = 10^9 / 10^5 = 10,000- 최대 광고 클릭 QPS는 평균 QPS의 5배로 가정(50,000)
- 광고 클릭 이벤트 하나당
0.1KB용량이 필요하다고 가정일일 저장소 요구량 = 0.1KB * 10억 = 100GB- 월간 저장 용량 요구량은 대략 3TB
2단계: 개략적 설계안 제시 및 동의 구하기
질의 API 설계
API를 설계하는 목적은 클라이언트와 서버 간의 통신 규약을 만드는 것 이다.
본 설계안의 클라이언트는 대시보드를 이용하는 데이터 과학자, 제품 관리자, 광고주 같은 사람으로, 대시보드를 이용하는 순간 집계 서비스에 질의가 발생한다.
지난 M분간 각 ad_id에 발생한 클릭 수 집계
| API | 용도 |
|---|---|
| GET /v1/ads/{:ad_id}/aggregated_count | 주어진 ad_id에 발생한 이벤트 수를 집계하여 반환 |
호출 인자
- from : 집계 시작 시간
- to: 집계 종료 시간
- filter: 필터링 전략 식별자
반환 응답
- ad_id: 광고 식별자
- count: 집계된 클릭 횟수
지난 M분간 가장 많은 클릭이 발생한 상위 N개 ad_id 목록
| API | 용도 |
|---|---|
| GET /v1/ads/popular_ads | 지난 M분간 가장 많은 클릭이 발생한 상위 N개 광고 목록 반환 |
- 호출 인자
- count: 상위 몇 개의 광고를 반환할 것인가
- window: 분 단위로 표현된 집계 윈도 크기
- filter: 필터링 전략 식별자
- 응답
- ad_ids: 공고 식별자 목록
데이터 모델
이 시스템은 원시 데이터와 집계 결과 데이터를 다룬다.
원시 데이터
로그 파일 등으로 저장된 가공되지 않은 데이터를 의미한다.
| |
위와 같은 데이터가 여러 애플리케이션 서버에 산재해있다.
집계 결과 데이터
공고 클릭 이벤트가 매분 집계된다고 가정한다면 아래처럼 표현될 수 있다.
| ad_id | click_minute | count |
|---|---|---|
| ad001 | 202101010000 | 5 |
| ad001 | 202101010001 | 7 |
광고 필터링을 지원하기 위해 filter_id를 추가하고 같은 ad_id와 click_minute 값을 갖는 레코드를 filter_id가 가리키는 필터 적용 결과에 따라 집계하면 아래와 같은 결과가 만들어진다.
| ad_id | click_minute | filter_id | count |
|---|---|---|---|
| ad001 | 2021010000 | 0012 | 2 |
| ad001 | 2021010000 | 0023 | 3 |
| ad001 | 2021010001 | 0012 | 1 |
| ad001 | 2021010001 | 0023 | 6 |
| filter_id | region | ip | user_id |
|---|---|---|---|
| 0012 | US | 0012 | * |
| 0013 | * | 0023 | 123.1.2.3 |
지난 M분 동안 가장 많이 클릭된 상위 N개의 광고를 반환하는 질의를 지원하기 위해서는 다음 구조를 사용한다.
erDiagram
most_clicked_ads {
window_size integer
update_time_minute timestamp
most_clicked_ads array
}
비교
원시 데이터를 저장하는 방안과 집계 결과 데이터만 보관하는 방안의 장점을 비교해보면 아래와 같다.
- 원시 데이터만 보관하는 방안
- 장점
- 원본 데이터를 손실 없이 보관
- 데이터 필터링 및 재계산 지원
- 단점
- 막대한 데이터 용량
- 낮은 질의 성능
- 장점
- 집계 결과 데이터만 보관하는 방안
- 장점
- 데이터 용량 절감
- 빠른 질의 기능
- 단점
- 데이터 손실
- 원본 데이터가 아닌 계산/유도된 데이터를 저정하는 데서 오는 결과임
- 예시 > 10개의 원본 데이터는 1개의 집계 결과로 축약된다
- 데이터 손실
- 장점
원시 데이터와 집계 결과 데이터의 특성으로 인해 모두 저장하는 것이 바람직하다.
- 문제가 발생하면 디버깅에 활용할 수 있도록 원시 데이터도 보관하는 것이 좋다.
- 데이터가 손상되면 버그 수정 후에 원시 데이터에서 집계 결과를 다시 만들 수 있다.
- 원시 데이터는 양이 엄청나므로 직접 질의하는 것은 비효율적이다.
- 집계 결과 데이터를 질의한다.
- 원시 데이터는 백업 데이터로 활용할 수 있다.
- 재계산을 하는 경우가 아니라면 굳이 원시 데이터를 질의할 필요는 없다.
- 오래된 원시 데이터는 cold storage로 옮기면 비용을 절감할 수 있다.
- 집계 결과 데이터는 활성 데이터 구실을 한다.
- 질의 성능을 높이기 위해 튜닝하는 것이 일반적이다.
올바른 데이터베이스 선택
올바른 데이터베이스를 선택하기 위해 여러 사항을 고려해야한다.
- 데이터는 어떤 모습인가?
- 관계형 데이터?, 문서 데이터?, 이진 대형 객체(BLOB)?
- 작업 흐름이 읽기 중심인가 쓰기 중심인가?(아님 둘다?)
- 트랜잭션을 지원해야 하는가?
- 질의 과정에서 SUM, COUNT 같은 온라인 분석 처리 함수를 많이 활용해야 하는가?
원시 데이터
일상적인 작업을 위해서라면 질의할 필요가 없지만, 데이터 과학자나 기계 학습 엔지니어가 연구등으로 활용될 수 있다.
- 이 설계안이 다루는 시스템에서 발생하는 평균 쓰기 QPS는 10,000, 최대 50,000 이므로 쓰기 중심 시스템이라고 볼 수 있다.
- 원시 데이터는 백업과 재계산 용도로 활용하므로 읽기 연산 빈도는 낮다.
관계형 데이터베이스도 활용 가능하지만 큰 규모의 쓰기 연산이 가능하도록 구성하기 매우 어려우므로, 쓰기 및 시간 범위 질의에 최적화된 카산드라나 InfluxDB를 사용하는 것이 좀 더 바람직하다.
- 칼럼형(columnar) 데이터 형식 가운데 하나를 사용하여 아마존 S3에 데이터를 저장하는 방법도 고려할 수 있다.
- ORC, 파케이(Parquet), AVRO
- 각 파일의 최대 크기를 제한하면 원시 데이터 기록 담당 스트림 프로세서가 새 파일을 만든다
집계 데이터
집계 데이터는 본질적으로 시계열 데이터이며, 이 데이터를 처리하는 워크 플로는 읽기 연산과 쓰기 연산 둘 다 많이 사용한다.
집계 서비스가 데이터를 매 분 집계하고 그 결과 데이터를 저장하는 데는 같은 유형의 데이터베이스를 활용하는 것이 가능하다(카산드라).
개략적 설계안
실시간으로 빅데이터를 처리할 때 데이터는 보통 무제한으로 시스템에 흘러들어왔다가 나간다.
flowchart
subgraph 입력
logMonitor[로그모니터]
end
subgraph 프로세스
dataAgg[데이터 집계 서비스]
end
subgraph 출력
db[(데이터베이스)]
end
subgraph 표시
query[질의 서비스]
end
logMonitor --데이터 푸시--> dataAgg
dataAgg --광고 수--> db
dataAgg --가장 많이 클릭된 상위 100개 광고--> db
query --질의--> db
비동기 처리
제시한 설계안은 동기식 처리를 기반으로 하지만, 생산자와 소비자의 용량이 항상 같을 수는 없기 때문에 좋지 않을 수 있다.
- 트래픽이 갑자기 증가하여 발생하는 이벤트 수가 소비자의 처리 용량을 훨씬 넘어서는 경우 소비자는 메모리 부족 오류 등의 예기치 않은 문제를 겪게 될 수 있다.
- 동기식 시스템의 경우 특정 컴포넌트의 장애는 전체 시스템의 장애로 이어진다.
이 문제를 해결하는 일반적인 방안은 카프카 같은 메시지 큐를 도입하여 생산자와 소비자의 결함을 끊는 것이다.
- 전체 프로세스가 비동기로 동작하게된다.
- 비동기로 동작하므로 생산자와 소비자의 규모를 독립적으로 확장해 나갈 수 있게된다.
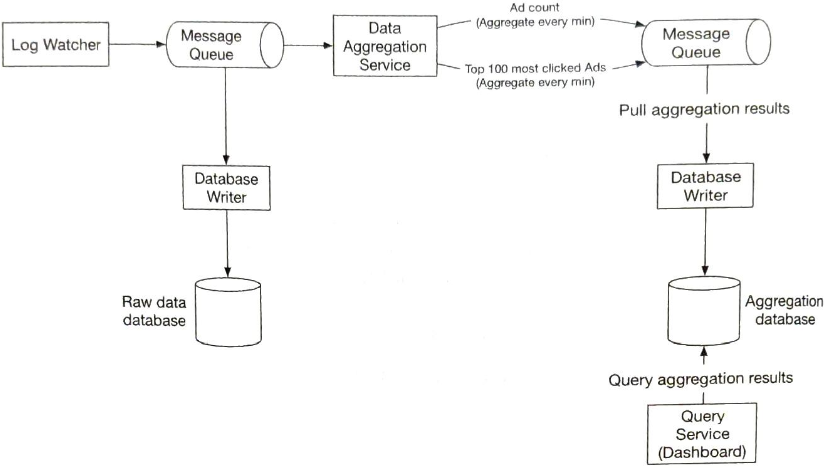
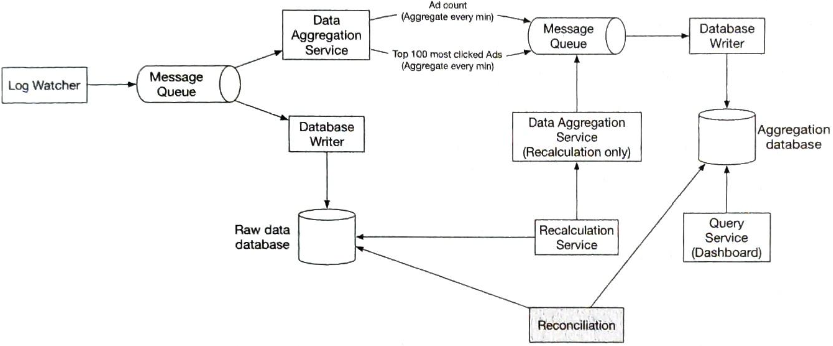
로그 감시자, 집계 서비스, 데이터베이스는 두 개의 메시지 큐로 분리되어있다.
데이터베이스 기록 프로세스는 메시지는 메시지 큐에서 데이터를 꺼내 데이터베이스가 지원하는 형식으로 변환 후 기록하는 역할을 수행한다.
- 첫 번째 메시지 큐
- 광고 클릭 이벤트가 기록된다.
- ad_id, click_timestamp, user_id, ip, country
- 두 번째 메시지 큐
- 분 단위로 집게된 광고 클릭 수
- 분 단위로 집계한, 가장 많이 클릭한 상위 N개 광고
집계 결과를 데이터베이스에 바로 기록하지 않는 이유는 정확하게 한 번(exactly once) 데이터를 처리하기 위해(atomic commit, 원자적 커밋) 카프카 같은 시스템을 두 번 째 메시지 큐로 도입해야 하기 때문이다.
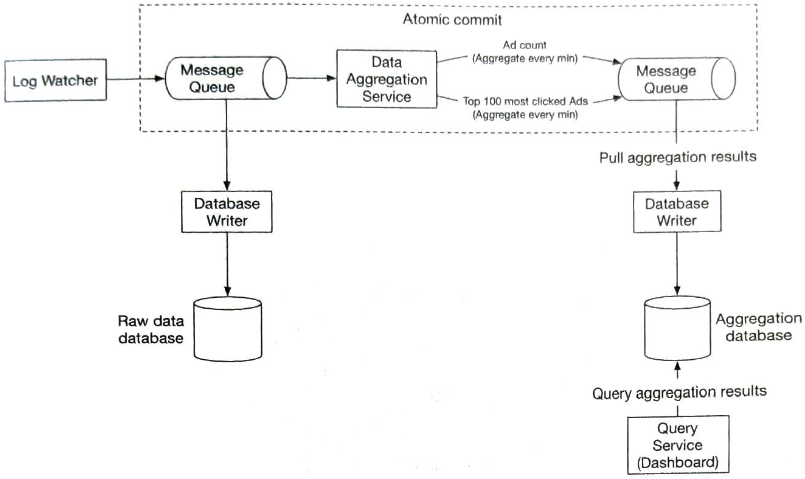
집계 서비스
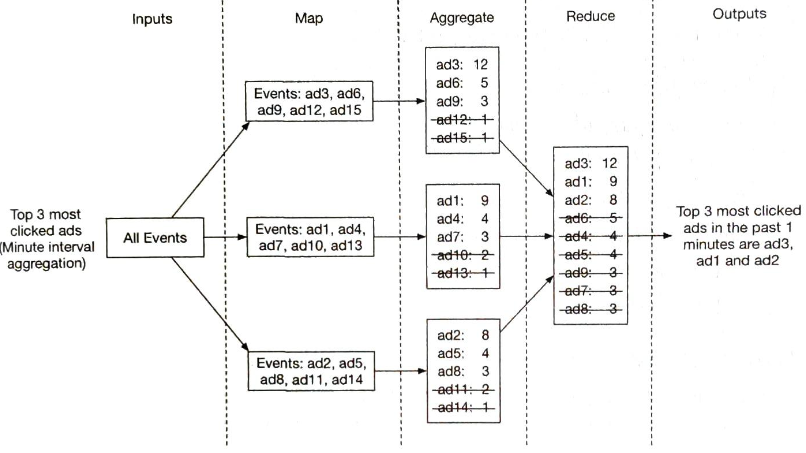
광고 클릭 이벤트를 집계하는 좋은 방안 하나는 맵리듀스(MapReduce) 프레임워크를 사용하는 것 이다.
맵리듀스 프레임워크에 좋은 모델은 유향 비순환 그래프(DAG) 모델이며, 시스템을 맵/집계/리듀스 노드 드으이 작은 컴퓨팅 단위로 세분화 할 수 있다.
- 각 노드는 한 가지 작업만 처리하며, 처리 결과를 다음 노드에 인계한다.
flowchart LR
data --데이터 입력-->
Map((Map)) --ad_id % 2 = 0--> node1((집계 노드 1))
Map --ad_id % 2 = 1--> node2((집계 노드 2))
맵 노드
맵 노드는 데이터 출처에서 읽은 데이터를 필터링하고 변환하는 역할을 담당한다.
- 카프카 파티션이나 태그를 구성한 후 집계 노드가 카프카를 직접 구독하도록 할 경우 맵 노드를 활용하지 않을 수 있지만, 입력 데이터를 정리하거나 정규화해야 하는 경우에는 맵 노드가 필요하다.
- 데이터가 생성되는 방식에 대한 제어권이 없는 경우 동일한 ad_id를 갖는 이벤트가 서로 다른 카프카 파티션에 입력될 수 있다.
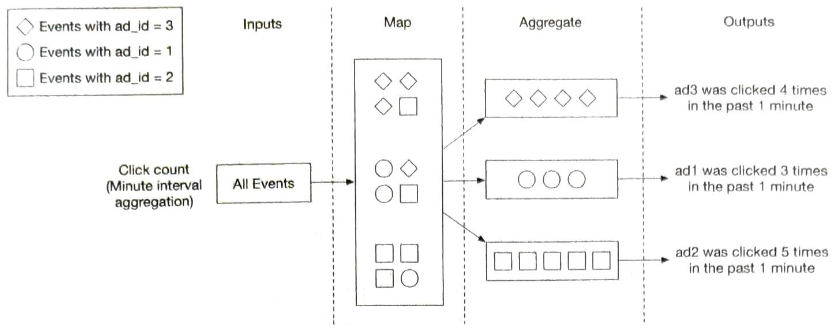
집계 노드
집계 노드는 ad_id 별 광고 클릭 이벤트 수를 매 분 메모리에서 집계한다.
맵리듀스 패러다임에서 사실 집계 노드는 리듀스 프로세스의 일부여서, 맵-집계-리듀스 프로세스는 맵-리듀스-리듀스 프로세스라고도 할 수 있다.
리듀스 노드
리듀스 노드는 모든 집계 노드가 산출한 결과를 최종 결과로 축약한다.
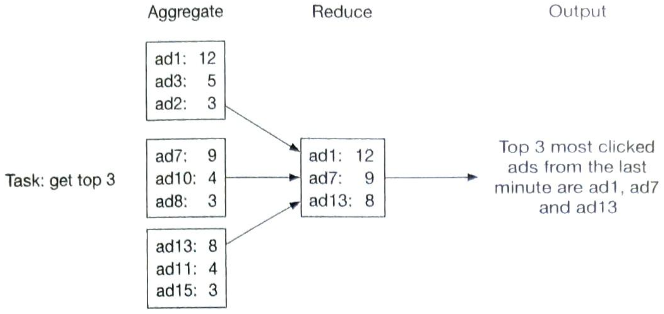
DAG는 맵리듀스 패러다임을 표현하기 위한 모델로, 빅데이터를 입력으로 받아 병렬 분산 컴퓨팅 자원을 활용하여 빅데이터를 작은(일반적) 크기 데이터로 변환할 수 있도록 설계된 모델이다.
중간 데이터는 메모리에 저장될 수 있으며, 노드 간 통신은 서로 다른 프로세스에서 실행되는 경우 TCP, 서로 다른 스레드에서 실해오디는 경우 공유 메모리로 처리할 수도 있다.
주요 사용 사례
- 클릭 이벤트 수 집계
- 가장 많이 클릭된 상위 N개 광고 반환
- 데이터 필터링
- 필터링 기준을 사전에 정의한 후 해당 기준에 따라 집계한다.
스타 스키마
데이터 웨어하우스에서 널리 쓰이는 기법으로, 필터링에 사용되는 필드는 차원이라 부른다.
- 장점
- 이해하기 쉽고 구축하기 간단하다.
- 기존 집계 서비스를 재사용하여 스타 스키마에 더 많은 차원을 생성할 수 있다. 다른 추가 컴포넌트는 필요없다.
- 결과를 미리 계산해 두는 방식이므로, 필터링 기준에 따라 데이터에 빠르게 접근할 수 있다.
- 단점
- 많은 버킷과 레코드가 생성된다. (필터링 기준이 많을 경우 더더욱)
3단계: 상세 설계
스트리밍 vs 일괄 처리
| 서비스(온라인 시스템) | 일괄 처리 시스템(오프라인 시스템) | 스트리밍 처리 시스템(실시간에 가깝게 처리하는 시스템) | |
|---|---|---|---|
| 응답성 | 클라이언트에게 빠르게 응답 | 클라이언트에게 응답할 필요가 없음 | 클라이언트에게 응답할 필요가 없음 |
| 입력 | 사용자의 요청 | 유한한 크기를 갖는 입력. 큰 규모의 데이터 | 입력에 경계가 없음(무한 스트림) |
| 출력 | 클라이언트에 대한 응답 | 구체화 뷰, 집계 결과 지표 등 | 구체화 뷰, 집계 결과 지표 등 |
| 성능 측정 기준 | 가용성, 지연 시간 | 처리량 | 처리량, 지연 시간 |
| 사례 | 온라인 쇼핑 | 맵리듀스 | 플링크 |
본 설계안은 스트림 처리와 일괄 처리 방식을 모두 사용한다.
- 스트림 처리는 데이터를 오는 대로 처리하고 거의 실시간으로 집계된 결과를 생성하는 데 사용한다.
- 일괄 처리는 이력 데이터를 백업하기 위해 활용한다.
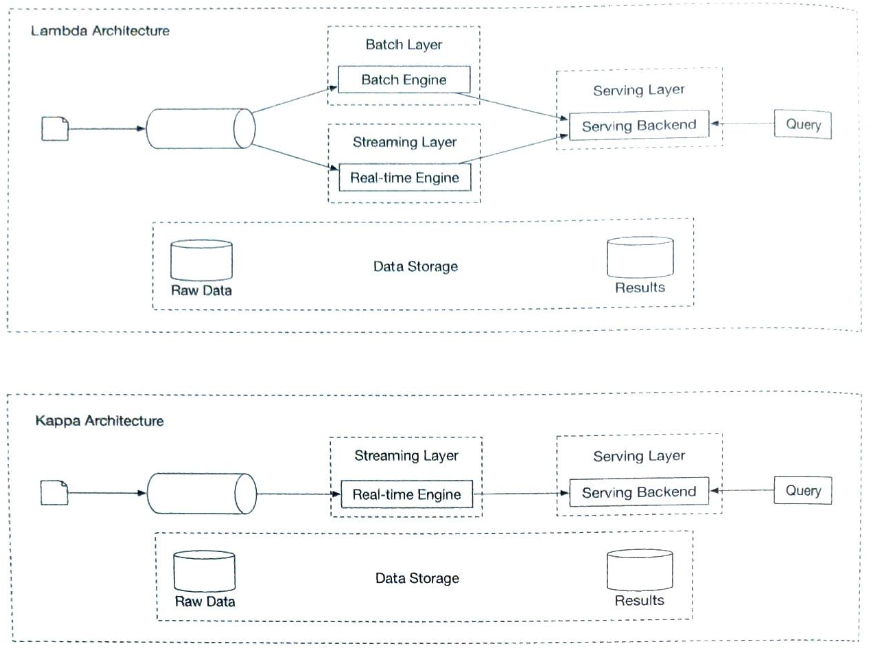
람다 아키텍처
일괄 및 스트리밍 처리 경로를 동시에 지원하는 시스템의 아키텍처를 람다(lambda)라고 부른다.
람다 아키텍처의 단점은 두 가지 처리 경로를 지원하므로 유지 관리 해야할 코드가 두 벌이라는 점이다.
카파 아키텍처
카파 아키텍처(Kappa architecture)는 일괄 처리와 스트리밍 처리 경로를 하나로 결합하여 람다 아키텍처의 단점을 해결한다.
핵심 아이디어는 단일 스트림 처리 엔진을 사용하여 실시간 데이터 처리 및 끊임없는 데이터 재처리 문제를 모두 해결하는 것이다.
본 시스템의 개략적 설계안은 카파 아키텍처를 따른다. 따라서 이력 데이터의 재처리도 실시간 집계 서비스를 거치게된다.
데이터 재계산
이미 집계한 데이터를 다시 계산해야 하는 경우가 있는데, 이를 이력 데이터 재처리(historical data replay)라고도 부른다.
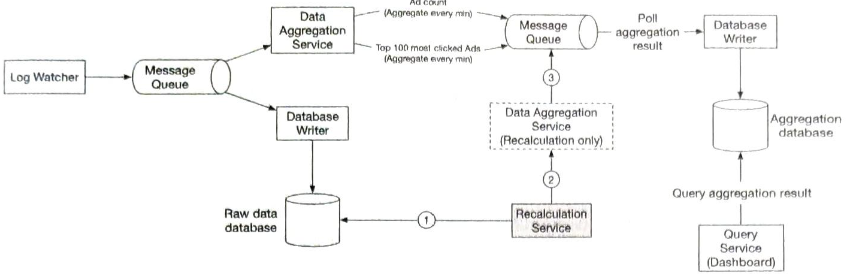
- 원시 데이터 저장소에서 데이터를 검색한다.
- 추출된 데이터를 전용 집계 서비스로 전송한다.
- 전용 집계 서비스는 실시간 데이터 처리 과정이 과거 데이터 재처리 프로세스와 간섭하는 일을 막기 위해 추가한다.
- 집계 결과는 두 번째 메시지 큐로 전송되어 집계 결과 데이터베이스에 반영된다.
재계산 프로세스는 데이터 집계 서비스를 재사용하기는 하지만 처리 대상 데이터는 다른 곳에서 읽는다(원시 데이터).
시간
집계를 하려면 타임스탬프가 필요한데, 타임 스탬프는 두 가지 다른 위치에서 만들어질 수 있다.
- 이벤트 시각: 광고 클릭이 발생한 시각
- 처리 시각: 집계 서버가 이벤트를 처리한 시스템 시각
네트워크 지연이나 비동기 처리 환경(데이터가 메시지 큐를 거쳐야 하는 환경)때문에 이벤트가 발생한 시각과 처리 시각 사이의 간격이 커질 수 있다.
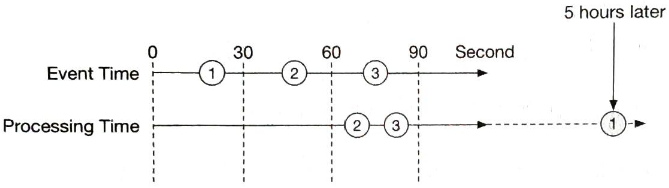
이벤트가 발생한 시각을 집계에 사용하는 경우 지연된 이벤트 처리 문제를 잘 해결해야 하며, 처리 시각을 집계에 사용하는 경우 집계 결과가 부정확할 수 있다는 점을 고려해야 한다.
완벽한 솔루션은 없으므로, 두 방은의 장단점을 고려하여 적절한 결정을 내린다.
- 이벤트 발생 시각
- 장점
- 광고 클릭 시점을 정확히 아는 것은 클라이언트이므로 집계 결과가 보다 정확
- 단점
- 클라이언트가 생성한 타임스탬프에 의존하는 방식이므로 클라이언트에 설정된 시각이 잘못 되었거나 악성 사용자가 타임스탬프를 고의로 조작하는 문제에서 자유로울 수 없음
- 장점
- 처리 시각
- 장점
- 서버 타임스탬프가 클라이언트 타임스탬프보다 안정적
- 단점
- 이벤트가 시스템에 도착한 시각이 함참 뒤인 경우에는 집계 결과가 부정확해짐
- 장점
데이터 정확도는 아주 중요하므로, 이벤트 발생 시각을 사용할 것을 추천한다.
이러한 경우 시스템에 늦게 도착한 이벤트를 올바르게 처리하기 위해 워터마크(watermark)라는 기술이 일반적으로 사용된다.
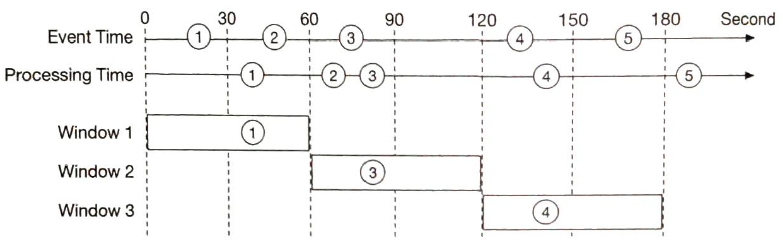
이벤트 발생 시각을 기준으로 이벤트가 어떤 윈도에 속하는지 결정하면 이벤트가 집계 윈도가 끝나는 시점보다 살짝 늦게 도착하게되는 경우 집계에 실패하게된다.
워터마크는 집계 윈도를 확장하여 집계 정확도를 높힐 수 있다.
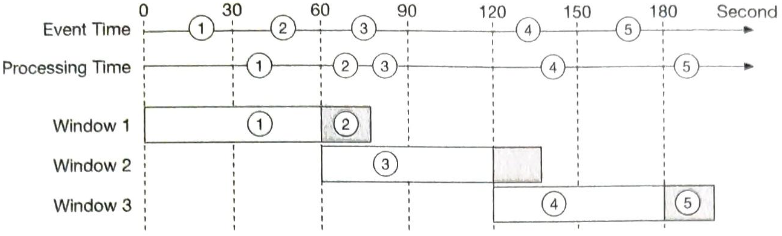
15초 워터마크를 윈도 마다 붙이면 윈도 1, 3이 누락된 이벤트를 집계할 수 있게 된다.
워터마크의 크기는 비즈니스 요구사항에 따라 달리 잡는다.
- 워터마크 구간이 길면 늦게 도착하는 이벤트도 포착할 수 있지만 시스템의 이벤트 처리 시간은 늘어난다.
- 짧으면 데이터 정확도는 떨어지지만 시스템의 응답 지연은 낮아진다.
워터마크를 사용하더라도 시간이 한참 흐른 후에 시스템에 도달하는 이벤트는 처리할 수 없다.
발생할 확률이 낮은 이벤트 처리를 위해 시스템을 복잡하게 설계하면 투자 대비 효능(ROI)는 떨어지고, 사소한 데이터 오류는 하루치 데이터 처리를 마감할 때 조정할 수 있으므로 워터마크 구간을 길게 가져갈 이유는 없다.
집계 윈도
윈도에는 텀블링 윈도(tumbling window, 고정 윈도(fixed window) 라고도 함), 호핑 윈도(hopping window), 슬라이딩 윈도(sliding window), 세션 윈도(session window) 총 네 종류가 있다.
이 가운데 텀플링 윈도와 슬라이딩 윈도가 설계안과 관련있다.
텀블링 윈도

시간을 같은 크기의 겹치지 않는 구간으로 분할하므로, 매 분 발생한 클릭 이벤트를 집계하기 적합하다.
슬라이딩 윈도
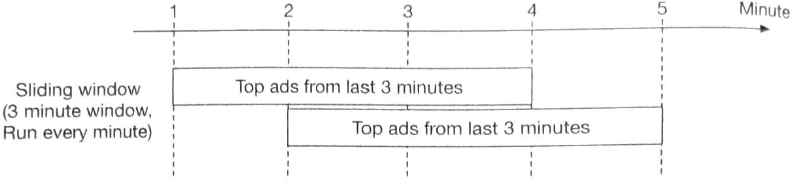
데이터 스트림을 미끄러져 나아가면서 같은 시간 구간 안에 있는 이벤트를 집계한다. 슬라이딩 윈도는 서로 겹칠 수 있어 시스템의 두 번째 요구사항인 지난 M분간 가장 많이 클릭된 상위 N개 광고를 알아내기 적합하다.
전달 보장
집계 결과는 과금 등에 활용될 수 있기 때문에 데이터의 정확성과 무결성이 아주 중요하다.
- 이벤트의 중보 처리를 어떻게 피할 수 있는가?
- 모든 이벤트의 처리를 어떻게 보장할 수 있는가?
카프카와 같은 메시지 큐는 보통 최대 한 번, 최소 한 번, 정확히 한 번 총 세 가지 유형의 전달 방식을 지원한다.
어떤 전달 방식을 택할 것 인가?
약간의 중복이 괜찮다면 대체로 최 소 한번이 적절하나, 본 설계안은 데이터의 몇 퍼센트 차이가 수백만 달러 차이로 이어질 수 있으므로 정확히 한 번방식을 권장한다.
데이터 중복 제거
가장 흔한 데이터 품질 이슈 가운데 하나는 중복된 데이터이다.
- 클라이언트측
- 한 클라이언트가 같은 이벤트를 여러 번 보내는 경우
- 악의적인 의도로 전송되는 중복 이벤트를 처리하는 데는 광고 사기/위험 제어 컴포넌트(ad fraud/risk controller)가 적합하다.
- 서버 장애
- 집계 도중에 집계 서비스 노드에서 장애가 발생하였고, 업 스트림 서비스가 이벤트 메시지에 대해 응답을 받지 못한경우, 같은 이벤트가 다시 전송되어 재차 집계될 가능성이 있다.
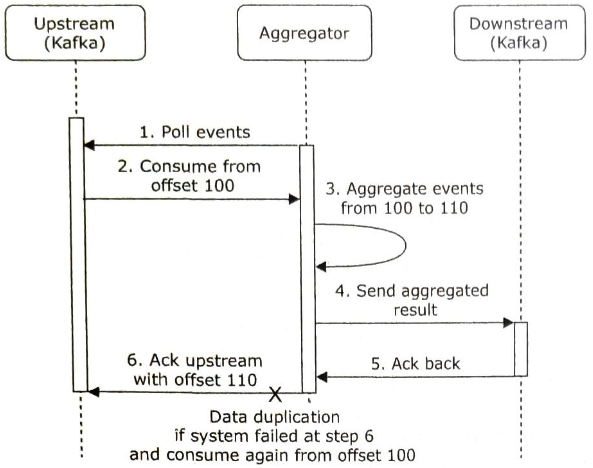
집계 서비스 노드에 장애가 생겨 6단계를 실행하지 못하면 100에서 110 까지의 이벤트는 이비 다운 스트림에 전송되었으나 새 오프셋은 업스트림 카프카에 반영되지 않아, 새로 북고된 집계 서비스 노드는 오프셋 100부터 이벤트를 다시 소비하려고 할 것이다, 그 결과로 데이터 중복이 발생한다.
이 문제의 간단한 해결책으로 HDFS나 S3 같은 외부 파일 저장소에 오프셋을 기록하는 방법이 있다.
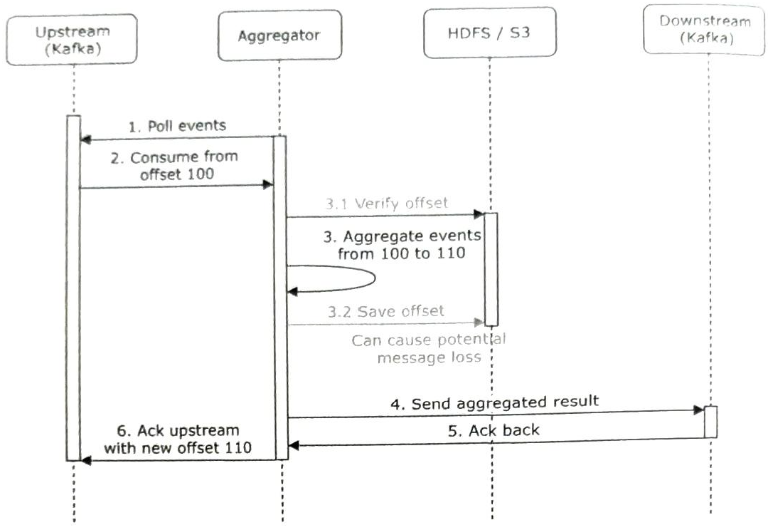
집계 결과를 다운 스트림으로 전송하기 전에 오프셋을 외부에 저장하고 있는데, 만일 그 직후 집계 서비스 노드에 장애가 발생하여 4단계를 완료하지 못했다면, 외부 저장소에 저장된 오프셋은 110이므로 복구된 집계 서비스 노드는 100부터 110 까지의 이벤트를 다시 처리하지 않는다.
따라서 데이터 손실을 막으려면 다운스트림에서 집계 결과 수신 확인 응답을 받은 후에 오프셋을 저장해야 한다.
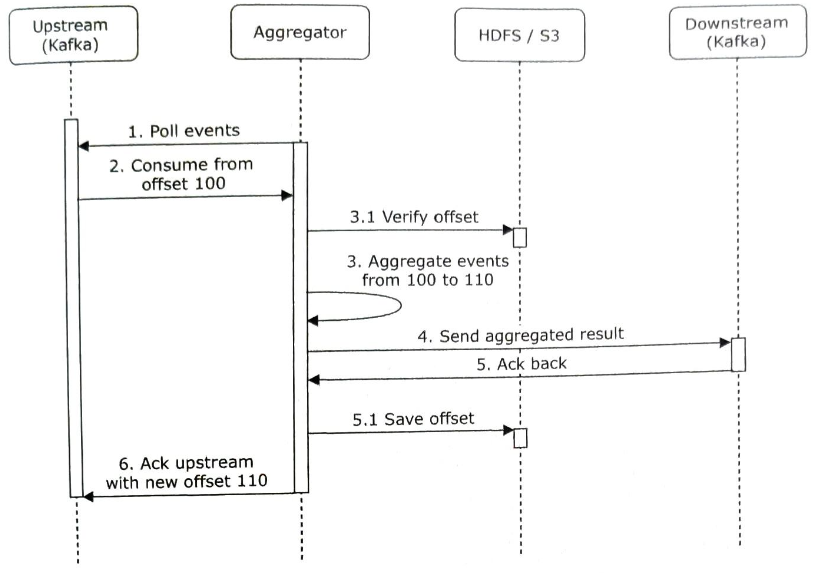
이벤트를 정확하게 한 번만 처리하고 싶다면 4단계부터 6단계가지의 작업을 하나의 분산 트랜잭션에 넣어야한다.
분산 트랜잭션은 여러 노드에서 작동하는 트랜잭션으로 그 안에서 실행하는 작업 가운데 하나라도 실패하면 모든 작업의 상태를 실행 전으로 되돌린다.
시스템 규모 확장
본 설계안은 메시지 큐, 집계 서버, 데이터베이스의 세 가지 독립 구성 요소로 이루어져, 상호 결합도가 낮으므로 각기 독립적으로 규모를 늘릴 수 있다.
메시지 큐의 규모 확장
메시지 큐의 규모 학장법에 대해서는 4장 분산 메시지 큐에서 광범위하게 설명했으므로 요점만 확인한다.
- 생산자
- 생산자 인스턴스 수에는 제한을 두지 않으므로 따라서 확정성은 쉽게 달성할 수 있다.
- 소비자
- 소비자 그룹 내의 재조정 매커니즘은 노드 추가/삭제를 통해 그 규모를 쉽게 조장할 수 있도록 한다.
수백 개 카프카 소비자가 있는 경우 재조정 작업 시간이 길어져서 수 분 이상 걸리게 될 수 있으므로 더 많은 소비자를 추가하는 작업은 시스템 사용량이 많지 않은 시간에 실행하여 영향을 최소화하는 것이 좋다.
브로커
- 해시 키
- 같은 ad_id를 갖는 이벤트를 같은 카프카 파티션에 저장하기 위해 ad_id를 해시 키로 사용한다.
- 집계 서비스는 같은 ad_id를 갖는 이벤트를 전부 같은 파티션에서 구독할 수 있다.
- 파티션의 수
- 파티션의 수가 변하면 같은 ad_id르 ㄹ갖는 이벤트가 다른 파티션에 기록되는 일이 생길 수 있으므로 사전에 충분한 파티션을 확보하여 프로덕션 환경에서 파티션의 수가 동적으로 늘어나는 일을 피하는 것이 좋다.
- 토픽의 물리적 샤딩
- 하나의 토픽만으로 충분한 경우는 거의 없다.
- 지역에 따라, 사업 유형에 따라 여러 토픽을 둘 수 있다.
- 장점
- 데이터를 여러 토픽으로 나누면 시스템의 처리 대역폭을 높일 수 있다.
- 단일 토픽에 대한 소비자의 수가 줄면 소비자 그룹의 재조정 시간도 단축된다.
- 단점
- 복잡성이 증가하고 유지 관리 비용이 늘어난다.
집게 서비스의 규모 확장
집계 서비스는 본질적으로 맵리듀스 연산으로 구현된다.
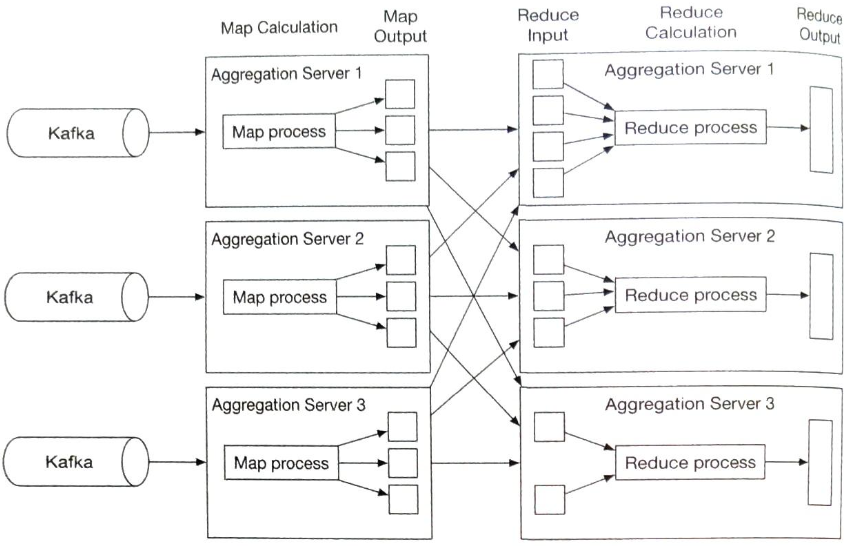
집계 서비스의 규모는 노드의 추가/삭제를 통해 수평적으로 조정이 가능하다.
집계 서비스의 처리 대역폭을 높이는 방법으로 두 가지 선택지가 있다.
- ad_id마다 별도의 처리 스레드를 두는 방식
- 집계 서비스 노드를 아파치 하둡 YARN 같은 자원 공급자에 배포하는 방식
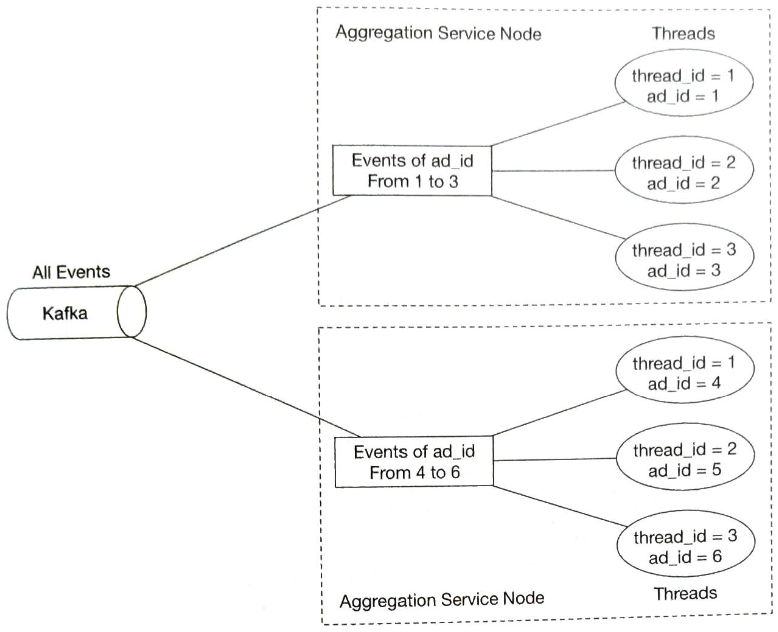
두 가지 방안 중 첫 번째가 더 구현하기 쉽고, 자원 공급자에 대한 의존 관계도 없다.
하지만, 더 많은 컴퓨팅 자원을 추가하여 시스템의 규모를 확장할 수 있는 두 번째 방안이 많이 활용된다.
데이터베이스의 규모 확장
카산드라는 안정 해시와 유사한 방식으로 수평적인 규모 확장을 기본적으로 지원한다.
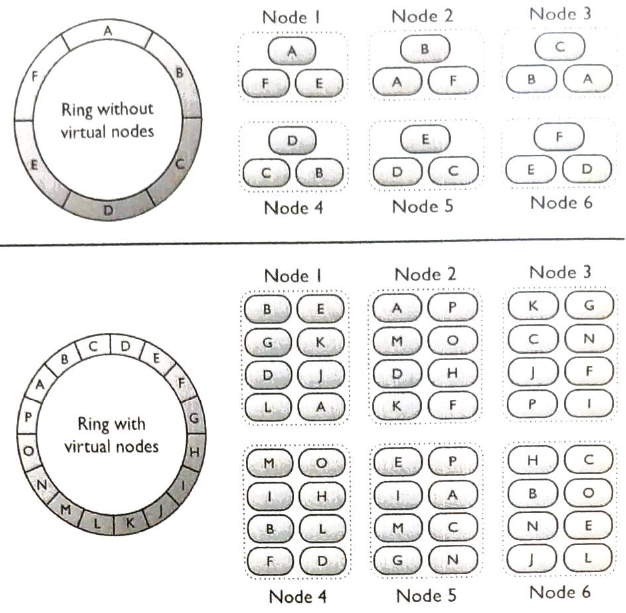
핫스팟 문제
다른 서비스나 샤드보다 더 많은 데이터를 수신하는 서비스나 샤드를 핫스팟이라 부른다.
광고 클릭 집계 시스템은 큰 회사가 큰 광고예산을 집행하여 더 많은 노출을 하게 만들수 있고, 이로 인해 특정 광고에 더 많은 클릭이 발생할 수 있다.
이벤트 파티션을 ad_id로 나누기 때문에 어떤 집계 서비스 노드는 다른 노드보다 더 많은 광고 클릭 이벤트를 수신하게 될 것이고, 그러다보면 서버 과부하 문제가 발생할 수 있다.
이러한 문제는 더 많은 집계 서비스 노드를 할당하여 완화할 수 있다.
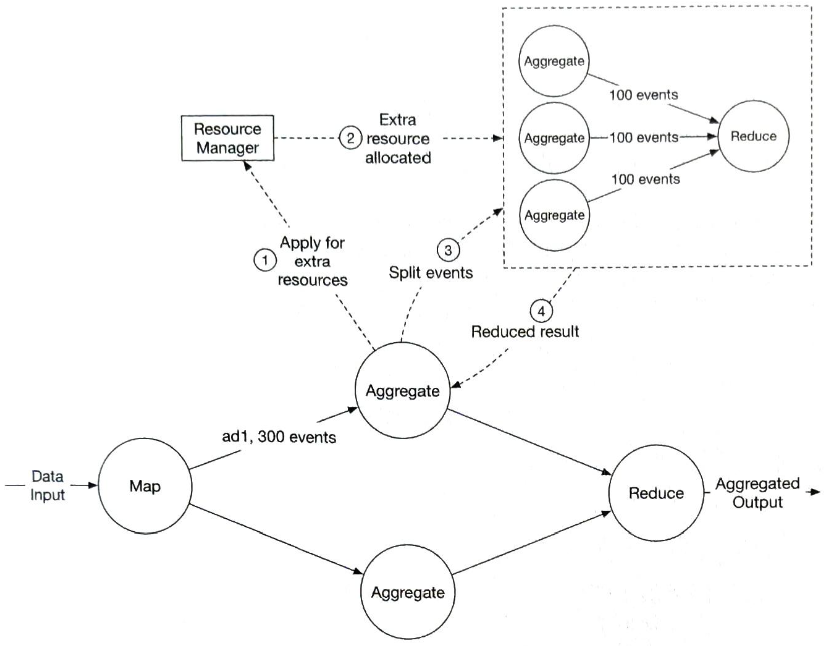
- 집계 서비스 노드에 300개 이벤트가 도착하여 노드가 감당할 수 있는 양을 초과 하였기 때문에 자원 관리자에게 추가 자원을 신청한다.
- 자원 관리자는 해당 서비스 노드에 과부하가 걸리지 않도록, 추가 자원을 할당한다.(예시는 두 개의 집계 서비스 노드)
- 원래 집계 서비스 노드는 각 서비스 노드가 100개씩의 이벤트를 처리할 수 있도록 이벤트를 세 개 그룹으로 분할한다.
- 집계가 끝나 축약된 결과는 다시 원래 집계 서비스 노드에 기록한다.
전역-지역 집계(Global-Local Aggregation)나 분할 고유 집계(Split Distinct Aggregation) 같은 복잡한 방법도 고려할 수 있다.
결함 내성
집게는 메모리에서 이루어지므로 집계 노드에 장애가 생기면 집계 결과도 손실된다.
하지만 업스트림 카프카 브로커에서 이벤트를 다시 받아오면 그 숫자를 다시 만들어 낼 수 있다.
카프카 데이터를 원점 주터 다시 재생하여 집계하면 시간이 오래 걸리므로, 업스트림 오프셋 같은 시스템 상태를 스냅숏으로 저장하고 마지막으로 저장된 상태부터 복구해 나가는 것이 바람직하다.
- 시스템 상태에 해당하는 정보는 업스트림 오프셋 뿐만 아니라 지난 M분간 가장 많이 클릭된 광고 N개 같은 데이터도 시스템 상태의 일부로 저장한다.
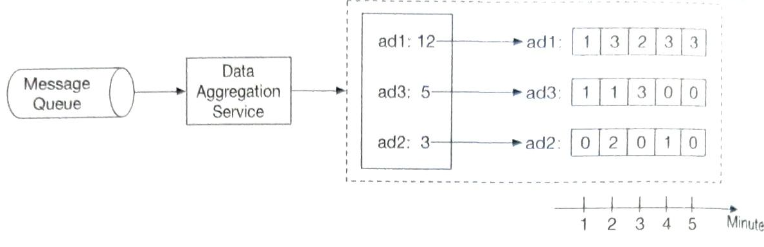
스냅숏을 이용하면 집계 서비스의 복구 절차가 단순해진다.
어떤 집계 서비스 노드 하나에 장애가 발생하면 해당 노드를 새 것으로 대체한 다음 마지막 스냅숏에서 데이터를 복구하면 된다.
데이터 모니터링 및 정확성
집계 결과는 RTB 및 청구서 발행 목적으로 사용될 수 있으므로ㅓ 시스템이 정상적으로 동작하는 지 모니터링 하고 데이터 정확성을 보장하는 것은 아주 중요한 과제이다.
지속적 모니터링
- 지연 시간
- 데이터를 처리하는 각 단계마다 지연 시간이 추가될 수 있으므로, 시스템의 중요 부분마다 시각 추적이 가능하도록 해야한다.
- 기록된 사각 사이의 차이를 지연 시간 지표로 변환해서 모니터링한다.
- 메시지 큐 크기
- 큐의 크기가 갑자기 늘어난다면 더 많은 집계 서비스 노드를 추가해야 할 수 있다.
- 카프카는 분산 커밋 로그 형태로 구현된 메시지 큐 이므로, 카프카를 사용하는 경우 레코드 처리 지연 지표를 대신 추적한다.
- 집계 노드의 시스템 자원
- CPU, 디스크, JVM 같은 것에 관계된 지표
조정
조정(reconciliation)은 다양한 데이터를 비교하여 데이터 무결성을 보증하는 기법을 일컫는다.
광고 클릭 집게 결과는 비교할 제 3자가 없으므로 매일 각 파이션에 기록된 클릭 이벤트를 이벤트 발생 시각에 따라 정렬한 결과를 일괄 처리하여 만들어낸 후, 실시간 집계 결과와 비교해 볼 수 있다.
- 더 높은 정확도가 필요하다면 더작은 집계 작은 집계 윈도를 사용한다.
- 윈도 크기와 관계 없이 일부 이벤트는 늦게 도착할 수 있으므로 배치 작업 결과가 실시간 집계 결과와 정확히 일치하지 않을 수 있다.
대안적 설계안
다른 한 가지 가능한 설계안은 광고 클릭 데이터를 하이브에 저장한 다음 빠른 질의는 일래스틱서치 계층을 얹어서 처리할 수 있다.
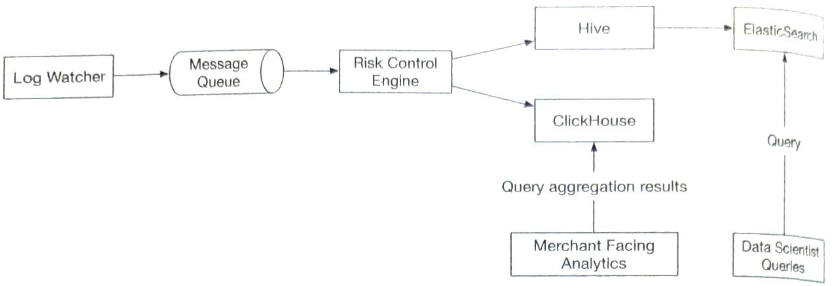
집계는 클릭하우스, 드루이드 같은 OLAP 데이터베이스를 통해 처리할 수 있다.
4단계: 마무리
이번 장에서는 페이스북이나 구글 규모의 광고 클릭 이벤트 집계 시스템을 설계하는 프로세스를 다루어 보았다.
- 데이터 모델 및 API 설계
- 맵리듀스 데이터 처리 패러다임을 통해 광고 클릭 이벤트를 집계하는 방법
- 메시지 큐, 집계 서비스, 데이터베이스의 규모 확장 방안
- 핫스팟 문제를 해결하는 방안
- 시스템의 지속적 모니터링
- 데이터 조정을 통한 정확성 보증 방안
- 결함 내성
광고 클릭 이벤트 집계 시스템은 전형적인 빅데이터 처리 시스템이다.
아파치 카프카, 아파치 플링크, 아파치 스파크 같은 업계 표준 솔루션에 대한 사전 지식이나 경험이 있다면 이해하고 설계하기 쉬울 것이다.