
이번 장에서는 온라인 증권 거래 시스템을 설계해본다.
거래소의 기본 기능은 구매자와 판매자가 효율적으로 연결될 수 있도록 돕는 것이다.
컴퓨터가 이 연결 과정을 자동으로 처리할 수 있게 되면서, 거래 지형을 크게 변화시켰고, 온라인에서 전자적으로 처리되는 거래량은 기하급수적으로 증가하고 있다.
증권 거래소에는 뉴욕 증권 거래소(NYSE)나 나스닥 외에도 여러 유형의 거래소가 있다.
- 금융 산업의 수직적 세분화에 초점을 맞추고 기술적 측면을 강조하는 유형
- 공정성에 중점을 두는 유형
따라서 면접관에게 질문을 던져 거래소 규모 등 중요 특징을 먼저 확인해야한다.
1단계: 문제 이해 및 설계 범위 확정
현대적은 증권 거래소는 지연시간, 처리량, 안정성에 대한 요구사항이 엄격한 아주 복잡한 시스템이다.
- 간단하게 주식만 거래
- 새 주문을 넣을 수 있음
- 체결되지 않은 주문은 취소할 수도 있음
- 주문 유형은 지정가 주문만 가능
- 시갠 외 거래 지원 안함
- 새로운 지정가 주문 접수
- 기존 주문 취소
- 주문이 체결된 경우 실시간으로 그 사실을 알 수 있어야함
- 호가창(매수 및 매도 주문 목록 표시)
- 최소 수만 명 사용자가 동시에 거래할 수 있어야 함
- 최소 100가지 주식 거래가 가능해야함
- 하루에 수십억 거느이 주문이 발생할 수 있음
- 규제 시설이므로 위험성 점검이 가능해야함
- 위험성 점검
- 한 사용자가 하루에 거래할 수 있는 주식을 제한 등
- 거래 전 충분한 자금이 있는지 먼저 확인해야함
- 아직 체결되지 않은 주문이 있는 경우 해당 주문에 이용된 자금은 다른 주문에 쓰일 수 없음
비기능 요구사항
최소 100가지 주식, 수만 명 사용자같은 요구사항은 소규모에서 중간 규모 정도의 거래소를 설계해야 한다는 뜻이다.
많은 면접관이 후속 질문 과정에서 설계의 확장성을 확인하는 데 초점을 맞추므로 더 많은 주식과 사용자를 지원할 수 있게 확장 가능한 설계인지도 확인이 필요하다.
- 가용성: 최소 99.99%
- 거래소의 가용성은 매우 중요한 문제다. 단 몇초의 장애로도 평판이 크게 손상될 수 있다.
- 결함 내성:
- 프로덕션 장애의 파급을 줄이려면 결함 내성과 빠른 복구 매커니즘이 필요하다.
- 지연 시간:
- 왕복 지연 시간은 밀리초 수준이어야 하며, 특히 p99 지연 시간이 중요하다.
- p99 지연 시간이 계속 높으면 일부 사용자의 거래소 이용 경험이 아주 나빠진다.
- 보안: 거래소는 계정 관리 시스템을 갖추어야 한다.
- 법률 및 규정 준수를 위해 거래소는 새 계좌 개설 전 사용자의 신원 확인을 위한 KYC(Know Your Client) 확인을 수행한다.
- 시장 데이터가 포함된 웹 페이지 등의 공개 자원의 경우 DDoS 공격을 방지하는 장치를 구비해두어야 한다.
개략적 규모 추정
간단한 계산을 통해 개략적인 규모를 추정해보자.
- 100가지 주식
- 하루 10억 건의 주문
- 월요일 부터 금요일 까지, 오전 9시 30분부터 오후 4시까지 영업(총 6.5 시간)
QPS = 10억 / 6.5시간 * 3600 =~ 43,000최대 QPS = 5 * OPS = 215,000- 거래량은 장 시작 직후, 그리고 장 마감 직전에 훨씬 높다.
2단계: 개략적 설계안 제시 및 동의 구하기
설계안을 살펴보기 전, 거래소 설계에 도움이 될 몇 가지 기본 개념과 용어를 살펴본다.
증권 거래 101
브로커
대부분의 개인 고객은 브로커 시스템을 통해 거래소와 거래한다.
- ex) 찰스 슈왑(Charles Schwab), 로빈후드(Robinhood), E*Trade, 피델리티(Fidelity)
브로커 시스템은 개인 사용자가 증권을 거래하고 시장 데이터르 확인할 수 있도록 편리한 사용자 인터페이스를 제공한다.
기관 고객
기관 고객(institutional client)은 전문 증권 거래 소프트웨어를 사용하여 대량으로 거래한다.
기관 고객마다 거래 시스템에 대한 요구사항은 다르다.
- 연기금(pension funds): 안정적인 수익을 목표로 하므로 거래 빈도는 낮지만 거래량은 많음
- 대규모 주문이 시장에 미치는 영향을 최소화하기 위해 주문 분할 같은 기능을 필요로 함
- 헤지 펀드(hedge funds): 시장 조성을 전문으로 하며 수수료 리베이트를 통해 수익을 얻기 때문에 아주 낮은 응답 시간으로 거래하길 원함
일반 사용자처럼 웹페이지나 모바일 앱에서 시장 데이터를 확인하게 하면 곤란하다.
지정가 주문
지정가 주문(limit order)은 가격이 고정된 매수 또는 매도 주문이다.
시장가 주문과는 달리 체결이 즉시 이루어지지 않을 수 있고, 부분적으로만 체결될 수도 있다.
시장가 주문
시장가 주문(market order)은 가격을 지정하지 않는 주문으로, 시장가로 즉시 체결된다.
체결은 보장되나 비용 면에서는 손해를 볼 수 있다.
시장 데이터 수준
미국 주식시장에서는 L1, L2, L3 세 가지 가격 정보(price quote) 등급이 있다.
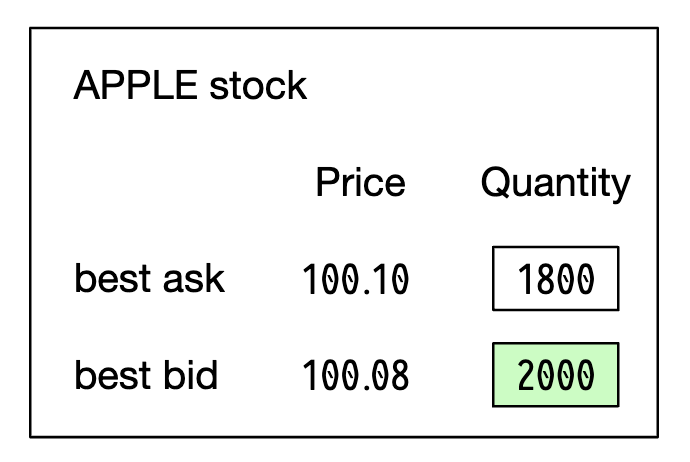

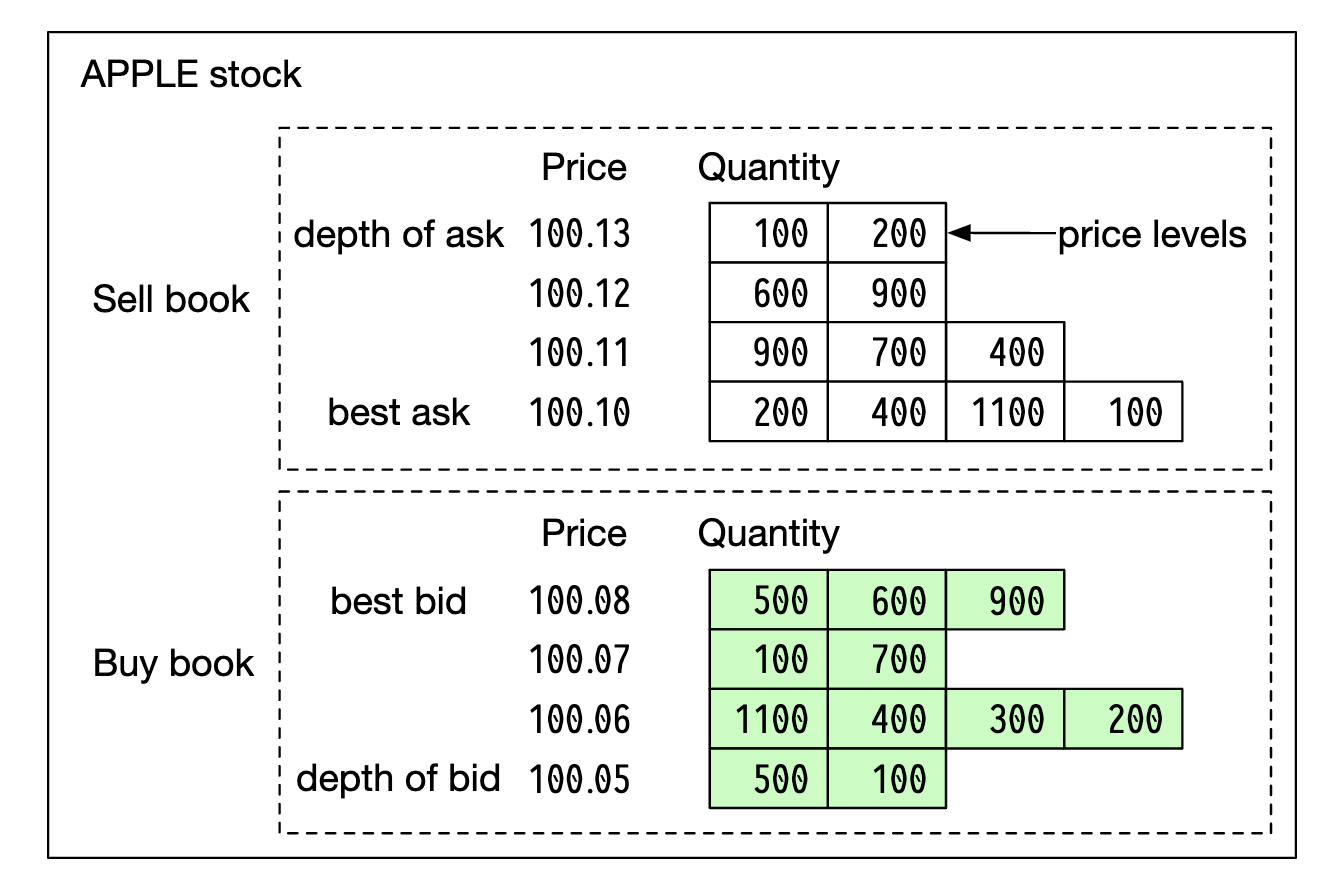
- L1: 최고 배호 호가(best bid price), 매도 호가(ask price) 및 수량(quantity)이 포함
- L2: L1에 더해 체결을 기다리는 물량의 호가를 보여줌, 어디 까지 보여줄 지를 의미하는 깊이(depth) 포함
- L3: 각 주문 가격에 체결을 기다리는 물량 정보까지 보여줌
봉 차트
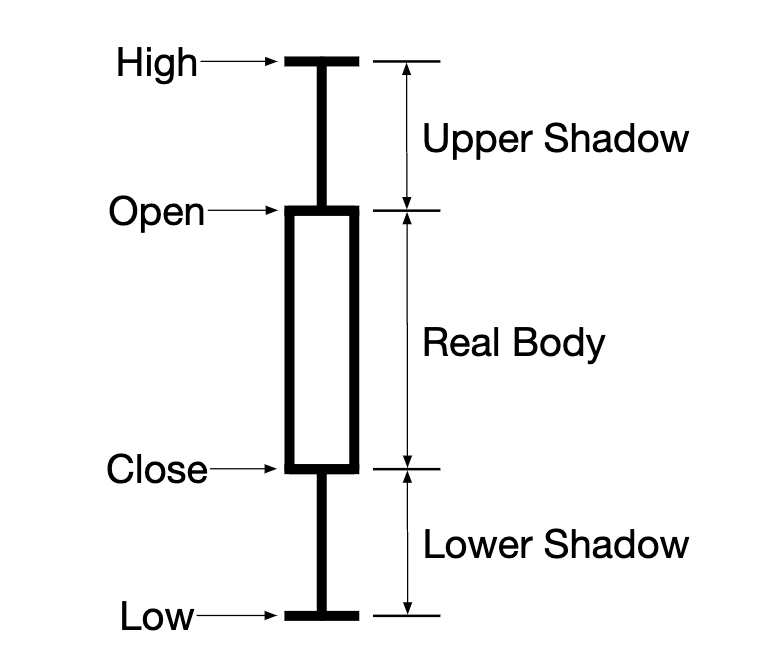
특정 기간 동안의 주가로 하나의 봉 막대로 일정 시간 간격 동안 시장의 시작가, 종가, 최고가, 최저가를 표시할 수 있다.
- 일반적으로 1분, 5분, 1시간, 1일, 1주일, 1개월 단위로 지원한다.
FIX
Financial Information Exchange Protocol(금융 정보 교환 프로토콜)의 약어로 증권 거래 정보 교환을 위한 기업 중립적 통신 프로토콜이다.
| |
개략적 설계안
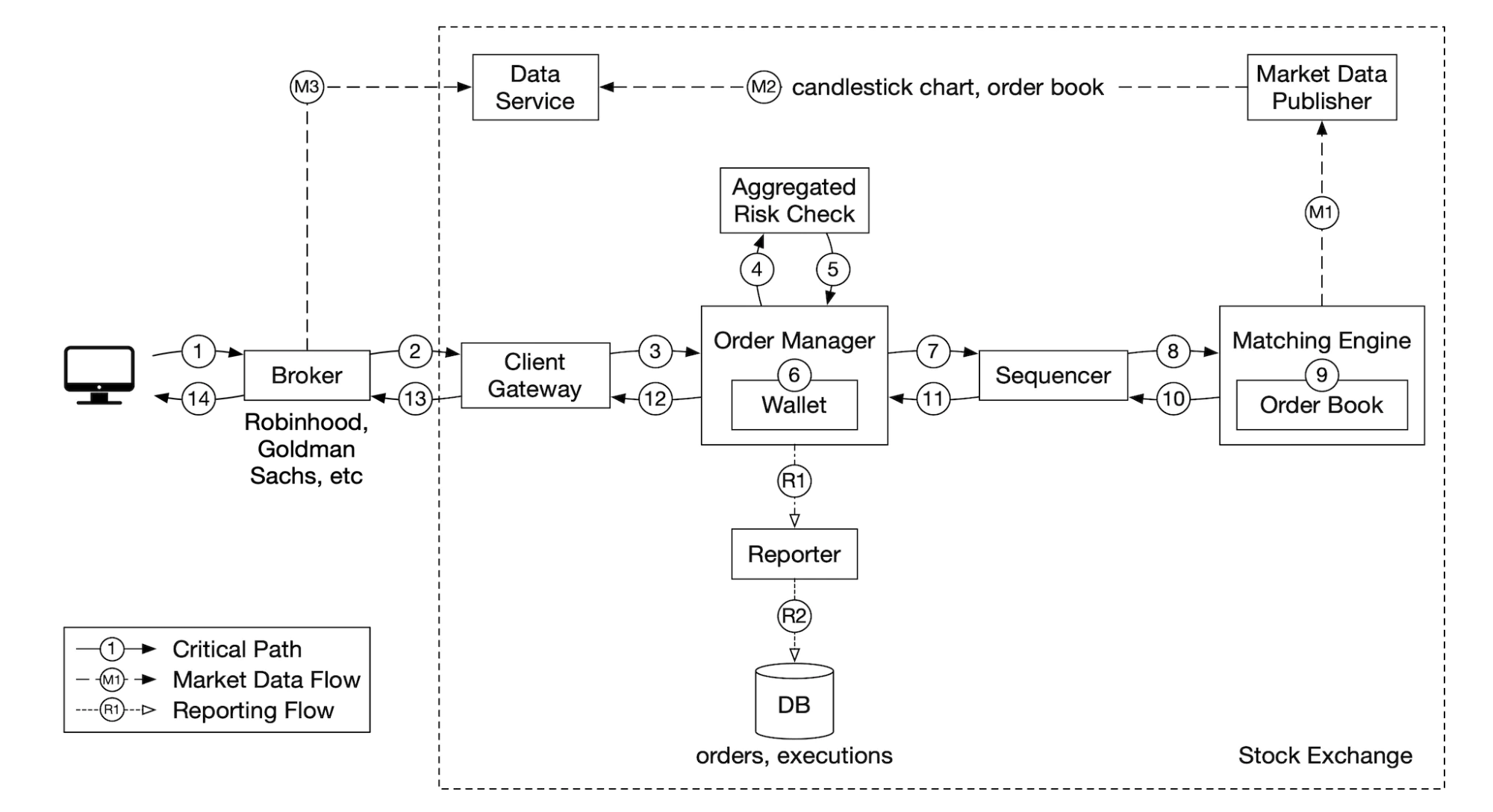
거래 흐름
거래 흐름(trading flow)을 통해 하나의 주문이 어떤 절차로 처리되는지 살펴본다.
지연 시간 요건이 엄격한, 중요 경로(critical path)로 이 경로를 따라 흐르는 모든 정보는 신속하게 처리되어야 한다.
- 1단계: 고객이 브로커의 웹 또는 모바일 앱을 통해 주문
- 2단계: 브로커가 주문을 거래소에 전송
- 3단계: 주문이 클라이언트 게이트웨이를 통해 거래소로 들어감
- 클라이언트 게이트웨이는 입력 유효성 검사, 속도 제한, 인증, 정규화 등과 같은 기본적인 게이트키핑 기능을 수행
- 그 후 주문을 주문 관리자에게 전달
- 4~5단계: 주문 관리자가 위험 관리자가 설정한 규칙에 다라 위험성 점검을 수행
- 6단계: 통과한 주문에 대해 지갑에 주문 처리 자금으 충분한지 확인
- 7~9단계: 주문이 체결 엔진으로 전송
- 체결 가능 주문이 발견되면 매수 측과 매도 측에 각각 하나씩 두 개의 집행(execution, fill(충족)이라고도 함) 기록 생성
- 그 과정을 재생할 때 항상 결정론적으로 동일한 결과가 나오도록 보장하기 위해 시퀀서는 주문 및 집행 기록을 일정 순서로 정렬
- 10~14단계: 주문 집행 사실을 클라이언트에 전송
시장 데이터 흐름
시장 데이터 흐름(market data flow)을 따라서 하나의 주문이 체결 엔진부터 데이터 서비스를 거쳐 브로커로 전달되어 집행되기까지의 과정을 추적해본다.
- M1 단계: 체결 엔진은 주문이 체결되면 집행 기록 스트림(또는 충족 기록 스트림)을 만든다.
- 시장 데이터 게시 서비스로 전송된다.
- M2 단계: 시장 데이터 게시 서비스는 집행 기록 및 주문 스트림에서 얻은 데이터를 시장 데이터로 사용하여 봉 차트와 호가 창을 구성한다.
- 시장 데이터를 데이터 서비스로 보낸다.
- M3 단계: 실시간 분석 전용 스토리지에 저장된다.
- 브로커는 데이터 서버스를 통해 실시간 시장 데이터를 읽는다.
- 읽은 데이터를 고객에게 전달한다.
보고 흐름
- R1 ~ R2 단계: 보고 서비스(reporter)는 주문 및 실행 기록에서 보고에 필요한 모든 필드의 값을 모은다음 그 값을 종합해 만든 레코드를 데이터베이스에 기록한다.
- ex)
client_id,price,quantity,order_type,filled_quantity,remaining_quantity등
- ex)
거래 흐름은 중요 경로를 따라 진행되지만 시장 데이터 흐름이나 보고 흐름은 지연 시간 요구사항이 다르다.
거래 흐름
거래 흐름은 거래소의 중요 경로상에서 진행된다.
체결 엔진
체결 엔진(matching engine)은 교차 엔진(cross engine)이라고도 부르며, 주요 역할은 다음과 같다.
- 각 주식 심벌에 대한 주문서(order book) 내지 호가 창을 유지 관리
- 특정 주식에 대한 매수 및 매도 주문 목록
- 매수 주문과 매도 주문을 연결
- 주문 체결 결과로 두 개의 집행 기록이 만들어짐(매수 1, 매도 1)
- 체결은 빠르고 신속하게 처리되어야 한다.
- 집행 기록 스트림을 시장 데이터로 배포
가용성 높은 체결 엔진 구현체가 만드는 체결 순서는 결정론적(deterministic)이어야 한다.
- 입력으로 주어지는 주문 순서가 같으면 체결 엔진이 만드는 집행 기록 순서는 언제나 동일해야 함
시퀀서
시퀀서(sequencer)는 체결 엔진을 결정론적으로 만드는 핵심 구성 요소이다.
- 주문을 전달하기 전 순서 ID를 붙여 보냄
- 처리를 끝낸 모든 집행 기록 쌍에도 순서 ID를 붙임
즉 입력 시퀀서와 출력 시퀀서 두 가지가 각각 고유한 순서를 유지하며, 시퀀서가 만드는 순서 ID는 누락된 항목을 쉽게 발견할 수 있는 일련번호여야 한다.
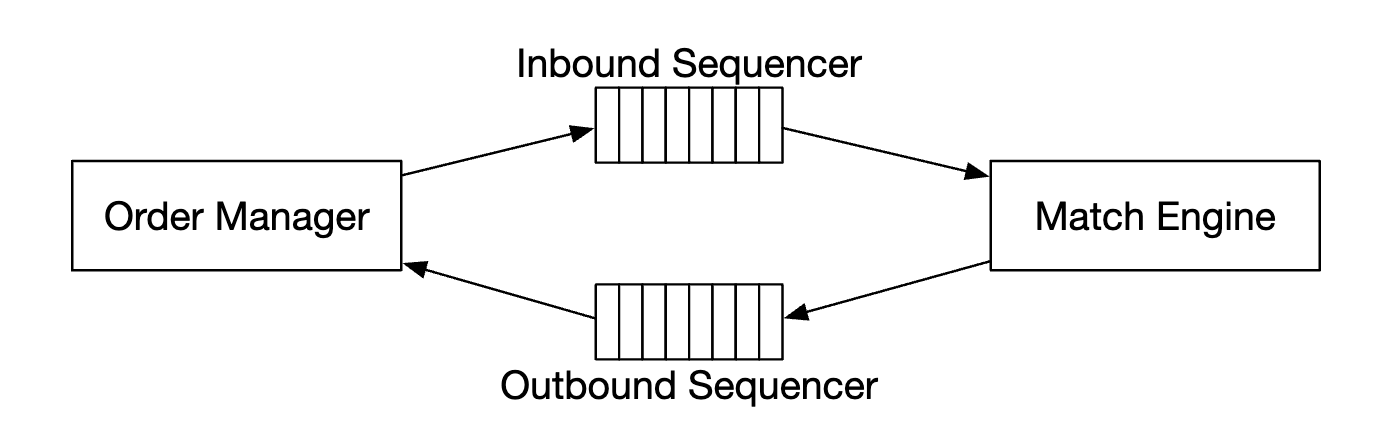
입력되는 주문과 출력하는 실행 명령에 순서 ID를 직는 이유는 다음과 같다.
- 시의성(timeliness) 및 공정성(fairness)
- 빠른 복구(recovery) 및 재생(replay)
- 정확한 1회 실행 보증(exactly-once guarantee)
시퀀서는 순서 ID만 생성하는 것이 아닌 메시지 큐 역할도 한다.
- 체결 엔진에 메시지(수신 주문)를 보내는 큐
- 주문 관리자에게 메시지(집행 기록)를 회신하는 큐
주문과 집행 기록을 위한 이벤트 저장소로 볼 수도 있다.
- 체결 엔진에 두 개 카프카 이벤트 스트림이 연겨로디어 있는 것과 비슷함
- 입력되는 주문용, 출력될 집행 기록용
주문 관리자
주문 관리자(order manager)는 한쪽에서 주문을 받고 다른 쪽에서는 집행 기록을 받아 주문 상태를 관리하는 것이 역할이다.
주문 관리자는 클라이언트 게이트웨이를 통해 주문을 수신하고 다음을 실행한다.
- 위험성 검토
- ex) 사용자의 거래량이 하루 100만 달라 미만인지?
- 충분한 자금이 있는지 확인
- 주문을 시퀀서에 전달
- 해당 주문에 순서 ID를 찍고 체결 엔진에 보내어 처리함
- 메시지 크기를 줄이기 위해 많은 속성 중 필요한 속성만 전송
주문 관리자는 시퀀서를 통해 체결 엔진으로 부터 집행 기록도 받는데, 체결된 주문에 대한 집행 기록을 클라이언트 게이트웨이를 통해 브로커에 반환한다.
주문 관리자는 빠르고 효율적이며 정확해야 한다.
- 주문 관리자는 주문의 현재 상태를 유지관리 해야하므로 다양한 상태 변화를 관리해야하는 문제 때문에 구현이 아주 복잡하다.
- 이벤트 소싱은 주문 관리자 설계에 적함하다.
클라이언트 게이트웨이
거래소의 문지기 역할로 클라이언트로부터 주문을 받아 주문 관리자에게 보낸다.
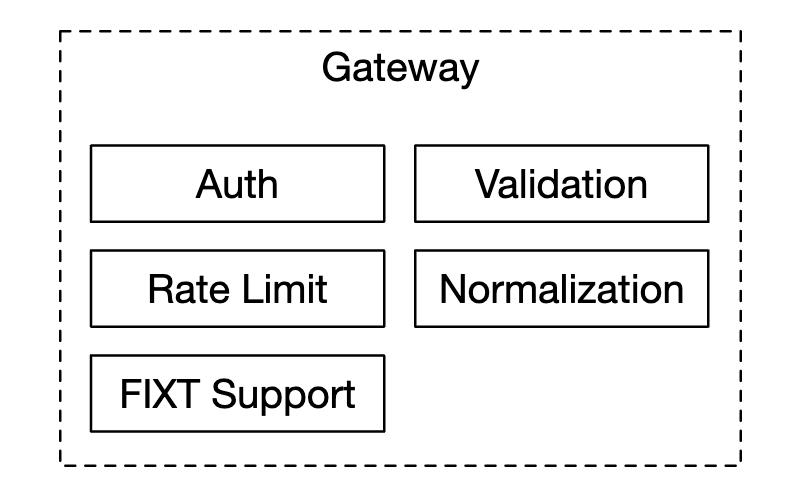
클라이언트 게이트웨이는 중요 경로상에 놓이므로 지연 시간에 중요한 기능들을 신속하게 처리하여 가능한 한 빨리 올바른 목적지로 주문을 전달해야 한다.
따라서 어떤 기능을 클라이언트 게이트웨이에 넣을지 말지는 타협적으로 생각해야한다.
- 복잡한 기능이라면 체결 엔진이나 위험 점검 컴포넌트에 맡겨야 한다.
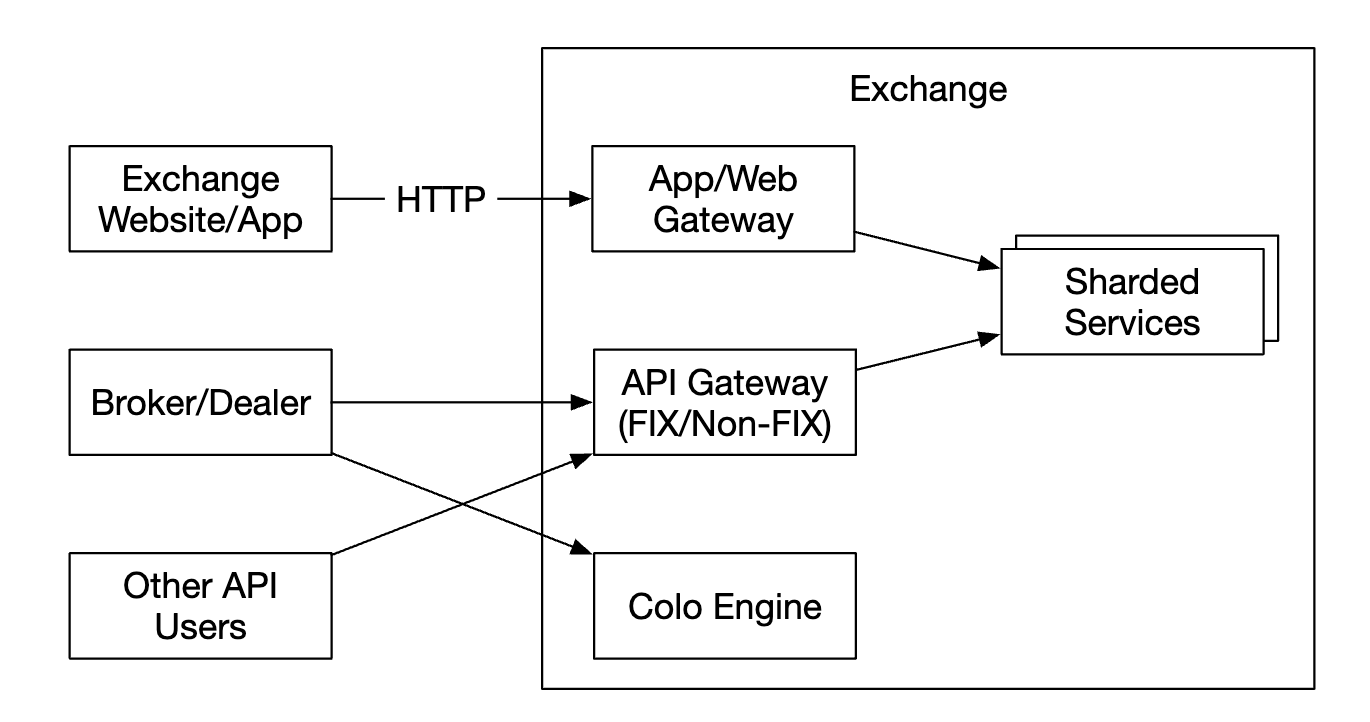
고객 유형별(개인/기업)로 지연 시간, 거래량, 보안 요구사항 등 고려사항이 다르므로 클라이언트 게이트웨이도 다양해질 수 있다.
- ex) 시장 조성자(market maker)는 거래소에 유동성의 상당 부분을 공급하므로 매우 낮은 지연 시간을 요구한다.
극단적인 사례인 코로케이션(colocation, colo) 엔진은 브로커가 거래소 데이터 센터에서 임대한 서버 일부에서 실행하는 거래 엔진 소프트웨어로 지연시간이 빛의 속도 정도이다.
시장 데이터 흐름
시장 데이터 게시 서비스(Market Data Publisher, MDP)는 체결 엔진에서 집행 기록을 수신하고 집행 기록 스트림에서 호가 창과 봉 차트를 만들어 낸다.
- 호가 창과 봉 차트를 통칭하여 시장 데이터라고 한다.
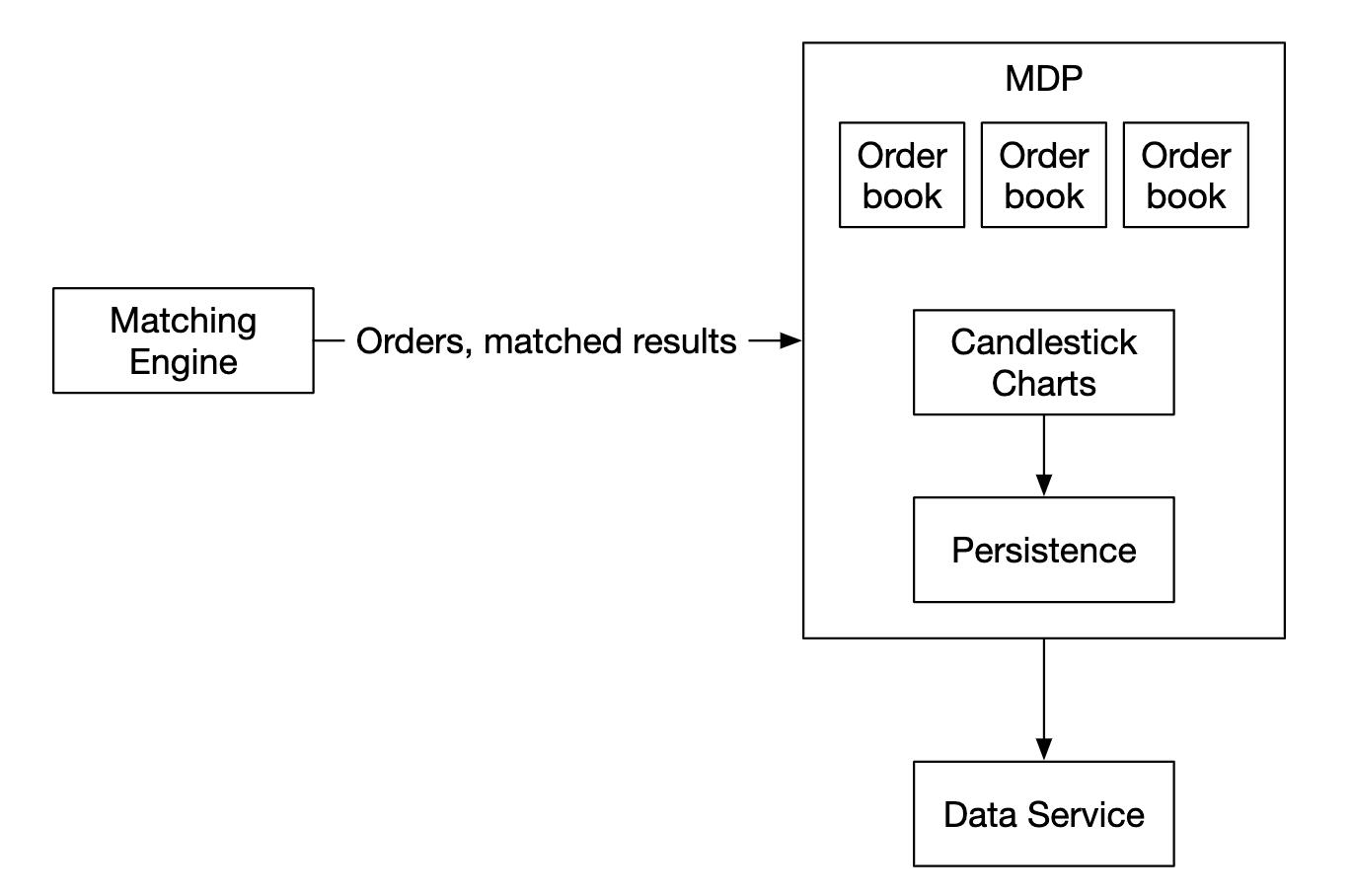
시장 데이터는 데이터 서비스로 전송되어 해당 서비스의 구독자가 사용할 수 있게 된다.
보고 흐름
거래소에서 필수적인 부분 가운데 하나로, 보고 서비스는 거래의 중요 경로상에 있지는 않지만 여전히 시스템의 중요한 부분이다.
- 거래 이력, 세금 보고, 규정 준수 여부 보고, 결산(settlement) 등의 기능 제공
거래 흐름과 달리 보고 서비스는 정확성과 규정 준수가 핵심적이다.
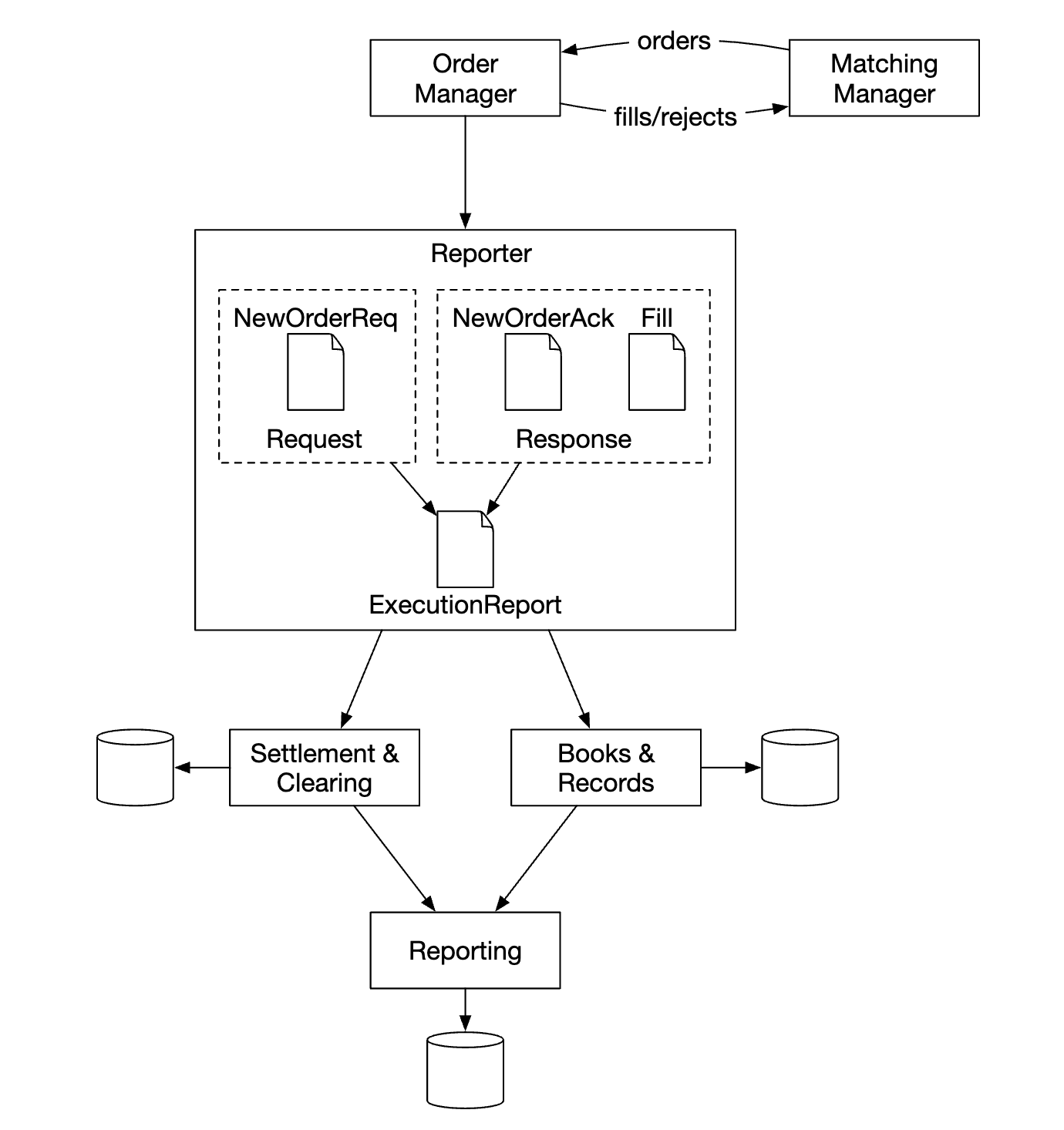
입력으로 들어오는 주문과 그 결과로 나가는 집행 기록 모두에서 정보를 모아 속성(attributes)를 구성하는 것이 일반적 관행이다.
- 새 주문은 주문 세부 정보만 포함
- 집행 기록에는 주문 ID, 가격, 수량 및 집행 상태 정보만 포함
보고 서비스는 두 가지 출처에서 오는 정보를 잘 병합하여 보고서를 만든다.
API 설계
고객은 브로커를 통해 증권 거래소와 상호 작용하여 주문, 체결 조회, 시장 데이터 조회, 분석을 위한 과거 데이터 다운로드 등을 수행한다.
브로커와 클라이언트 게이트웨이 간의 인터페이스 명세 작성에는 RESTful 컨벤션을 사용한다.
- RESTful API로는 지연 시간 요구사항을 충족하지 못할 수도 있어 다른 프로토콜을 사용할 가능성이 높지만, 어떤 프로토콜도 아래 언급한 기본 기능은 동일하게 제공되어야 한다.
주문
| |
주문을 처리하며, 인증이 필요하다.
- 인자
symbol: 주식을 나타내는 심볼side: 매수 또는 매도price: 지정가 주문 가격orderType: 지정가 또는 시장가quantity: 주문 수량
- 응답
id: 주문 IDcreationTime: 주문이 시스템에 생성된 시간filledQuantity: 집행이 완료된 수량remainingQuantity: 아직 체결되지 않은 주문 수량status: new/canceled/filled
- 코드
200: 성공40x: 인자 오류/접근 불가/권한 없음500: 서버 오류
집행
| |
집행 정보를 질의하며 인증이 필요하다.
- 인자
symbol: 주식 심볼orderId: 주문 ID(optional)startTime: 질의 시작 시간endTime: 질의 종료 시간
- 응답 본문
executions: 범위 내의 모든 집행 기록 배열id: 집행 기록orderId: 주문 IDsymbol: 주식 심볼side: 매수 혹은 매도price: 체결 가격orderType: 지정가 도는 시장가quantity: 체결 수량
- 응답 코드
200: 성공40x: 인자 오류/해당 자원 없음/접근 불가/권한 없음500: 서버 오류
가격 변동 이력(캔들 차트)
| |
주어진 시간 범위, 해상도(resolution), 심볼에 대한 봉 차트 데이터 질의 결과를 반환
- 인자
symbol: 심볼resolution: 윈도 길이startTime: 질의 시작 시간endTime: 질의 종료 시간
- 응답 본문
candles: 각 봉의 데이터를 담은 배열open: 해당 봉의 시가close: 해당 봉의 종가high: 해당 봉의 고가low: 해당 봉의 저가
- 응답 코드
200: 성공40x: 인자 오류/해당 자원 없음/접근 불가/권한 없음500: 서버 오류
데이터 모델
증권 거래소에는 세 가지 유형의 주요 데이터가 있다.
상품, 주문, 집행
상품
상품(product)은 거래 대상 주식(심벌)이 가진 속성으로 정의된다.
- 상품의 유형, 거래에 쓰이는 심벌, UI에 표시될 심벌, 결산에 이용되는 통화 단위, 매매 수량 단위(lot size), 호가 가격 단위(tick size) 등
자주 변경되지 않고 주로 UI 표시를 위한 데이터이므로, 아무 데이터베이스에나 저장 가능하며, 캐시를 적용하기에도 좋다.
주문, 집행
주문은 매수 또는 매도를 실행하라는 명령이며, 집행 기록은 체결이 이루어진 결과이다.
- 집행 기록은 충족(fill)이라고도 부름
모든 주문이 집행되지는 않으며, 체결 엔진은 하나의 주문 체결에 관여한 매수 행위와 매도 행위를 나타내는 두 개의 집행 기록을 결과로 출력한다.
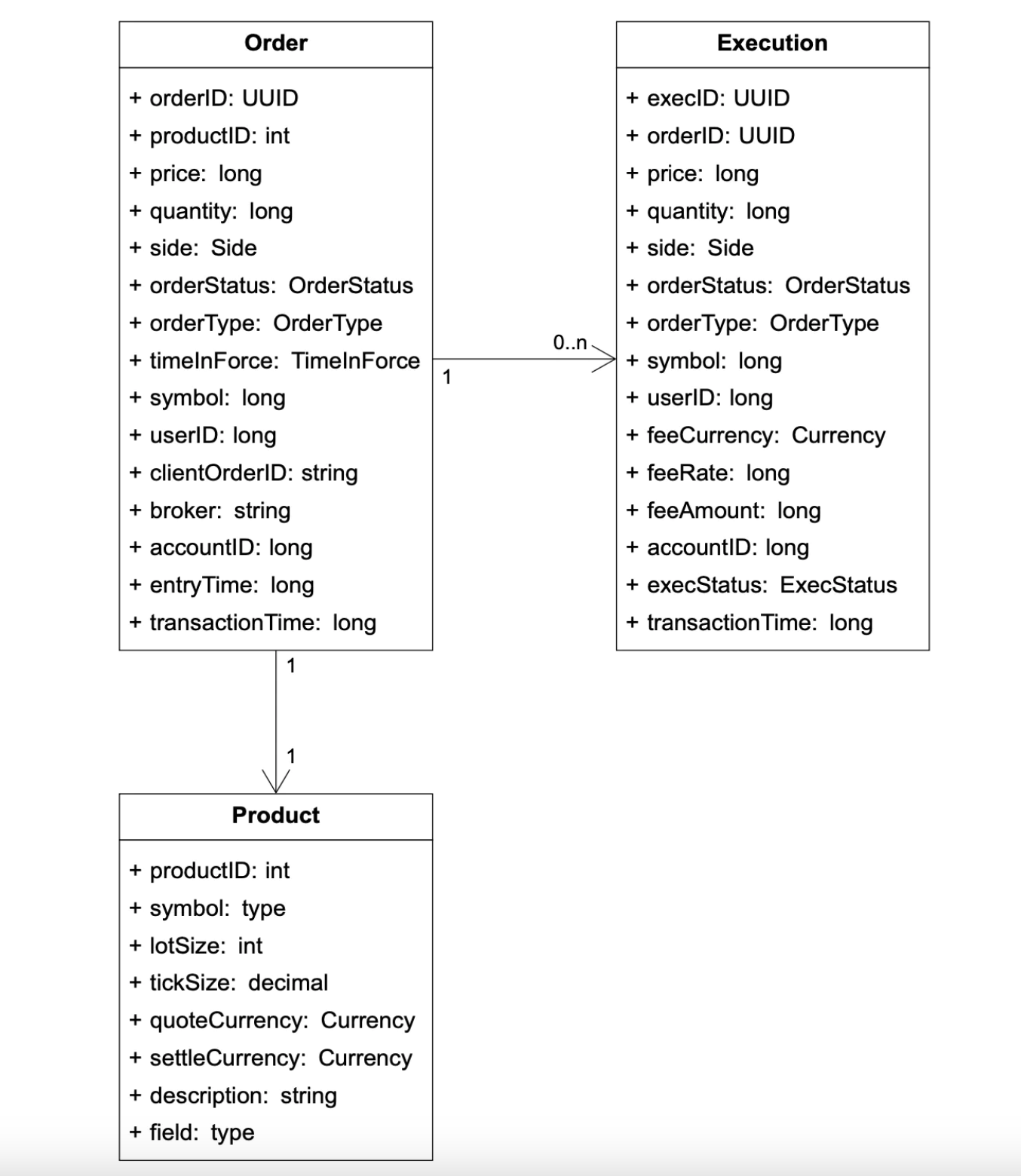
주문과 집행 기록은 거래소가 취급하는 가장 중요한 데이터이다.
- 중요 거래 경로는 주문 과 집행 기록을 데이터베이스에 저장하지 않는다.
- 성능을 높이기 위해 메모리에서 거래를 체결하고 하드디스크다 공유 메모리를 활용하여 주문과 집행 기록을 저장하고 공유한다.
- 빠른 복구를 위해 시퀀서에 저장하며, 데이터 보관은 장 마감 후에 실행한다.
- 보고 서비스는 조정이나 세금 보고 등을 위해 데이터베이스에 주문 및 집행 기록을 저장한다.
- 집행 기록은 시장 데이터 프로세서로 전달되어 호가 창/주문서와 봉 차트 데이터 재고성에 쓰인다.
호가 창
호가 창은 특정 증권 또는 금융 상품에 대한 매수 및 매도 주문 목록으로, 가격 수준별로 정리되어 있다.
체결 엔진이 빠른 주문 체결을 위해 사용하는 핵심 자료구조로, 다음 요구사항을 만족할 수 있는 효율성이 높은 것 이어야한다.
- 일정한 조회 시간:
- 특정 가격 수준의 주문량 조회
- 특정 가격 범위 내의 주문량 조회 등
- 빠른 추가/취소/실행 속도: 가급적
O(1)시간 복잡도를 만족해야 한다.- 새 주문 넣기, 기존 주문 취소하기, 주문 체결하기 등
- 빠른 업데이트:
- 주문 교체 등
- 최고 매수 호가/최저 매수 호가 질의
- 가격 수준 순회(iteration)
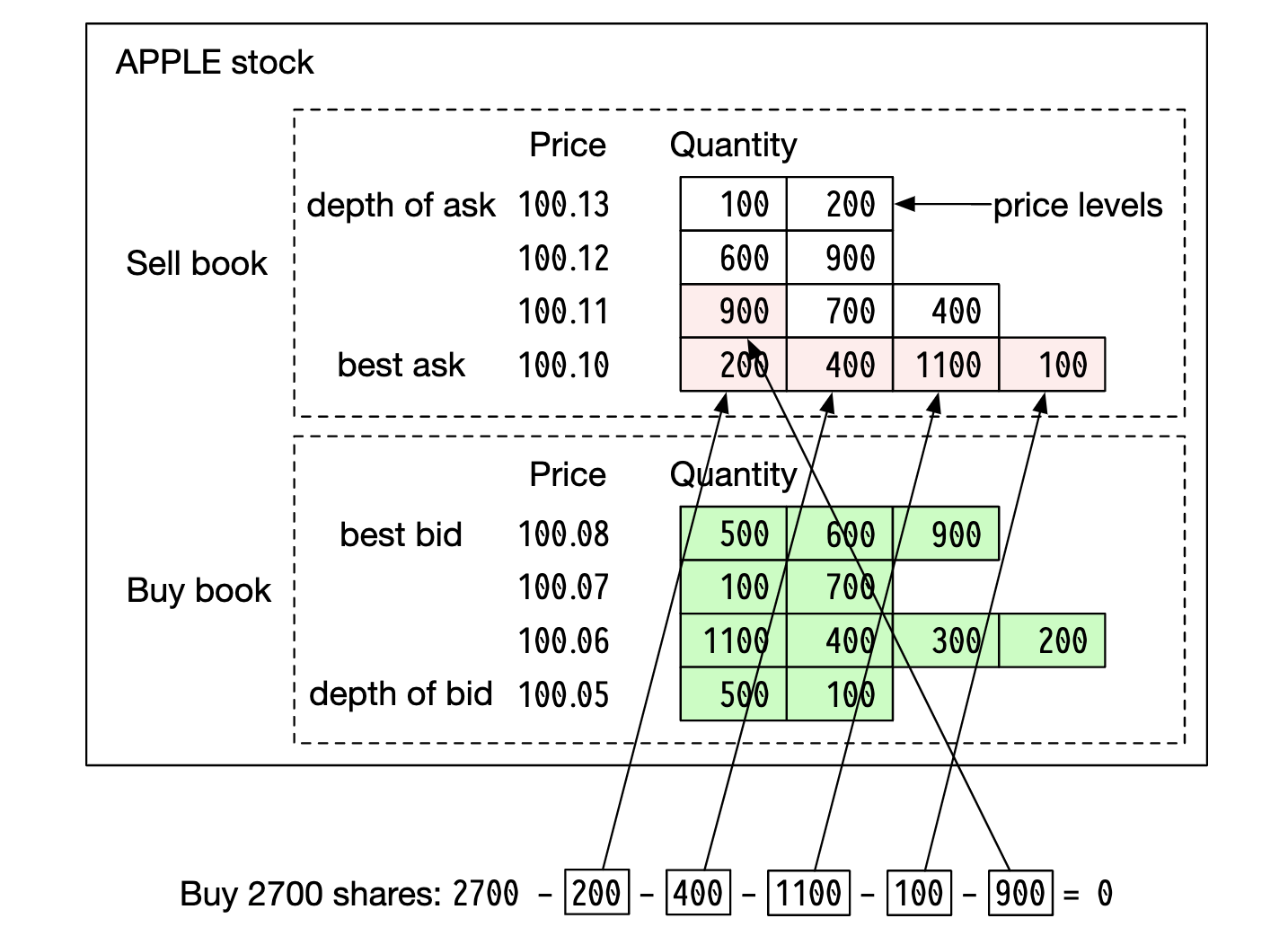
예제에서 최저 매도 호가 큐의 모든 매도 주문과 체결된 후에 호가 100.11 큐의 첫 번째 매도 주문과 체결되며 거래가 끝난다.
이 결과로 매수/매도 호가 스프레드 간의 가격 차이가 넓어지고 주식 가격은 한 단계 상승하게된다.
| |
일반 연결 리스트를 사용하고 있으므로 모든 설계 요구사항을 만족할 수 없다.
- ex) 지정가 주문 추가/취소는
O(1)이 아님
보다 효율적인 호가 창을 만들려면 orders의 자료 구조는 이중 연결 리스트로 변경하여 모든 삭제 연산(주문 취소나 체결 처리 등)이 O(1)에 처리되도록 해야한다.
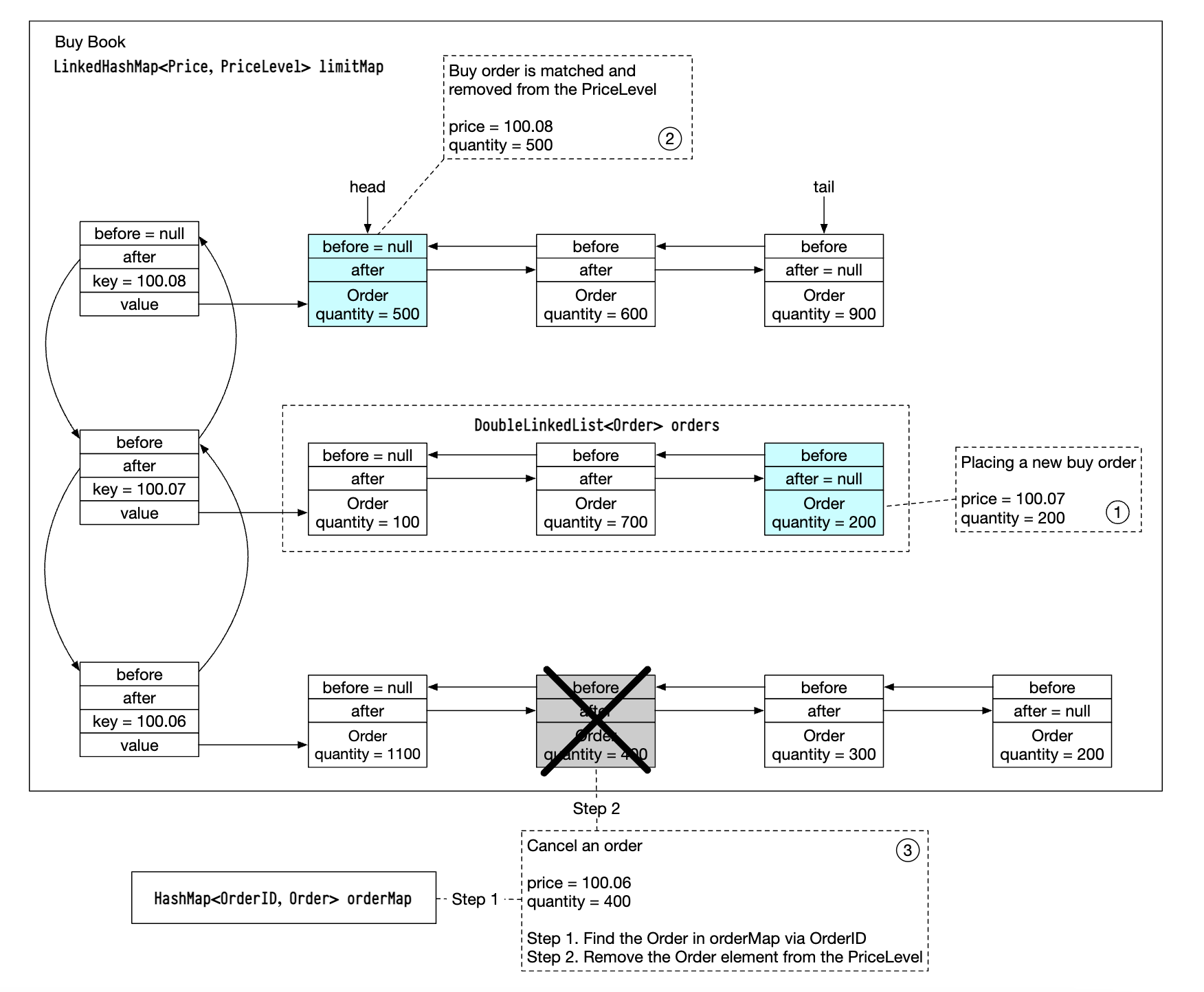
- 새 주문은
PriceLevel리스트 마지막에 새Order추가를 의미(O(1)) - 주문 체결은
PriceLevel리스트 맨 앞에Order삭제를 의미(O(1)) - 주문 취소는
OrderBook에서Order삭제를 의미(O(1))OrderBook내의 핼퍼 자료 구조Map<OrderID, Order> orderMap을 활용하면O(1)시간으로 취소할 주문을 찾을 수 있음- 이중 연결 리스트이므로
Order의 이전 주문을 가르키는 포인터가 있으므로 전체 주문 목록을 순회하지 않고 주문을 삭제할 수 있음
호가 창 자료 구조는 집행 기록 스트림에서 L1, L2, L3 데이터를 재구성 하기 위해 시장 데이터 프로세서도 많이 사용하게된다.
봉 차트
봉 차트는 시장 데이터 프로세서가 시장 데이터를 만들 때 호가 창과 더불어 사용하는 핵심 자료구조이다.
봉 차트를 모델링 하기 위해서 Candlestick 클래스와 CandlestickChart 클래스를 사용한다.
| |
하나의 봉이 커버하는 시간 범위가 경과하면 다음 주기를 커버할 새 Candlestick 클래스 객체를 생성하여 CandlestickChart 객체의 내부 연결 리스트에 추가한다.
봉 차트에서 많은 종목의 가격 이력을 다양한 시간 간격을 사용해 추적하려면 메모리가 많이 필요하므로 다음과 같은 방법을 고려할 수 있다.
- 미리 메모리를 할당해 둔 링(ring) 버퍼에 봉을 보고나하면 새 객체 할당 횟수를 줄일 수 있다.
- 메모리에 두는 봉의 개수를 제한하고 나머지는 디스크에 보관한다.
시장 데이터는 일반적으로 실시간 분석을 위해 메모리 상주 칼럼형 데이터베이스(KDB) 에 둔다.
- 시장이 마감된 후에는 데이터를 이력 유지 전용 데이터베이스에도 저장
3단계: 상세 설계
현대의 거래소는 진화하여 하나의 거대 서버로 거의 모든 것을 운영하는 형태로 발전했다.
성능
거래소는 평균 지연 시간은 낮아야 하고, 전반적인 지연 시간 분포는 안정적이어야 한다.
- 지연 시간이 안정적인지 보는 좋은 척도는 P99(99% 백분위수) 지연시간이다.
지연 시간을 줄이는 방법에는 대표적으로 두 가지 방법이 있다.
- 중요 경로에서 실행할 작업 수를 줄인다.
- 각 작업의 소요 시간을 줄인다.
- 네트워크 및 디스크 사용량 경감
- 각 작업의 실행 시간 경감
중요 경로 최적화
중요 경로에는 꼭 필요한 구성 요소만 둔다.
- 로깅도 지연 시간을 줄이기 위해 중요 경로에서는 뺀다.
작업 소요시간 최적화
핵심 경로의 구성요소가 네트위커를 통해 연결된 개별 서버에서 실행된다고 가정하면, 왕복 네트워크 지연 시간은 약 500마이크로 초 이므로 핵심 경로에 네트워크를 통해 통신하는 컴포넌트가 많으면 지연 시간은 한 자릿수 밀리초 까지 늘어난다.
또한 시퀀서는 이벤트를 디스크에 저장하는 이벤트 저장소로 순차적 쓰기의 성능 이점을 활용하여 효율적으로 설계한다 해도 디스크 엑세스 지연 시간은 여전히 수십 밀리초 단위이다.
네트워크 및 디스크 엑세스 지연 시간을 모두 고려하면 총 단대단(end-to-end) 지연 시간은 수십 밀리초에 달한다.
거래소는 주로 네트워크 및 디스크 액세스 지연 시간을 줄이거나 없애는 방안을 통해 중요 경로의 단대단 지연 시간을 수십 마이크로초로 줄였다.
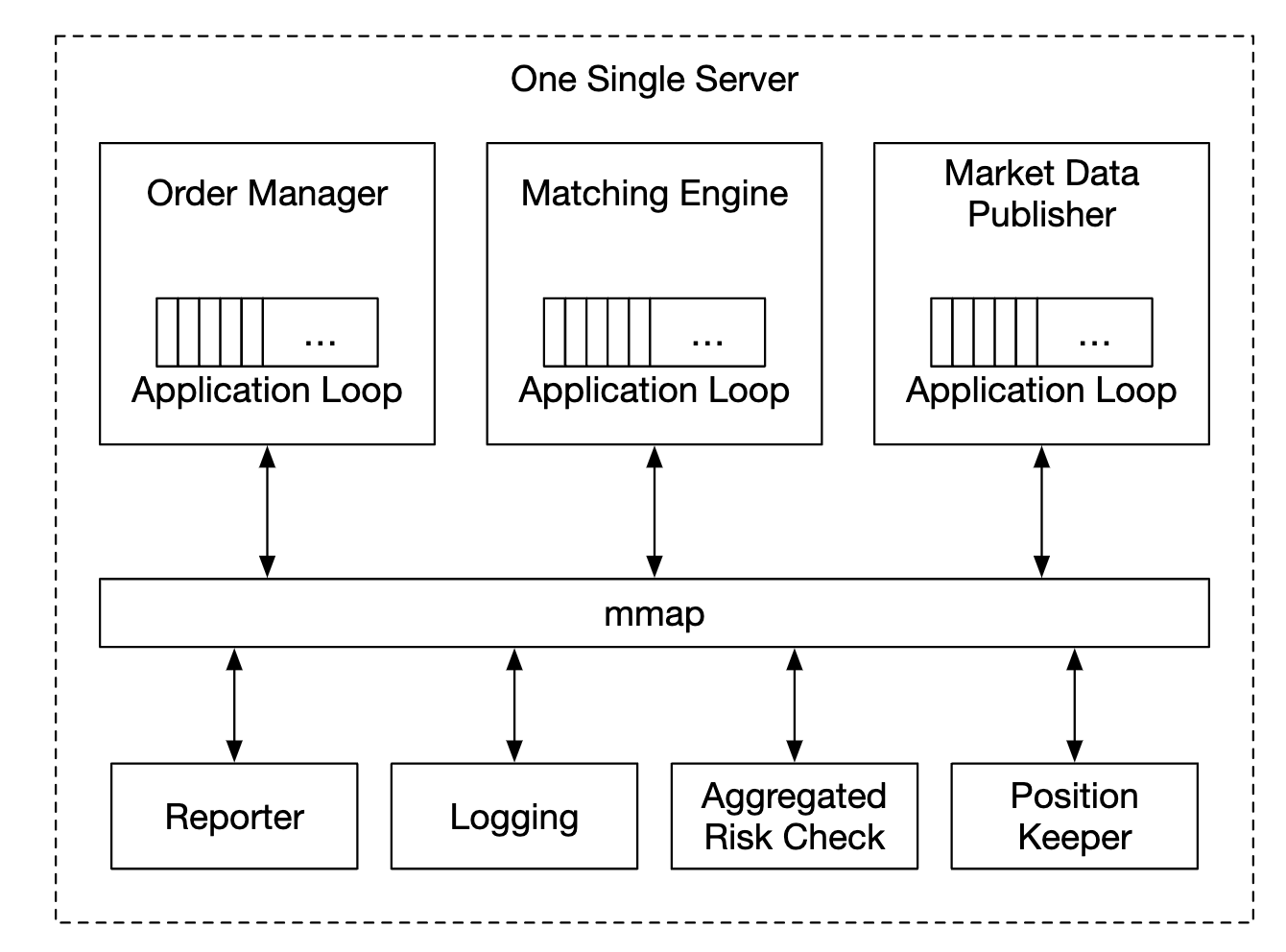
모든 것을 동일한 서버에 배치하여 네트워크를 통하는 구간을 없애고, 컴포넌트 간 통신은 이벤트 저장소인 nmap을 통한다.
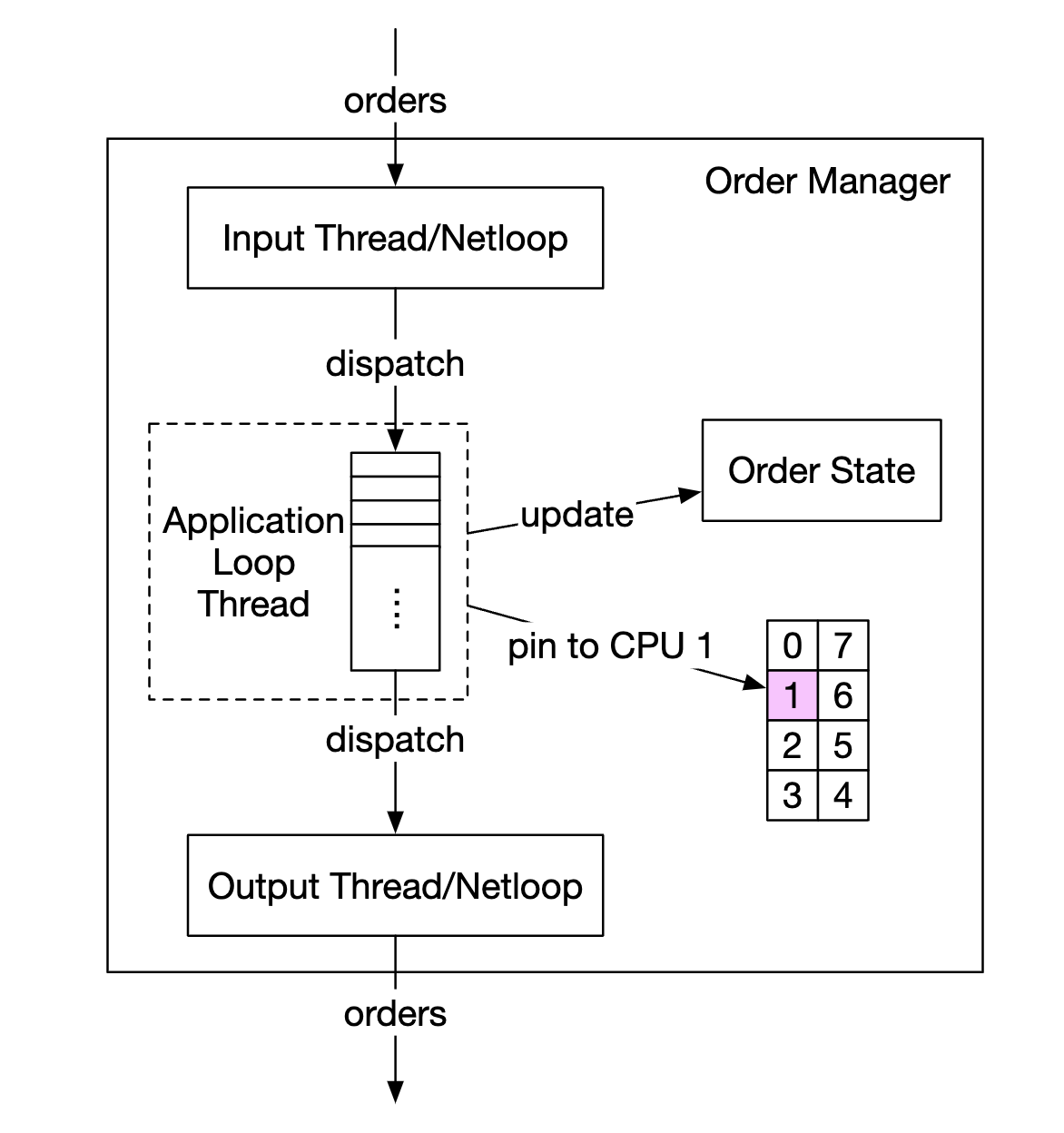
애플리케이션 루프의 주된 작업 실행 매커니즘은 while 순환문을 통해 실행할 작업을 계속 폴링한다.
- 엄격한 지연 시간 요건을 만족하려면 목적 달성에 가장 중요한 작업만 이 순환문 안에서 처리해야한다.
이 매커니즘의 폭표는 각 구성 요소의 실행 시간을 줄여 전체적인 실행 시간이 예측 가능하도록(ex. p99 지연 시간을 닞추어) 보장하는 것 이다.
컴포넌트는 서버의 프로세스로 CPU 효율성을 극대화 하기 위해 애플리케이션 루프는 단일 스레드로 구현하며, 특정 CPU 코어에 고정시킨다.
애플리케이션 루프를 CPU에 고정하면 상당한 이점이 있다.
- 컨텍스트 스위치가 없다.
- CPU가 주문 관리자의 애플리케이션 루프 처리에 온전히 할당된다.
- 상태를 업데이트하는 스레드가 하나뿐이라서 락을 사용할 필요가 없다.
- 잠금 경합(lock contention)도 없다.
CPU를 고정하는 방법의 단점은 코딩이 더 복잡해진다는 것이다.
- 엔지니어는 각 작업이 애플리케이션 루프 스레드를 너무 오래 점유하지 않도록 각 작업에 걸리는 시간을 신중하게 분석하여 후속 작업이 제때 실행될 수 있도록 해야한다.
mmap은 파일을 프로세스의 메모리에 매핑하는 mmap(2)라는 이름의 POSIX 호환 UNIX 시스템 콜을 일컫는다.
mmap(2)은 프로세스 간 고성능 메모리 공유 메커니즘을 제공하며, 메모리에 매핑할 파일이 메모리 기반 파일 시스템인 /dev/shm에 있을 때 성능 이점은 더욱 커진다.
/dev/shm에 있는 파일에mmap(2)을 수행하면 공유 메모리에 접근해도 디스크 I/O는 발생하지 않는다.
서버에서 mmap(2)를 사용하여 중요 경로에 놓인 구성 요소가 서로 통신할 때 이용할 메시지 버스를 구현하여 가능한 한 디스크 접근이 일어나지 않도록 한다.
- 이 통신 경로를 사용하면 네트워크나 디스크에 접근하는 일은 없다.
- 메시지 전송에 마이크로 초 미만의 시간이 걸린다.
이와 같은 이벤트 저장소에 이벤트 소싱 설계 패러다임을 결합하면 서버에 지연 시간이 낮은 마이크로서비스들을 구축할 수 있게 된다.
이벤트 소싱
전통적인 애플리케이션은 상태를 데이터베이스에 유지하기 때문에 문제가 발생하면 원인을 추적하기 어렵다.
- 데이터베이스는 현재 상태만 유지할 뿐, 현재 상태를 초래한 이벤트의 기록은 없기 때문
이벤트 소싱 아키텍처는 현재 상태를 저장하는 대신 상태를 변경하는 모든 이벤트의 변경 불가능한(immutable) 로그를 유지한다.
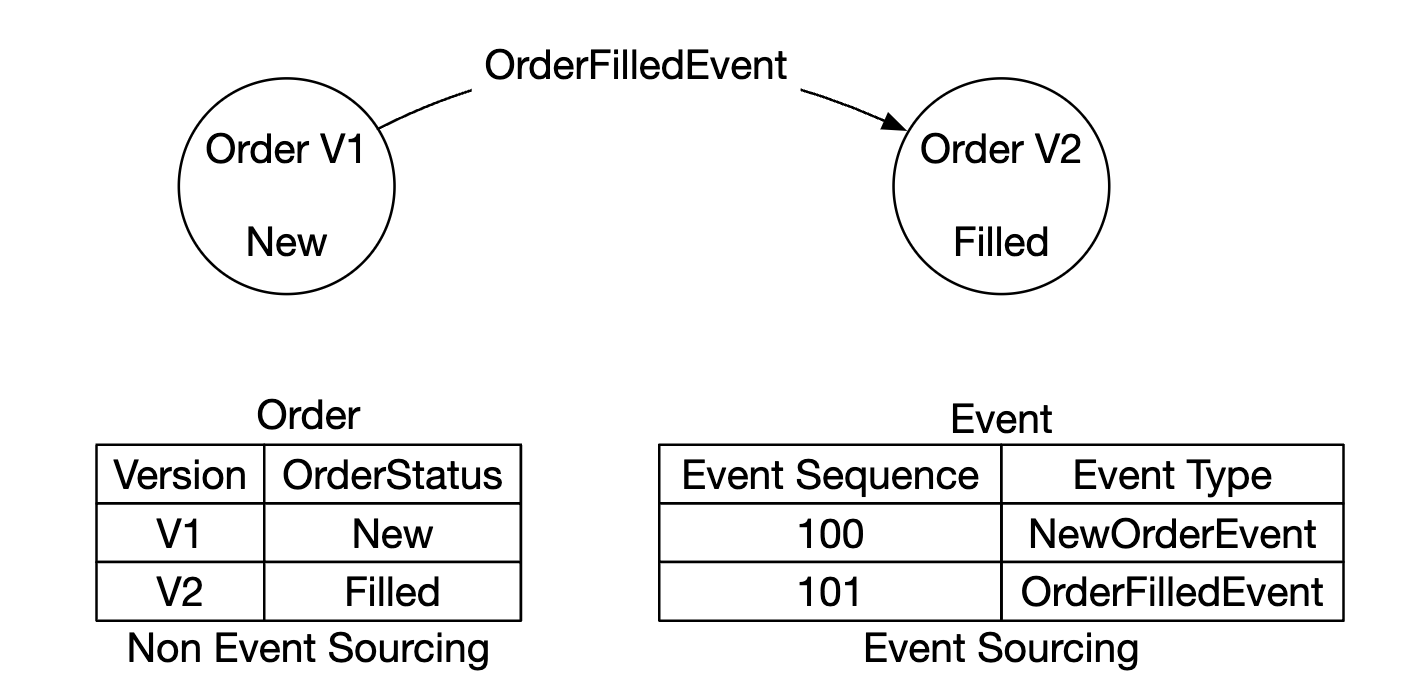
이벤트 소싱 아키텍처는 모든 이벤트를 추적하므로, 모든 이벤트를 순서대로 재생하면 주문 상태를 복구할 수 있다.
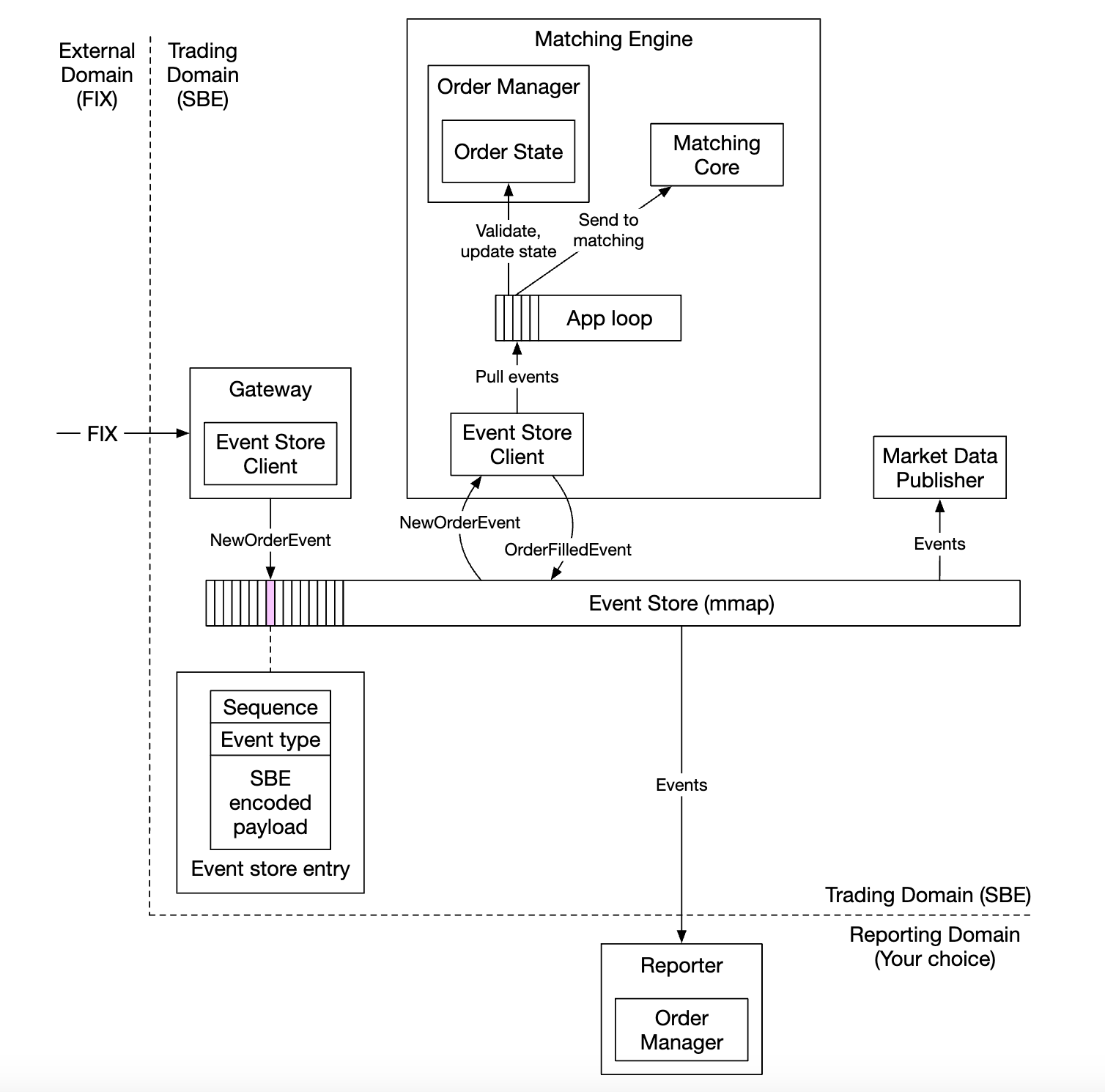
mmap 이벤트 저장소를 메시지 버스로 사용하는 이벤트 소싱 설계안으로, 카프카의 펍섭(pub-sub) 모델과 아주 비슷하다. (지연 시간에 대한 엄격한 요구사항만 없었으면 카프카를 사용할 수도 있다.)
- 게이트웨이는 빠르고 간결한 인코딩을 위해 FIX를 SBE(Fix over Simple Binary Encoding)로 변환하고, 각 주문을 이벤트 저장소 클라이언트를 사용하여 미리 정의된 형식의
NewOrderEvent형태로 전송한다. - 체결 엔진에 내장된 주문 관리자는 이벤트 저장소로부터
NewOrderEvent를 수신하면 유효성 검사한 다음 내부 주문 상태에 추가하며, 해당 주문은 처리 담당 CPU 코어로 전송된다. - 주문이 체결되면
OrderFilledEvent가 생성되어 이벤트 저장소로 전송된다. - 시장 데이터 프로세서 및 보고 서비스 같은 다른 구성요소는 이벤트 저장소를 구독하고, 이벤트를 받을 때마다 적절히 처리한다.
이 설계는 앞서 살펴본 개략적 설계안에 대체적으로 부합하지만 이벤트 소싱 아키텍처에서 더 효율적으로 동작할 수 있도록 조정한 부분이 몇 가지 있다.
주문 관리자
이벤트 소싱 아키텍처에서 주문 관리자는 컴포넌트에 내장되는 재사용 가능 라이브러리이다.
- 중앙화된 주문 관리자를 이용하도록 할 경우 지연 시간이 길어질 수 있기 때문
시퀀서
이 다이어그램에는 시퀀서가 없다.
이벤트 저장소에 보관되는 항목에는 sequence 필드가 있고 이 필드의 값은 이벤트 저장소에 있는 시퀀서가 넣는다.
- 각 이벤트 저장소에는 하나의 시퀀서만 있다.(저장소 쓰기 권한을 위한 경쟁 방지)
따라서 시퀀서는 이벤트 저장소에 보내기 전에 이벤트를 순서대로 정렬하는 유일한 쓰기 연산 주체이며, 개략적 설계와 달리 메시지 저장소 역할을 하지않는 한가지 간단한 역할만 수행하므로 아주 빠르다.
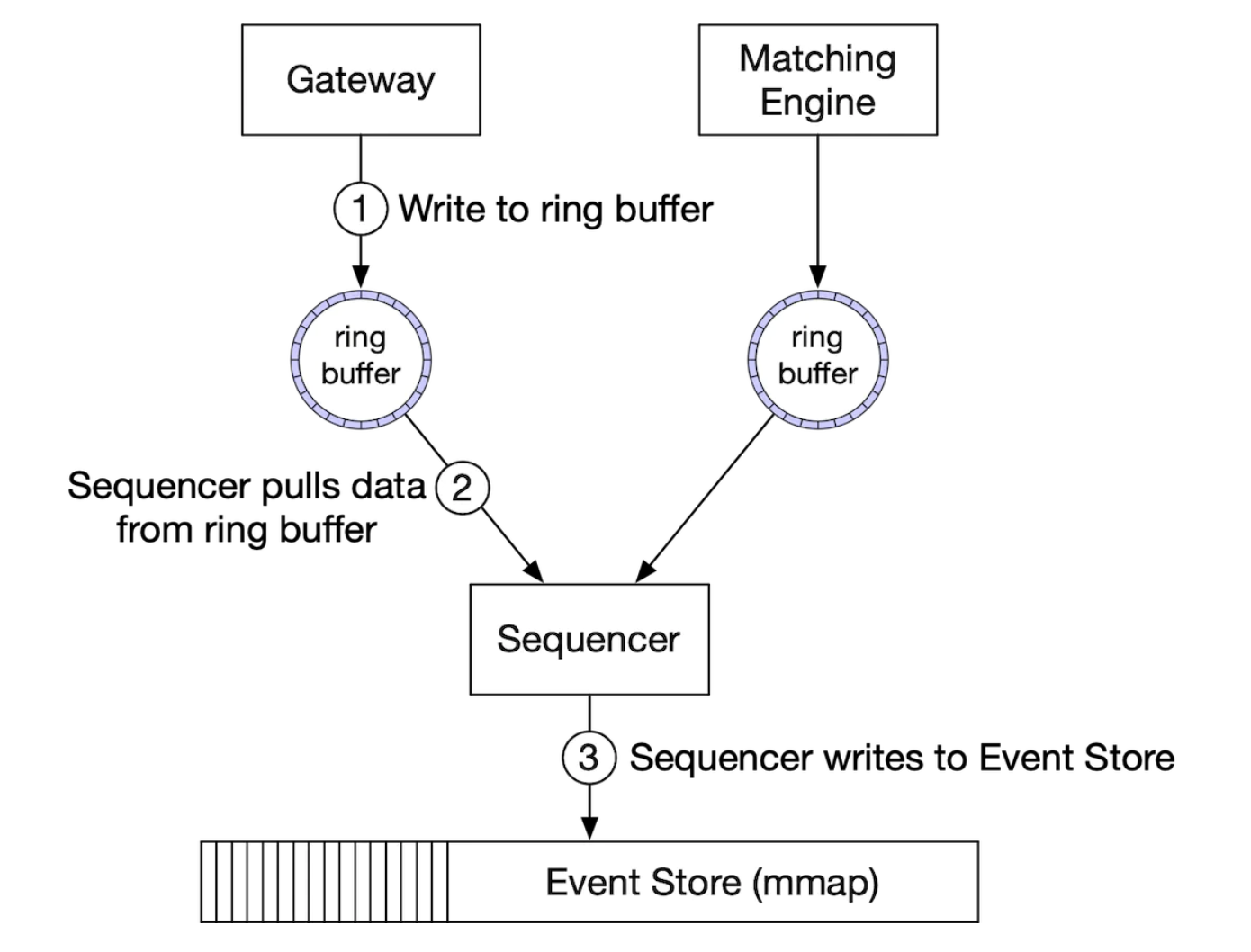
각 컴포넌트에 고유한 링 버퍼에서 이벤트를 가져온 후 순서 ID를 찍고 다음 이벤트 저장소로 보낸다.
- 주 시퀀서가 다운될 경우를 대비해, 백업 시퀀서를 두면 가용성을 높일 수 있다.
고가용성
본 설계안은 99.99% 가용성을 염두에 두고 설계하였으며, 이는 거래소가 다운될 수 있는 시간이 하루에 8.64초를 넘으면 안된다는 뜻이다.
따라서 서비스가 다운되면 즉각 복구되어야 한다.
가용성을 높여야 할 때는 다음과 같은 사항을 살펴야한다.
- 단일 장애 지점을 식별
- ex) 체결 엔진에 발생하는 장애는 거래소에는 재앙이다. 주 인스턴스를 다중화해야 한다.
- 장애 감지 및 백업 인스턴스로의 장애 조치 결정이 빨라야함
클라이언트 게이트웨이와 같은 무상태 서비스의 경우, 서버를 추가하면 쉽게 수평적 확장이 가능하지만, 주문 관리자나 체결 엔진처럼 상태를 저장하는 컴포넌트는, 사본 간에 상태 데이터를 복사할 수 있어야 한다.
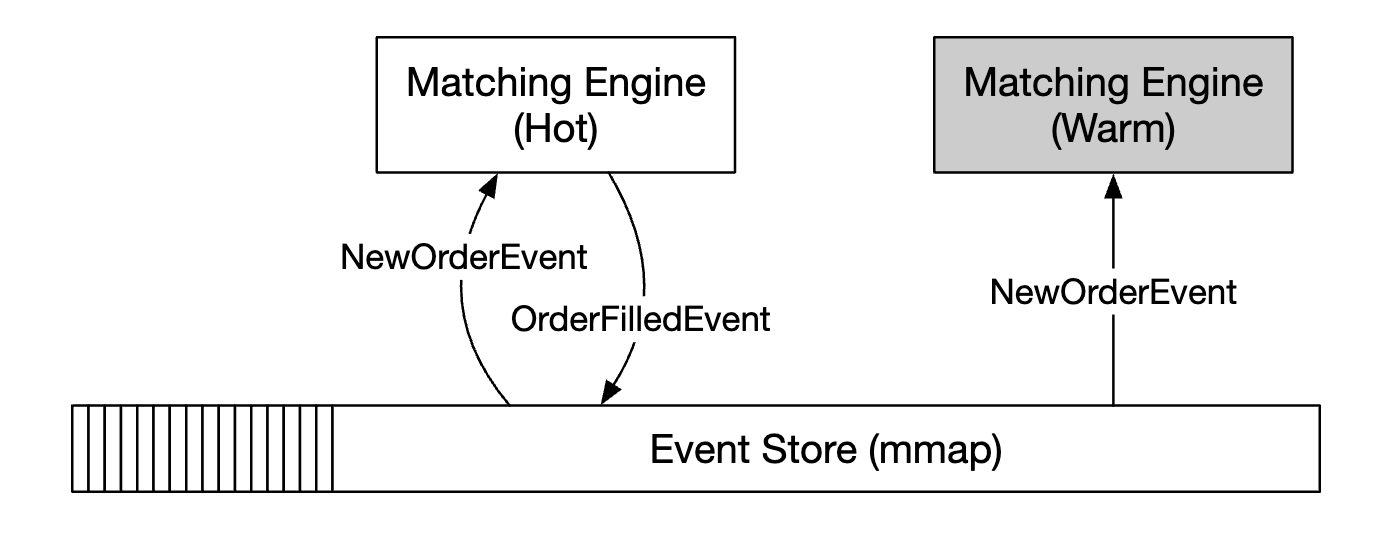
부 체결 엔진은 동일한 이벤트를 수신하고 처리하지만 이벤트 저장소로 이벤트를 전송하지는 않는다.
- 주 인스턴스가 다운되면 부 인스턴스는 즉시 주 인스턴스 지위를 승계한 후 이벤트를 전송
- 부 인스턴스가 다운된 경우 일단 재시작 후 이벤트 저장소 데이터를 사용해 모든 상태 복구
이벤트 소싱 아키텍처는 결정론적 특성으로 인해 상태 복구가 쉽고 정확하여 거래소에 적합하다.
이 아키텍처에서는 주 체결 엔진의 문제를 자동 감지할 메커니즘이 필요하다.
- 하드웨어와 프로세스를 모니터링 하는 일반적인 방안
- 체결 엔진과 박동 메시지를 주고 받는 방안
위 주/부 체결 엔진 설계안의 문제점은 단일 서버 안에서만 동작한다는 것으로, 고가용성을 달성하려면 이 개념을 여러 서버 또는 데이터 센터 전반으로 확장해야 한다.
- 주/부 체결 엔진이 아니라 주/부 서버의 클러스터를 구성해야함
이벤트 저장소를 여러 서버로 복제하는 데는 시간이 많이 걸리므로 안정적 UDP(reliable UDP)를 사용하면 모든 부 서버에 이벤트 메시지를 효과적으로 브로드캐스트 할 수 있다.
결함 내성
주/부 설계안은 비교적 잘 동작하지만 부 서버까지 전부 다운되는 상황이 발생할 수 있으므로 이에 대비해야한다.
핵심 데이터를 여러 지역의 데이터센터에 복제하여 이 문제를 해결하는데, 결함 내성(fault-tolerant) 시스템을 만들려면 많은 확인이 필요하다.
- 주 서버가 다운되면 언제, 그리고 어떻게 부 서버로 자동 전환하는 결정을 내리는가?
- 부 서버 가운데 새로운 리더는 어떻게 선출하는가?
- 복구 시간 목표(Recovery Time Objective, RTO)는 얼마인가?
- 어떤 기능을 복구해야 하는가(Recovery Point Objective, RPO)?
- 시스템이 성능 저하 상태로도 동작할 수 있는가?
먼저 장애가 생겼다는 것이 실제 무엇을 의미하는지 이해해야한다.
- 시스템에서 잘못된 경보를 전송하면 불필요한 장애 극복 절차, 즉 부 시스템으로의 자동 전환 발생 가능
- 코드의 버그로 인해 주 서버가 다운되었다면 부 서버로 자동 전환되더라도 같은 버그 때문에 부 서버까지 다운될 수 있음
- 모든 주/부 서버가 중단되면 시스템은 더 이상 사용할 수 없는 상태에 빠짐
이는 어려운 문제로 몇 가지 해결책을 생각해 볼 수 있다.
- 새 시스템을 처음 출시할 때는 수동으로 장애 복구 조치를 수행
- 충분한 시그널, 운영 경험을 축적하여 시스템의 이해도를 높이고 자동으로 장애를 감지하여 복구하는 프로세스를 도입
- 카오스 엔지니어링(chaos engineering)은 드물게 발생하는 까다로운 사례를 수면으로 이끌어내고 운영 경험을 빠르게 축적하는 데 좋은 방법
래프트
장애 복구 조치를 자동으로 올바르게 할 수 있다면 어떤 서버가 주 서버 역할을 인계 받을지 결정하는 검증된 리더 선출 알고리즘들을 고려할 수 있다.
대표적으로 래프트가 있다.
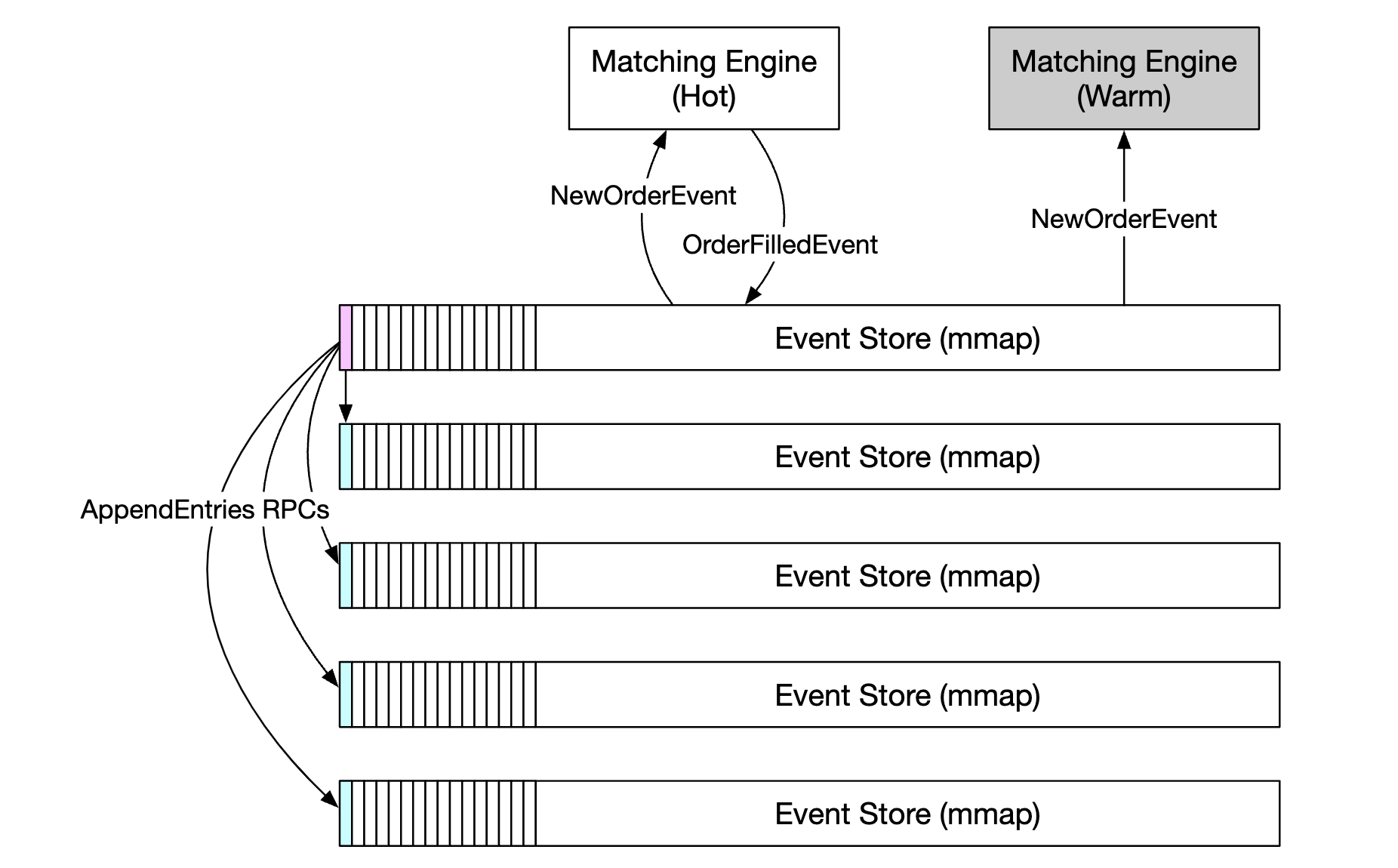
수신된 이벤트는 팔로어의 자체 mmap 이벤트 저장소에 저장된다.
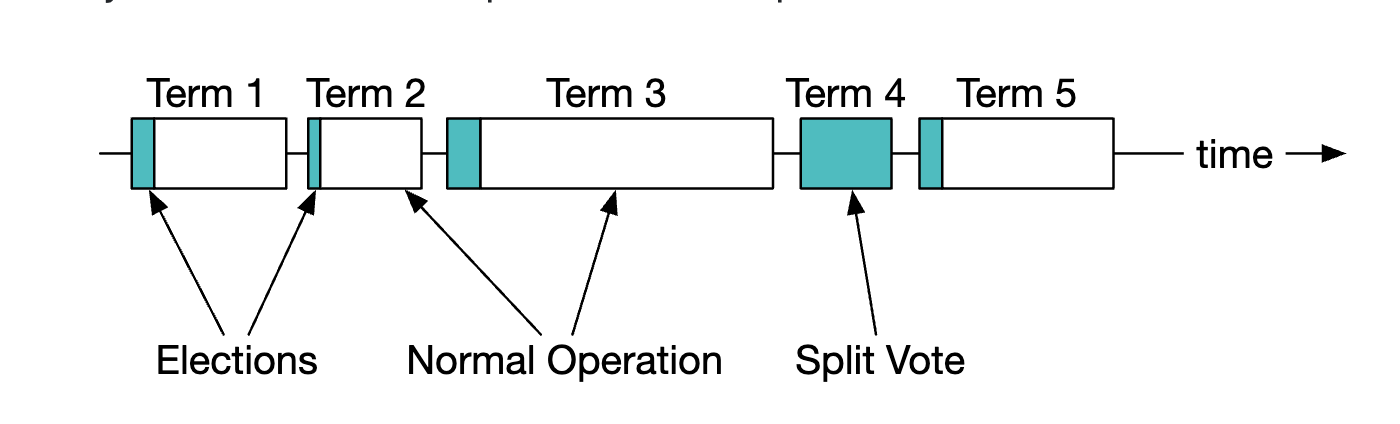
- 리더는 팔로어에게 박동 메시지를 보내고, 일정 기간 동안 박동 메시지를 받지 못한 팔로어는 새 리더를 선출하는 선거 타이머를 시작한다.(
AppendEnties) - 가장 먼저 타이머가 타임아웃된 팔로어는 후보가 되고, 다른 나머지 팔로어에게 투표를 요청한다.(
RequestVote) - 그 팔로어가 과반 수 이상의 표를 받으면 새로운 리더가 된다.
첫번 째 팔로어의 임기(term) 값이 새 노드보다 짧으면 리더가 될 수 없으며, 여러 명의 팔로어가 동시에 후보가 되는 경우 분할 투표(split vote)라고 한다.
이 경우 기존 선거의 타임아웃을 선언하고 새로운 선거를 시작한다.
복구 시간 목표
복구 시간 목표는 애플리케이션이 다운되어도 사업에 심각한 피해가 없는 시간의 최대값이다.
증권 거래소의 경우 2등급을 RTO를 달성해야하는데, 이를 위해 서비스의 자동 복구가 반드시 가능해야 한다.
- 우선순위에 따라 서비스를 분류하고 최소 서비스 수준을 유지하기 위한 성능 저하 전략(degradation strategy)을 정의한다.
복구 지점 목표
RPO는 비즈니스에 심각한 피해가 발생하기 전 손실될 수 있는 데이터의 양, 즉 손실 허용 범위를 의미한다.
- 실무에서는 데이터는 자주 백업해야 한다는 것과 같은 뜻으로 받아들인다.
증권 거래소는 데이터 손실을 용납할 수 없으므로 RPO가 0에 가깝다.
레프트 메커니즘을 사용하면 데이터 사본은 많고, 모든 클러스터 노드가 같은 상태를 갖도록 보장할 수 있다.
체결 알고리즘
| |
이 의사 코드는 FIFO 체결 알고리즘을 사용한다.
특정 가격 수준에서 먼저 들어온 주문이 먼저 체결되고, 마지막 주문이 가장 나중에 체결된다.
체결 알고리즘은 다양하다.
- FIFO + LLM(Lead Market Maker): LLM에 먼저 일정 수량을 할당
- 다크 풀(dark pool)
결정론
결정론(determinism)에는 기능적 결정론(functional determinism)과 지연 시간 결정론(latency determinism)이 있다.
기능적 결정론
이벤트를 동일한 순서로 재생하면 항상 같은 결과를 얻을 수 있도록 보장하는 것으로 이벤트가 발생하는 실제 시간은 대체로 중요하지 않고, 발생한 순서 자체가 중요하다.
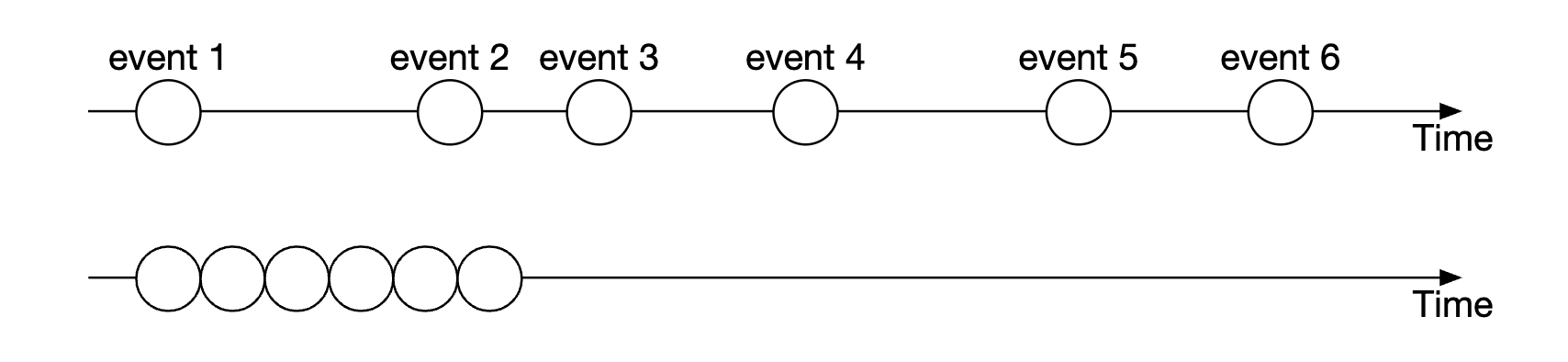
시간 축 위에 불규칙하게 나열된 타임스탬프들이 연속된 점들로 변환되었는데, 그렇게 되면 재생과 복구에 소요되는 시간이 크게 줄어든다.
지연 시간 결정론
특정 작업을 완료하거나 입력에 반응하는 데 걸리는 시간이 얼마나 일관되고 예측 가능한지를 의미한다.
결정론적 시스템은 지연 시간의 변동성을 최소화하여 예측 가능하고 일관된 응답 시간을 보장한다.(응답 시간도 결정되어야한다.)
각 거래의 처리 시간이 거의 같다는 뜻으로 사업에서 가장 중요한 부분이다.
- 99번 백분위수 지연 시간이나 99.99번 백분위수 지연 시간을 측정하여 확인한다.
p99 지연 시간이 낮다는 것은 거래소가 거의 모든 거래에 안정적인 성능을 제공한다는 뜻 이다.
지연 시간 변동 폭이 커지면 원인 조사가 필요하다.
시장 데이터 게시 서비스 최적화
L3 호가 창/주문서 데이터를 보면 시장을 더 잘 파악할 수 있다.
하루치 봉 차트 데이터는 무료로 얻을 수 있지만 자세한 L2/L3 호가 창 데이터를 얻으려면 비용이 많이 들기 때문에, 많은 헤지 펀드가 거래소 실시간 API를 통해 데이터를 직접 기록하여 기술적 분석을 위한 많은 차트를 자체적으로 구축한다.
시장 데이터 게시 서비스(Market Data Publisher, MDP)는 체결 엔진의 체결 결과를 받아 이를 기반으로 호가 창과 봉 차트를 재구축 한 다음 구독자에게 그 데이터를 게시한다.
MDP는 다양한 수준의 서비스를 제공하는데, MDP의 메모리는 무한대로 확장할 수 없으므로 봉 차트에는 상한선을 두어야한다.
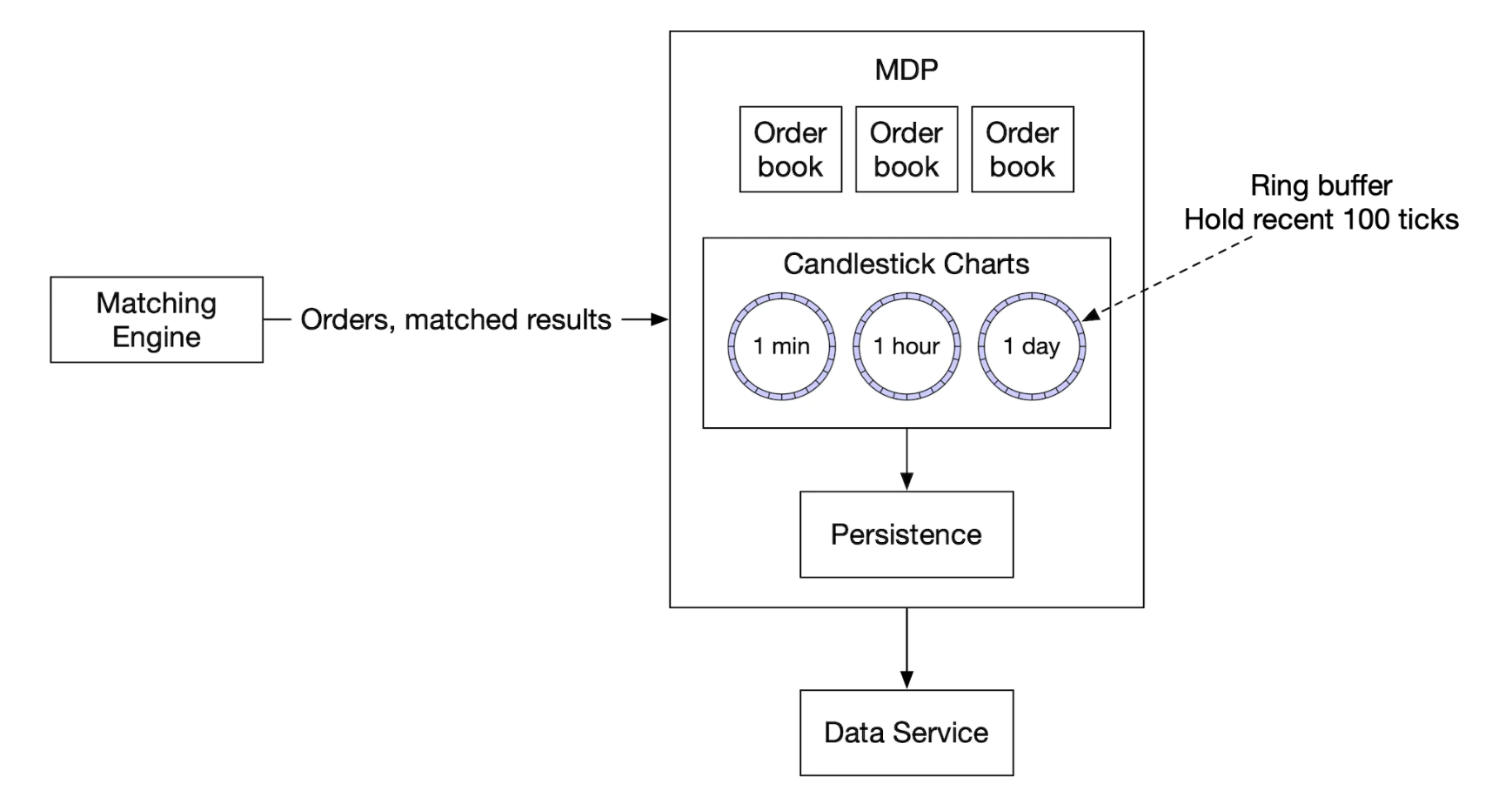
이 설계안은 링 버퍼를 활용한다. 원형 버퍼라고도 하는 링 버퍼는 앞과 끝이 연결된 고정 크기의 큐로, 생산자는 계속 데이터를 넣고 하나 이상의 소비자는 데이터를 꺼낸다.
링 버퍼의 공간은 사전에 할당된 것으로 객체를 생성하거나 삭제하는 연산이 필요없고, 락을 사용하지 않는다.
- 패딩(padding)은 링 버퍼의 순서 번호가 다른 것과 같은 캐시 라인에 오지 않도록 한다.
시장 데이터의 공정한 배포
거래소에서 다른 사람보다 지연 시간이 낮다는 것은 미래를 예측할 수 있다는 것과 같은 의미로, 규제를 받는 거래소의 경우 모든 수신자가 동시에 시장 데이터를 받을 수 있도록 보장하는 것이 중요하다.
- 안정적 UDP를 사용하는 멀티 케스트는 한 번에 많은 참가자에게 업데이트를 브로트캐스트 하기 좋은 솔루션이다.
- 연결하는 순서로 데이터를 주는 대신, 무작위 순서로 주는 방법도 고려할 수 있다.
거래소 설계에는 보편적으로 멀티캐스트를 사용하며, 같은 멀티캐스트 그룹에 속한 수신자는 이론적으로는 동시에 데이터를 수신한다.
- 그러나 UDP는 신뢰성이 낮은 프로토콜이며 그 데이터그램이 모든 수신자에게 도달하지 못핦 수 있으므로 유의한다.
코로케이션
많은 거래소가 헤지 펀드 또는 브로커의 서버를 거래소와 같은 데이터 센터에 둘 수 있도록 하는 코로케이션 서비스를 제공한다.
- 체결 엔진에 주문을 넣는 지연 시간은 기본적으로 전송 경로 길이에 비례한다.
- 유료 VIP 서비스로 취급한다.
네트워크 보안
거래소는 일반적으로 몇 가지 인터페이스를 공개하고 있기 때문에 DDoS 공격에 대응할 수 있는 능력을 갖추는 것이 중요하다.
- 공개 서비스와 데이터를 비공개 서비스에서 분리하여 DDoS 공격이 가장 중요한 클라이언트에 영향을 미치지 않도록 한다.
- 동일한 데이터를 제공해야 하는 경우 읽기 전용 사본을 여러 개 만들어 문제를 격리
- 자주 업데이트되지 않는 데이터는 캐싱
- URL을 강화
- 효과적인 허용/차단 리스트 메커니즘을 사용
- 처리율 제한
4단계: 마무리
대형 거래소를 위한 이상적인 배포 모델은 모든 것을 하나의 거대한 서버 도는 단일 프로세스에 배치하는 것이라는 결론에 도달할 것이다.
- 일부 거래소는 이런 방식을 따른다.
암호화폐 산업이 발전함에 따라 많은 암호화폐 거래소가 클라우드 인프라를 사용하여 서비스를 배포한다.
클라우드 생태계가 제공하는 편리함은 설계의 방향을 바구었을 뿐 아니라 업계 진입 문턱도 낮추고 있다.