
이번 장에서는 온라인 게임 리더보드, 즉 순위표를 설계해본다.
순위표?
누가 선두를 달리고 있는지 보여주기 위해 게임 등에서 흔히 사용하는 장치로, 가장 많은 포인트를 획득한 사람이 순위표의 맨 위에 자리한다.
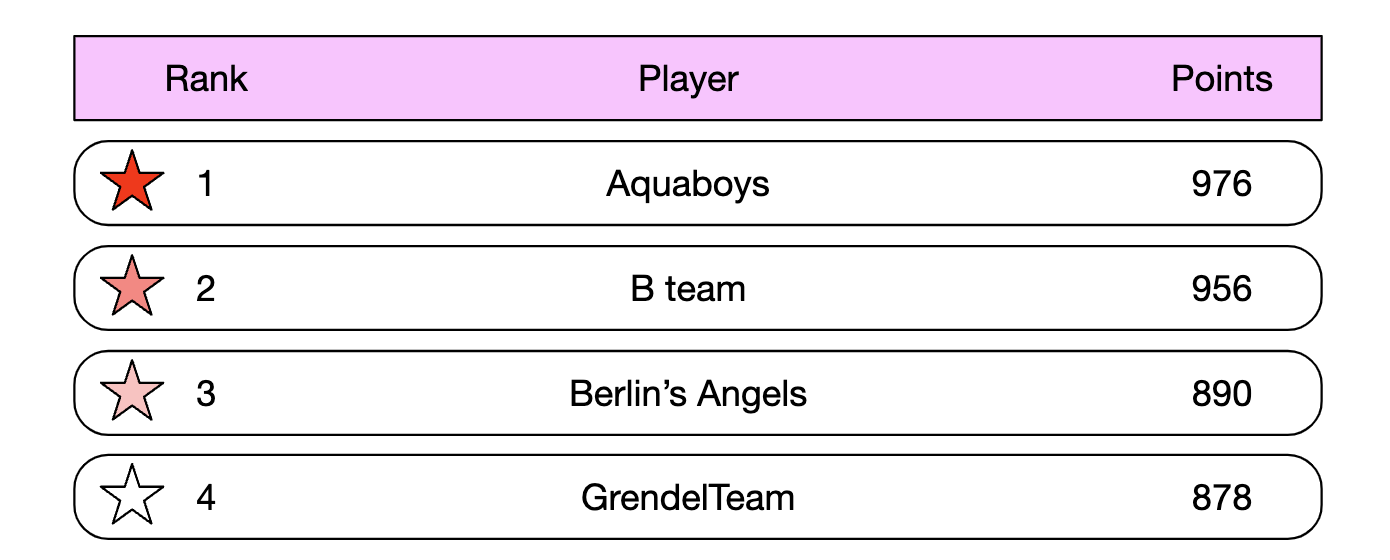
1단계: 문제 이해 및 설계 범위 확정
- 게임에 승리하면 포인트 획득
- 모든 플레이어가 순위표에 포함
- 새로운 토너먼트를 시작할 때 마다 새로운 순위표 생성
- 상위 10명의 사용자와 특정 사용자의 순위를 순위표에 표시
- 특정 사용자의 순위를 보여줄 때 위, 아래로 4순위 차이 사용자 포함(추가 요구사항)
- DAU 500만명, MAU 2,500만명
- 각 선수는 하루에 평균 10 경기 진행
- 실시간 또는 실시간에 가깝게 결과를 표시
- 누적된 결과 이력을 보여주는건 바람직하지 않음
기능 요구사항
- 순위표에 상위 10명의 플레이어를 표시
- 특정 사용자의 순위를 표시
- 어떤 사용자보다 4순위 위, 아래에 있는 사용자를 표시(추가 요구 사항)
비기능 요구사항
- 점수 업데이트는 실시간으로 순위표에 반영
- 일반적인 확장성, 가용성 및 안정성 요구사항
개략적인 규모 추정
설계를 통해 해결해야 할 문제의 잠재적 규모와 과제를 결정하기 위한 몇가지 계산 결과를 살펴본다.
게임은 대부분 사용량이 균등한 경우가 없으며, 북미 기준 저녁 시간이 피크 시간대일 가능성이 높다.
이를 고려하여 최대 부하는 평균의 다섯배 정도로 가정한다.
사용자 수
500만 / 10^5 초 =~ 50 * 5 = 초당 250 사용자
점수 획득 QPS
- 한 사용자가 하루 평균 10개의 게임을 플레이한다고 가정
- 점수를 획득하는 이벤트가 발생하는 평균 QPS는
50 * 10 =~ 500 - 최대 QPS는 평균의 5배로 가정하였으므로
500 * 5 = 2,500
상위 10명 순위표 가져오기
- 각 사용자가 하루 한 번 게임을 실행
- 상위 10명 순위표는 사용자가 처음 게임을 열 때만 표시한다고 가정
QPS =~ 50
2단계: 개략적 설계안 제시 및 동의 구하기
API 설계
개략적으로 3가지 API가 필요하다.
POST /v1/scores
사용자가 게임에서 승리하면 순위표에서 사용자의 순위를 갱신한다.
API는 게임 서버에서만 호출할 수 있는 내부 API로 클라이언트는 해당 API를 통하지 않고 순위표 점수를 직접 업데이트 할 수 없다.
- 요청
| 필드 | 설명 |
|---|---|
user_id | 게임에서 승리한 사용자 |
points | 사용자가 게임에서 승리하여 획득한 포인트 수 |
- 응답
| 이름 | 설명 |
|---|---|
200 OK | 사용자 점수를 성공적으로 갱신 |
400 Bad Request | 잘못된 인자가 전달되어 사용자 점수를 갱신할 수 없음 |
GET /v1/scores
순위표에서 상위 10명의 플레이어를 조회
| |
`GET /v1/scores/{:user_id}
특정 사용자의 순위를 가져옴
| 필드 | 설명 |
|---|---|
user_id | 순위 정보를 가져올 사용자 ID |
| |
개략적 설계안
두 가지 서비스가 포함된다.
- 게임 서비스
- 사용자가 게임을 플레이할 수 있도록 함
- 순위표 서비스
- 순위표를 생성하고 표시하는 역할 담당
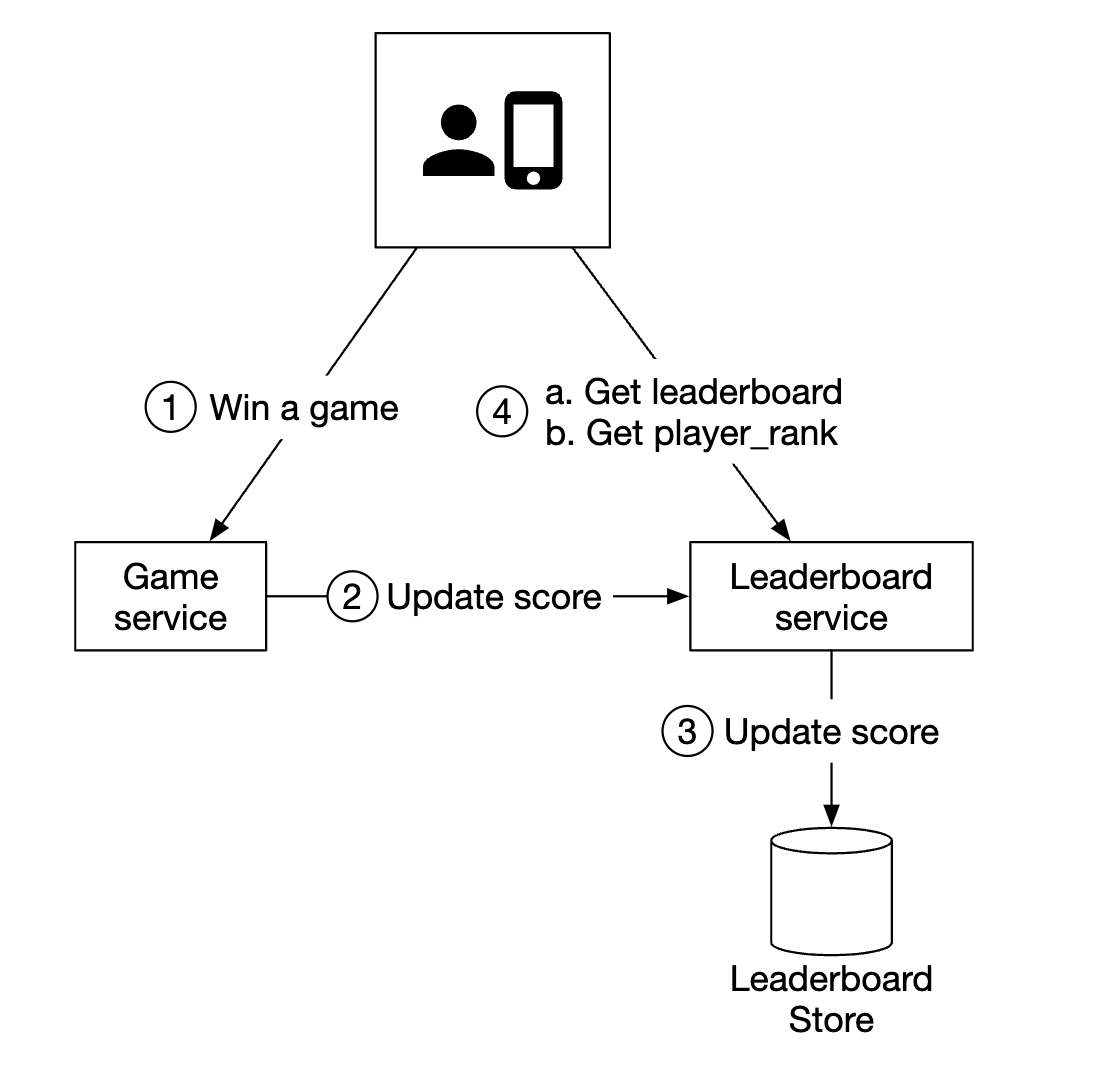
- 사용자가 게임에서 승리하면 클라이언트는 게임 서비스에 요청을 보낸다.
- 게임 서비스는 해당 승리가 정당하고 유효한 것인지 확인한 다음 순위표 서비스에 점수 갱신 요청을 보낸다.
- 순위표 서비스는 순위표 저장소에 기록된 해당 사용자의 점수를 갱신한다.
- 해당 사용자의 클라이언트는 순위표 서비스에 직접 요청하여 다음과 같은 데이터를 가져온다.
- 상위 10명 순위표
- 해당 사용자 순위
다른 대안들도 있지만 채택하지 않은 이유를 살펴보면 도움이 될 것이다.
클라이언트가 순위표 서비스와 직접 통신해야 하나?
클라이언트가 점수를 정하는 방식(클라이언트가 직접 순위표 서비스에 요청하는 방식)은, 사용자가 프락시를 설치하고 점수를 마음대로 바꾸는 중간자 공격을 할 수 있기 때문에 보안상 안전하지 않다.
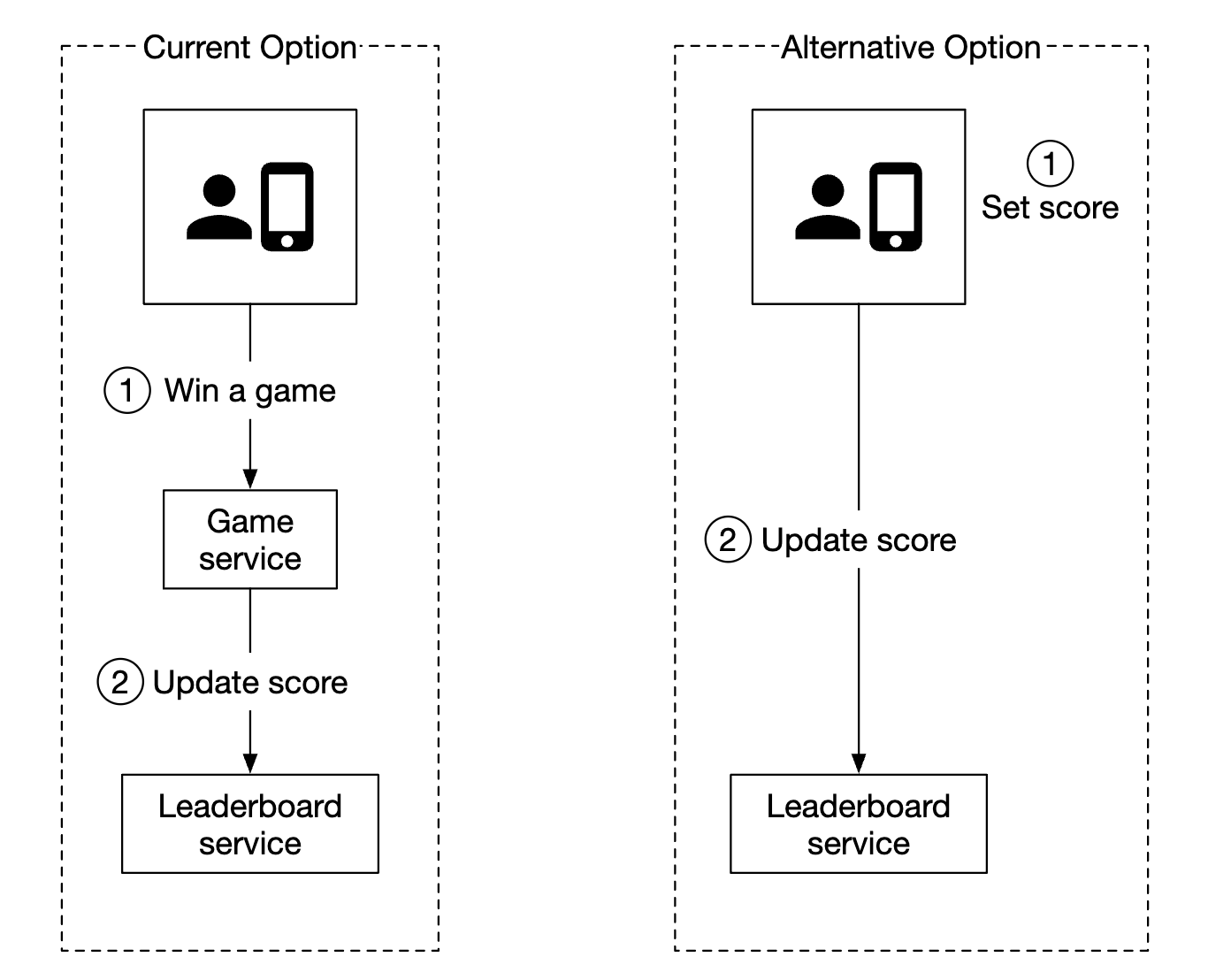
서버가 게임 전반을 통솔하는 경우 클라이언트가 점수를 설정하기 위해서 게임 서버를 명시적으로 호출할 필요가 없을수도 있다.
- 게임 서버가 모든 게임 로직을 처리하고 게임이 언제 끝나는지 알기 때문에 클라이언트의 개입 없이도 점수를 정할 수 있다.
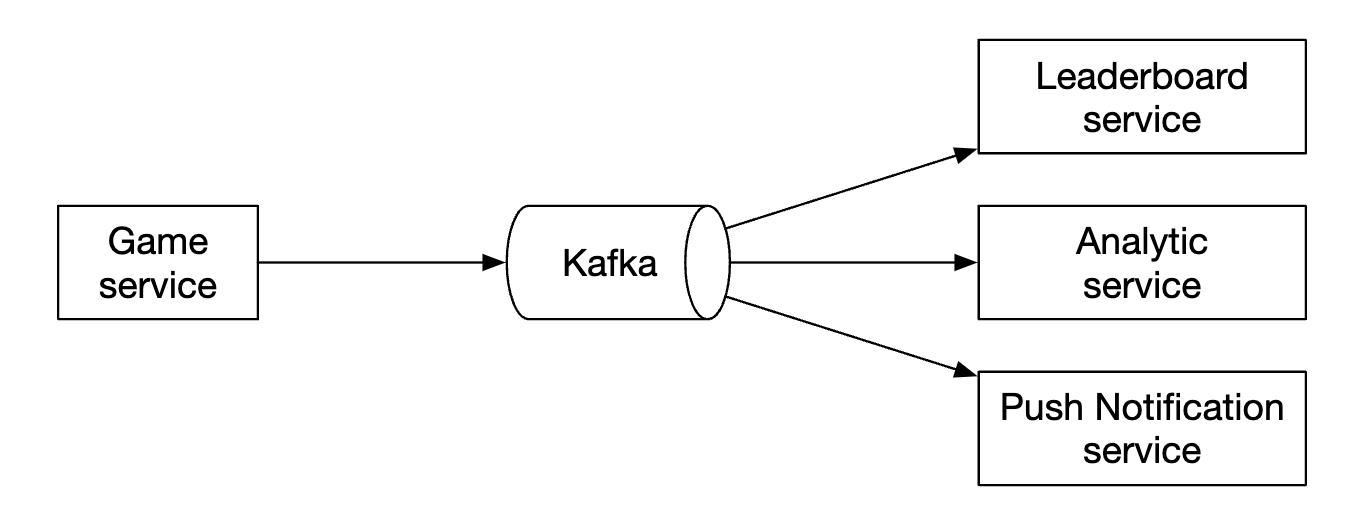
게임 서비스와 순위표 서버 사이에 메시지 큐가 필요한가?
게임 점수가 어떻게 사용되는지에 따라 크게 달라질 수 있다.
해당 데이터가 다른 곳에서도 이용되거나 여러 기능을 지원해야 한다면 카프카에 데이터를 넣는 것이 합리적일 수 있다.
데이터 모델
순위표 저장소는 시스템의 핵심 구성 요소 중 하나다.
저장소 구현에 사용할 수 있는 세 가지 기술을 살펴본다.
관계형 데이터베이스
규모 확정성이 중요하지 않고, 사용자 수가 적다면 관계형 데이터베이스 시스템을 활용할 수 있다.
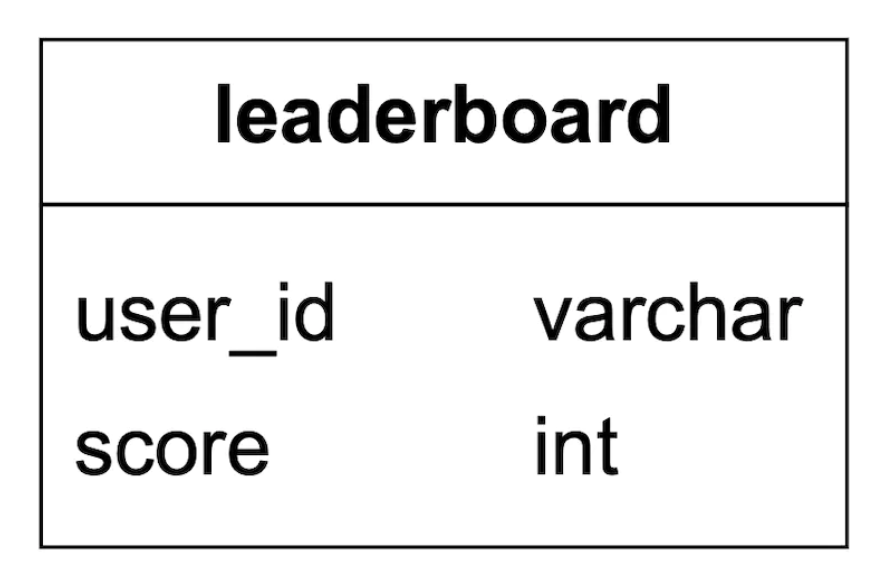
각 월별 순위표는 사용자 ID와 점수 열을 갖는 데이블로 표현할 수 있다.
사용자가 점수를 딴 경우

점수가 1점씩만 늘어난다고 가정하면 해당 월의 순위표에 아직 햊당 사용자가 없다면 새로운 레코드를 만들어 넣고,
| |
있다면 증가시킨다.
| |
특정 사용자 순위 검색

사용자의 순위를 가져오려면 순위표 테이블을 점수 기준으로 정렬한 후 순위를 매긴다.
| |
이 방안은 데이터가 많지 않을 때는 효과적이지만, 레코드가 수백만 개 정도로 많아지면 성능이 너무 나빠지는 문제가 있다.
- 사용자의 순위를 파악하려면 모든 플레이어를 순외표의 정확산 위치에 정렬해야한다.
- 같은 점수를 받은 사용자가 여럿일 수 있으므로, 순위는 단순히 해당 목록 내의 사용자 위치라고도 할 수 없다.
SQL 데이터베이스는 지속적으로 변화하는 대량의 정보를 신속하게 처리하지 못한다.
- 수백만 개 레코드에 순위를 매기려면 대략 수십 초 정도가 걸린다.
따라서 실시간성을 요구하는 애플레키에션에는 적합하지 않고, 데이터가 지속적으로 변경되므로 캐시 도입도 어렵다.
- 일괄 작업(배치)로 처리하면 가능할 수 있지만 실시간 순위를 보여주어야 한다는 요구사항에는 적절치 않다.
인덱스를 추가하고 LIMIT 절을 사용하여 스캔할 페이지 수를 제한할 수 있지만, 확장성이 좋지 않다.
| |
- 특정 사용자의 순위를 알아내려면 기본적으로 전체 테이블을 훑어야 한다.
- 순위표 상단에 있지 않은 사용자의 순위를 간단히 찾을 수 없다.
레디스
레디스는 메모리 기반 키-값 저장소 시스템으로 메모리에서 동작하여 빠른 읽기 및 쓰기가 가능하다.
이를 통해 수백만 명의 사용자에 대해서도 예측 가능한 ㅅ어능ㅇ르 제공하고 복잡한 DB 쿼리 없이도 일반적인 순위표 작업을 쉽게 수행할 수 있다.
아울러 순위표 시스템 설계 문제를 해결하는 데 이상적인 정렬 집합(sorted set)이라는 자료형을 제공한다.
정렬 집합이란?
집합과 유사항 자료형으로 저장된 각 원소는 점수에 연결되어 있다.
집합 내 원소는 고유해야 하지만 같은 점수는 있을 수도 있고, 정렬 집합 내 원소를 오름차순 정렬하는 데 이용된다.
정렬 집합은 내부적으로 해시 테이블과 스킵 리스트라는 두 가지 자료 구조를 사용한다.
- 해시 테이블: 사용자의 점수를 저장
- 스킵 리스트: 특정 점수를 딴 사용자들의 목록을 저장
사용자는 점수를 기준으로 정렬한다.
- 점수 및 사용자 열이 있는 테이블로 생각하면 이해하기 쉽다.
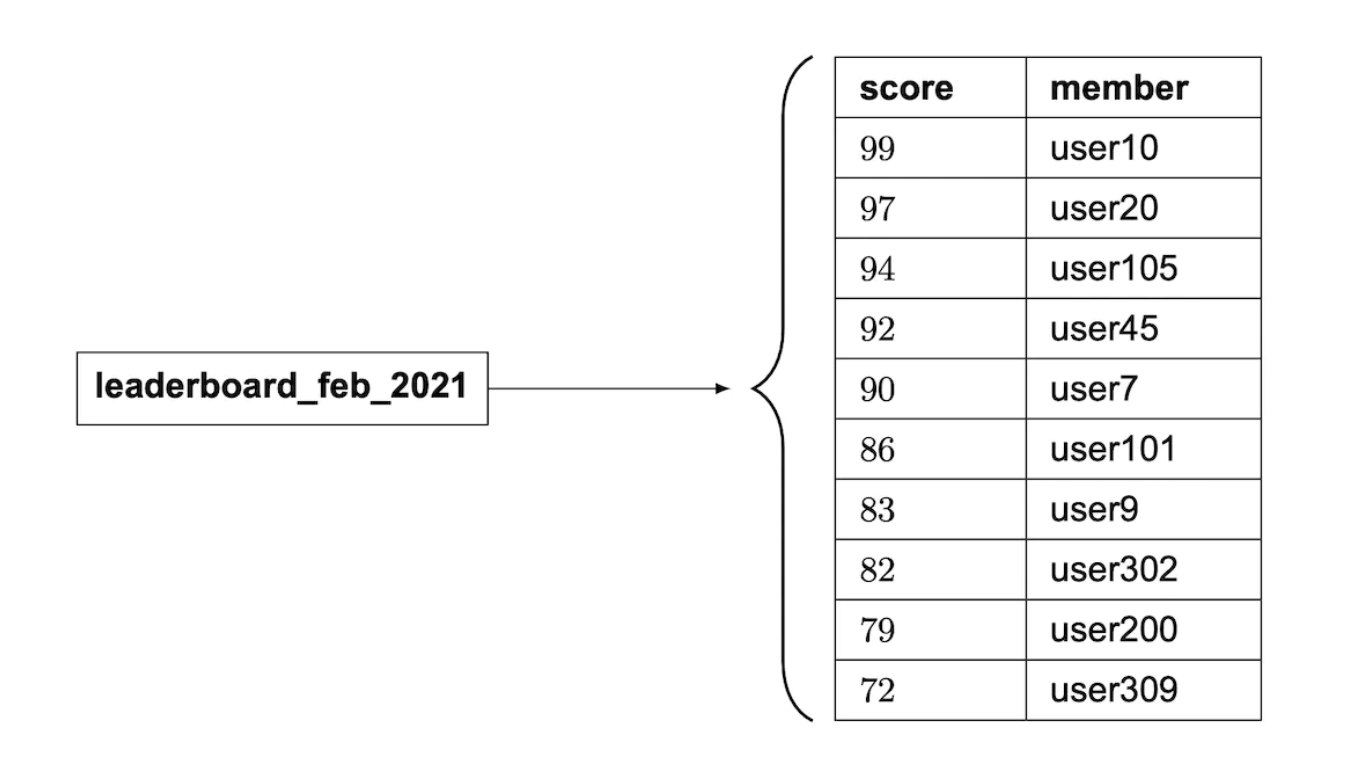
스킵 리스트
빠른 검색을 가능하게 하는 자료구조로, 정렬된 연결 리스트에 다단계 색인을 두는 구조이다.
이 자료 구조의 근간은 정렬된 단방향 연결 리스트로, 이 연결 리스트에 삽입, 삭제, 검색 연산을 실행하는 시간 복잡도는 O(n)이다.
연산이 더 빨리 실행할 수 있도록 하기 위해 이진 검색 알고리즘을 통해 중간 지점에 더 빨리 도달할 수 있도록 한다.
- 중간 노드를 하나씩 건너뛰는 1차 색인과 1차 색인 노드를 하나씩 건너 뛰는 2차 색인을 추가한다.
새로운 색인을 추가할 때마다 이전 차수의 노드를 하나씩 건너뛸 수 있다.
- 노드 사이의 거리가
n-1이 되면 더 이상의 색인을 추가하지 않는다. - n은 총 노드의 개수
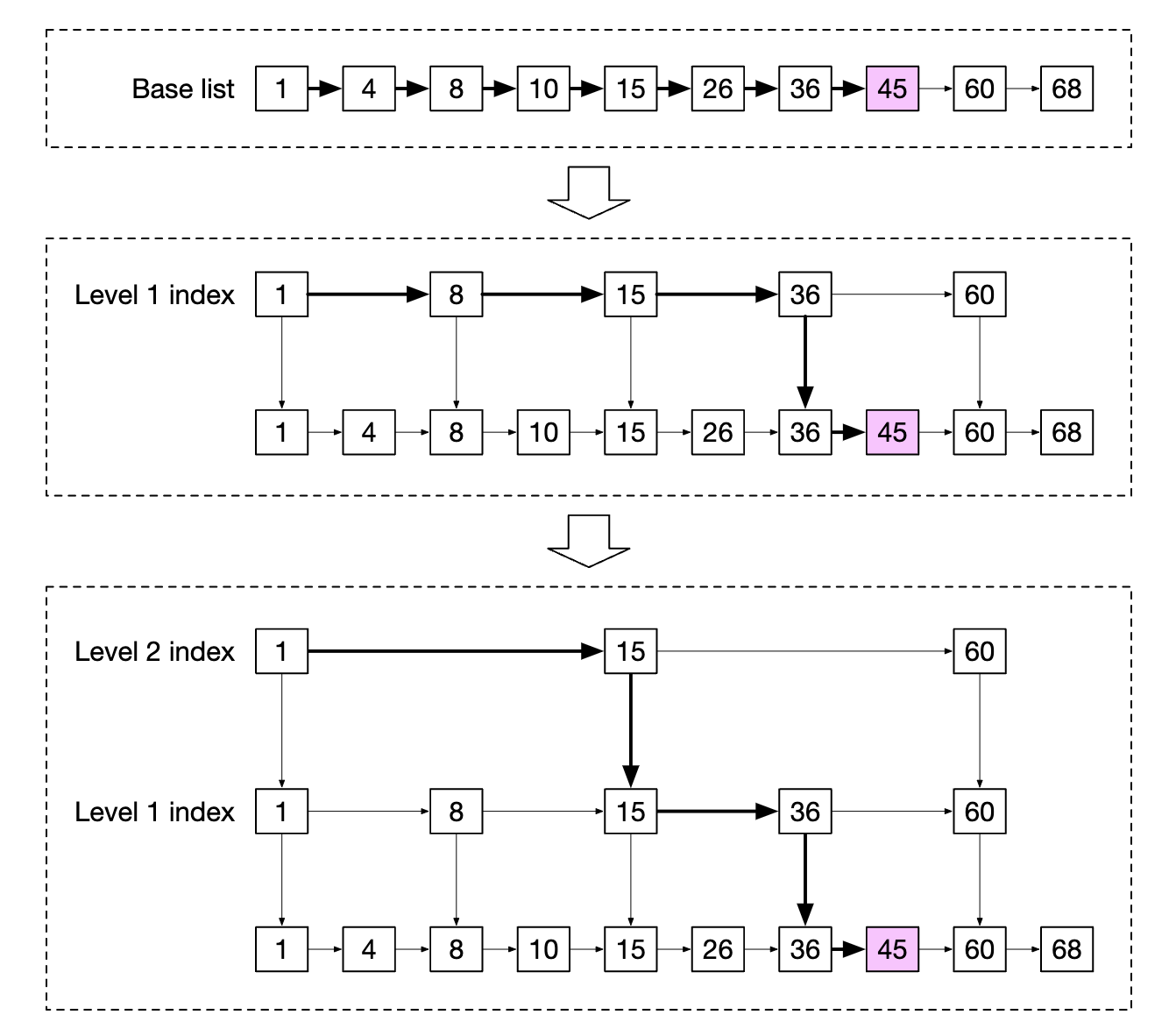
다단계 색인을 사용하면 특정 값을 훨씬 빠르게 찾을 수 있다.

데이터 양이 적을 때는 스킵 리스트의 속도 개선 효과가 분명하지 않지만, 5차 색인까지 사용하는 스킵 리스트를 예시로 들면 개선을 확인할 수 있다.
기본 리스트만 있는 경우 찾는 노드에 도달하기 위해 62개의 노드를 거쳐야하지만, 스킵 리스트의 경우에는 11개의 노드만 통과하면 된다.
정렬 집합은 삽입이나 갱신 연산을 할 때 모든 원소가 올바른 위치에 자동으로 배치되며 새 원소를 추가하거나 기존 원소를 검색하는 연산의 시간 복잡도가 O(log(n))이므로 관계형 데이터베이스보다 성능이 좋다.
관계형 데이터베이스에서 특정 사용자의 순위를 계산하려면 중첩 질의문을 수행해야한다.
| |
레디스 정렬 집합을 사용한 구현
순위표 구현에 사용할 레디스 연산들을 살펴본다.
ZADD- 기존에 없던 사용자를 집합에 추가한다.
- 기존 사용자의 경우에는 점수를 업데이트한다.
O(log(n))
ZINCRBY- 사용자 점수를 지정된 값 만큼 증가시킨다.
- 집합에 없는 사용자는 0점으로 가정한다.
O(log(n))
ZRANGE/ZREVRANGE- 점수에 따라 정렬된 사용자 중 특정 범위에 드는 사용자들을 가져온다.
- 순서, 항목 수, 시작 위치를 지정할 수 있다.
O(log(n) + m)m: 가져올 항목 수n: 정렬 집합의 크기
ZRANK/ZREVRANK- 오름차순/내림차순 정렬하였을 때 특정 사용자의 위치를 가져온다.
O(log(n))
ZREVRANGE는 향후 사용이 중단될 명령으로,ZRANGE명령에 추가 속성을 전달하면 같은 결과를 얻을 수 있다.
사용자가 점수를 획득한 경우
매 월 새로운 순위표를 위한 정렬 집합을 만들고 이전 순위표는 이력 데이터 저장소로 보낸다.
사용자는 승리하면 점수를 얻은데, ZINCRBY를 호출하여 사용자 점수를 증가시키거나 순위표 세트에 없는 경우 사용자를 순위표 집합에 추가한다.
| |
사용자가 순위표 상위 10명을 조회하는 경우
가장 높은 점수를 받은 사용자로부터 내림차순으로 정렬한 결과를 가져와야 하므로 ZREVRANGE를 호출한다.
사용자 목록뿐 아니라 각 사용자의 현재 점수도 가져와야 하므로 WITHSCORES 속성도 전달한다.
| |
다음과 같은 목록이 반환된다.
| |
사용자가 자기 순위를 조회하는 경우
ZREVRANK를 호출하면 특정 사용자의 순위를 가져올 수 있다.
| |
특정 사용자 순위를 기준으로 일정 범위 내 사용자를 질의하는 경우
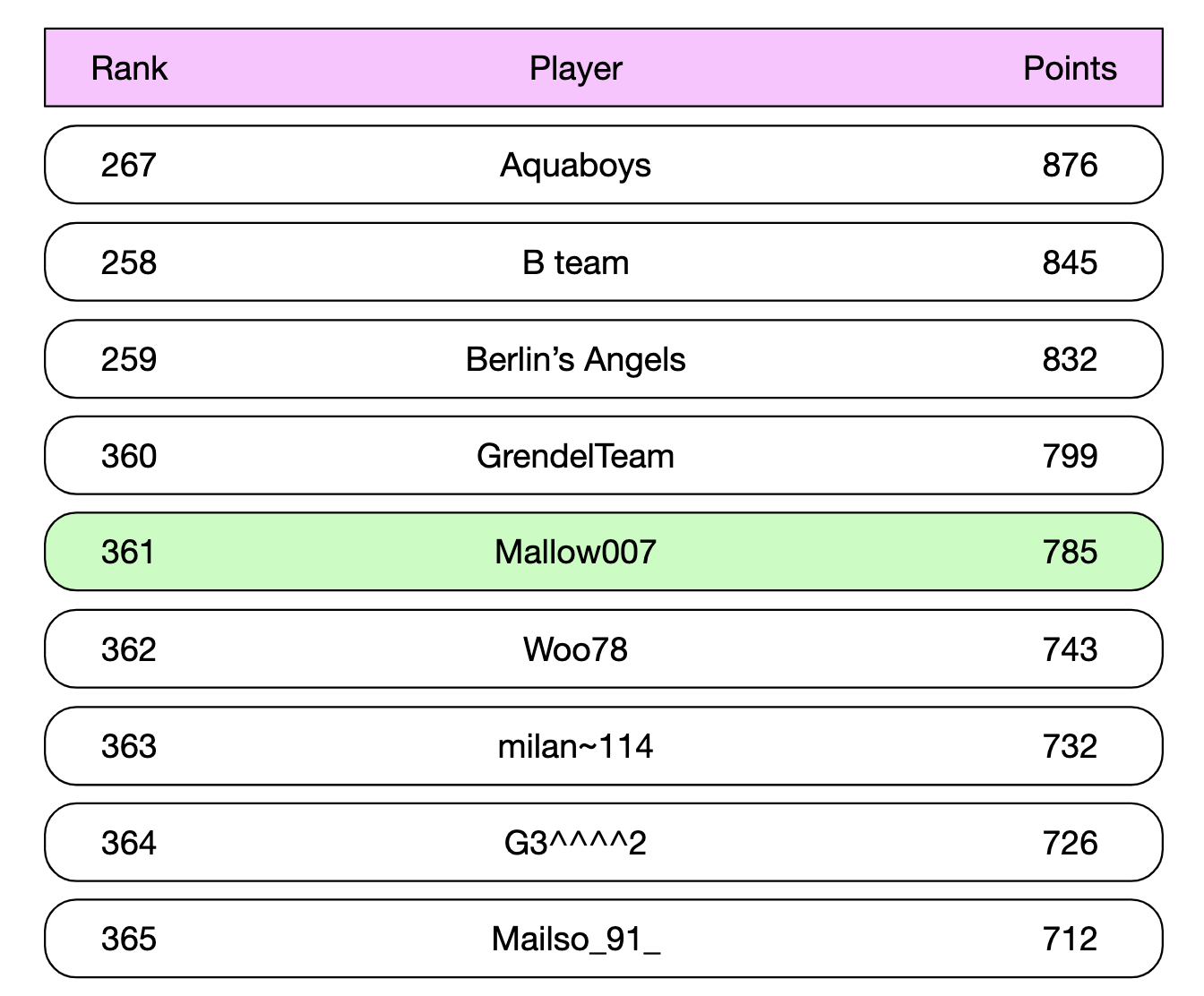
ZREVRANGE를 활용하면 특정한 사용자 전/후 순위 사용자 목록을 얻어낼 수 있다.
Mallow007의 사용자가 361등이고, 전 후로 4명씩 조회한다면
| |
저장소 요구사항
최소한 사용자 ID와 점수는 저장해야 한다.
최악의 시나리오는 월간 활성 사용자 2,500만 명 모두가 최소 한 번 이상 게임에서 승리하는 바람에 모두 월 순위표에 올라야 하는 경우이다.
- ID: 24자 문자열
- 점수: 16비트 정수
- 순위표 한 항목당 26바이트 필요
- MAU 순위표 항목이 하나라는 최악의 시나리오를 가정하면
26바이트 * 2,500만 = 650MB
이 정도라면 스킵 리스트 구현에 필요한 오베헤드와 정렬 집합 해시를 고려해 메모리 사용량을 두 배로 늘린다고 해도 최신 레디스 서버 한 대만으로도 데이터를 충분히 저장할 수 있다.
CPU 및 I/O 사용량
개략적인 추정치에 따르면 갱신 연산의 최대 QPS는 2500/초 정도로 레디스 서버로도 충분히 감당할 수 있는 부하이다.
하지만 레디스 노드에 장애 발생으로 인한 영속성을 고려해야한다.
레디스는 데이터를 디스크에 영속적으로 보관하는 옵션도 지원하나, 디스크에서 데이터를 읽어 대규모 레디스 인스턴스를 재시작하려면 시간이 많이 걸린다.
- 그래서 보통은 레디스에 읽기 사본을 두는 방식으로 구성한다.
MySQL과 같은 관계형 데이터베이스를 사용하는 경우에는 사용자와 점수 테이블이 필요하다.
점수 테이블에는 사용자 ID, 점수, 게임에서 승리한 시각(타임스템프)를 저장하여 경연 기록 등과 같은 다른 게임 기능 구현에 활용될 수 있고, 인프라 장애 발생 시 레디스 순위표를 복구하는 데에도 활용할 수 있다.
- 가장 자주 검색되는 상위 10명의 사용자 정보를 캐시하면 쉽게 성능을 최적화 할 수 있다.
3단계: 상세 설계
클라우드 서비스 사용 여부
솔루션 배포 방식은 기존 인프라 구성 형태에 따라 일반적으로 두 가지로 나눌 수 있다.
자체 서비스 사용
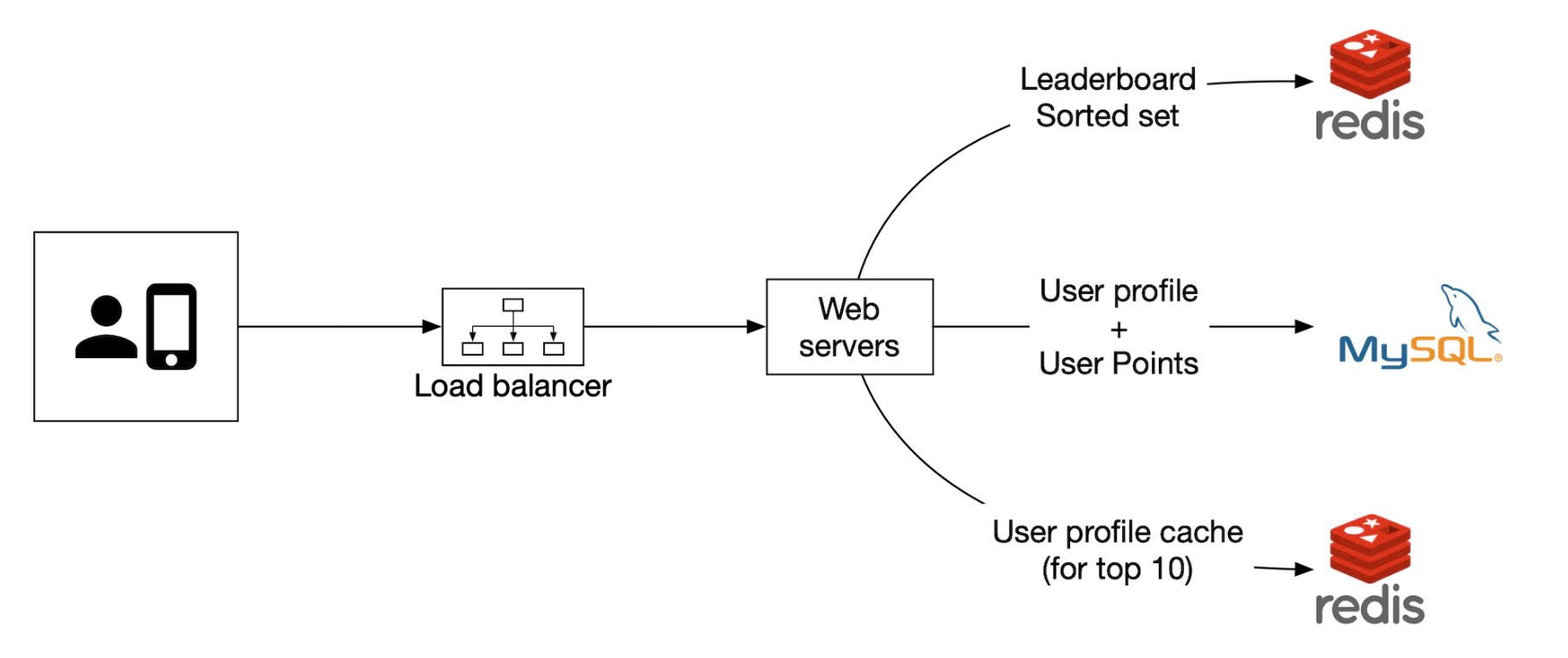
- 매월 정렬 집합을 생성하여 사용자 및 점수 정보를 이용해 해당 기간의 순위표를 저장한다.
- 이름 및 프로필 이미지와 같은 사용자 세부 정보는 MySQL 데이터베이스에 저장한다.
순위표를 가져올 때 API 서버는 순위 데이터와 더불어 데이터베이스에 저장된 사용자 이름과 프로필 이미지도 가져온다.
- 이 작업이 장기적으로 너무 비효율적이면 상위 사용자 10명의 세부 정보를 저장하는 프로필 캐시를 두어 해결할 수 있다.
클라우드 서비스 이용
기존 인프라가 AWS에 있어 클라우드로 순위표를 구축하는 것이 자연스러운 상황이라 가정한다.
아마존 API 게이트웨이와 AWS 람다(Lambda) 두 가지를 활용할 수 있다.
- API 게이트웨이를 사용하면 RESTful API의 HTTP 엔드포인트를 정의하고 아무 백엔드 서비스에나 연결할 수 있다.
| API | 람다 함수 |
|---|---|
GET /v1/scores | LeaderboardFetchTop10 |
GET /v1/scores/{:user_id} | LeaderboardFetchPlayerRank |
GET /v1/scores | LeaderboardUpdateScores |
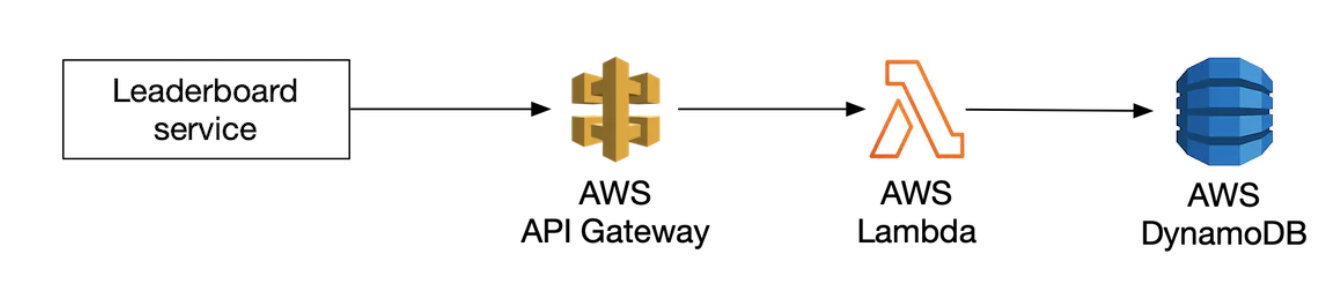
AWS 람다
가장 인기있는 서버리스 컴퓨팅 플랫폼 중 하나로 서버를 직접 준비하거나 관리할 필요 없이 코드를 실행할 수 있다.
람다는 필요할 때만 실행되며 트래픽에 따라 규모가 자동으로 확장된다.
개략적으로 설명하면
- API 게이트웨이를 호출
- 게이트웨이는 적절한 람다 함수를 호출
- 스토리지 계층(레디스 및 MySQL)의 명령을 호출하여 얻은 결과를 API 게이트웨이에 반환
- API 게이트웨이는 그 결과를 애플리케이션에 전달
- 람다 함수를 사용하면 서버 인스턴스를 만들지 않아도 질의를 실행할 수 있다.
- 레디스를 호출할 수 있도록 하는 클라이언트를 제공한다.
- 람다를 사용하면 DAU 성장세에 맞춰 자동으로 서비스 규모를 확장할 수 있다.
점수 획득
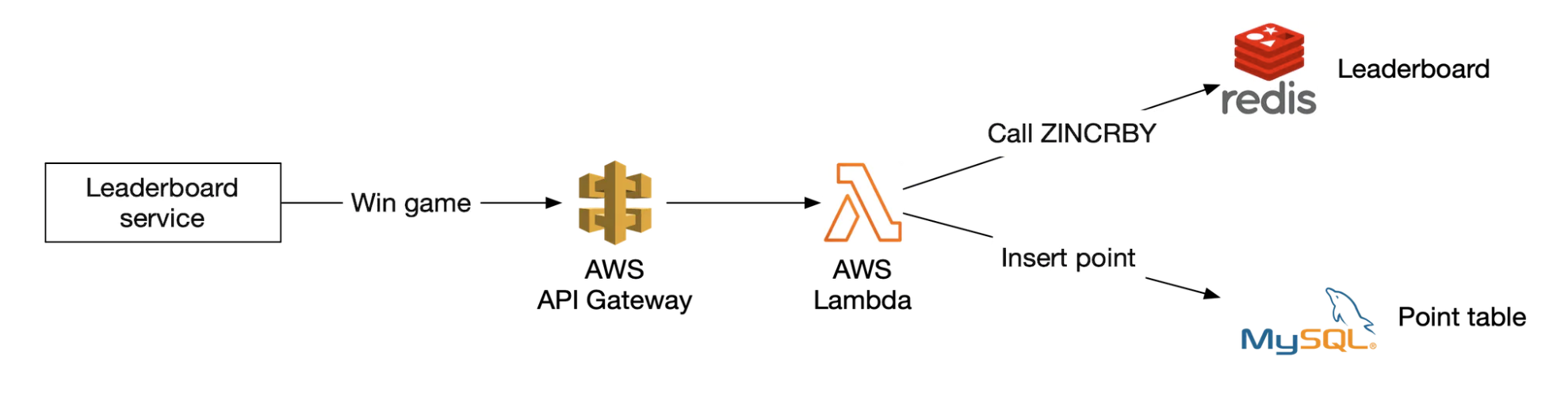
순위 검색
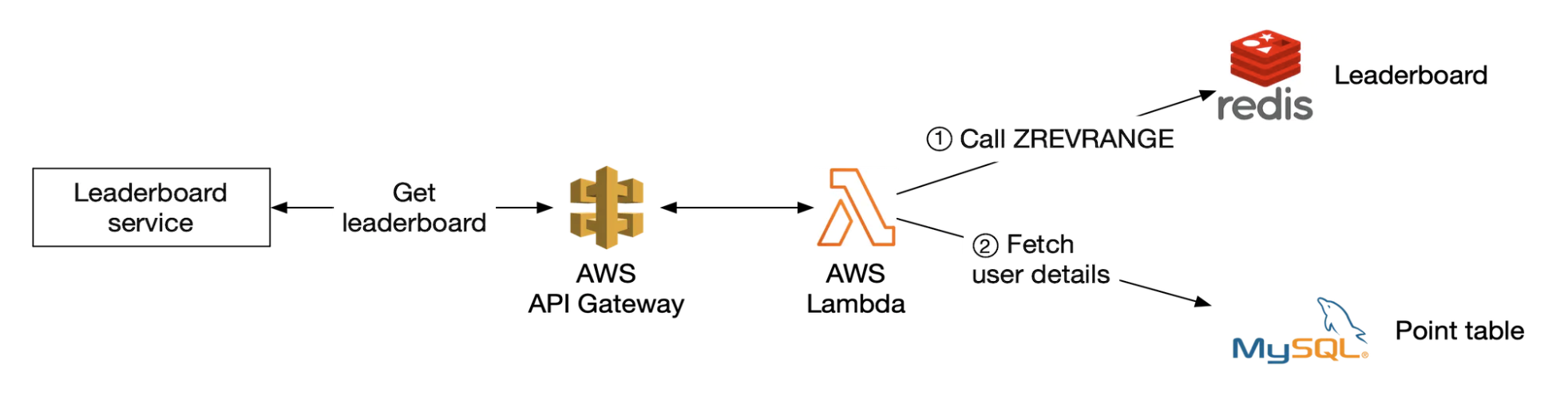
람다는 서비리스 접근 방식이라 인프라의 규모가 필요에 맞게 자동으로 확장되며, 환경 설정, 유지 보수 등의 문제를 직접 관리할 필요가 없다.
레디스 규모 확장
5백만 DAU 정도라면 한 대의 레디스 캐시 서버로도 충분히 지원 가능하나, 원래 규모의 100배인 5억 DAU를 처리해야한다면 규모 확장이 필요하다.
- 저장 용량은 65GB
- 250,000 QPS 처리
이 정도 규모를 감당하려면 샤딩이 필요하다.
데이터 샤딩 방안
고정 파티션과 해시 파티션 방식을 고려할 수 있다.
고정 파티션
순위표에 등장하는 점수의 범위에 따라 파티션을 나누는 방안이다.

- 획득할 수 있는 점수가 1~1000 이라면 데이터를 범위별로 나눈다.
- (1~100), (101~200) …, (901, 1000)
이 기능이 제대로 작동하려면 순위표 전반에 점수가 고르게 분포되어야 하며, 그렇지 않다면 각 샤드에 할당되는 점수 범위를 조정하여 비교적 고른 분포가 되도록 해야한다.
애플리케이션이 샤딩 처리의 추제라면 특정 사용자의 점수를 입력하거나 갱신할 때 해당 사용자가 어느 샤드에 있는지 알아야 한다.
- MySQL 질의로 사용자의 현재 점수를 계산하여 알아낼 수도 있다.
- 사용자 ID와 점수 사이의 관계를 저장하는 2차 캐시를 활용하면 성능을 더 높일 수 있다.
사용자의 점수가 높아져서 다른 샤드로 옮겨야 할 때는 기존 샤드에서 해당 사용자를 제거한 다음 새 샤드로 옮겨야 한다.
순위표에서 상위 10명의 플레이어를 가져오려면, 가장 높은 점수가 저장되는 샤드에서 상위 10명을 가져온다.
특정 사용자의 순위를 알려면 해당 사용자가 속한 샤드 내 순위뿐 아니라 해당 샤드보다 높은 점수를 커버하는 모든 샤드의 모든 사용자 수를 알아야 한다.
- 특정 샤드에 속한 모든 사용자 수는
info keyspace명령을 통해O(1)시간에 알아낼 수 있다.
해시 파티션
레디스 클러스터를 사용하는 방법으로 사용자들의 점수가 특정 대역에 과도하게 모여있는 경우 효과적이다.
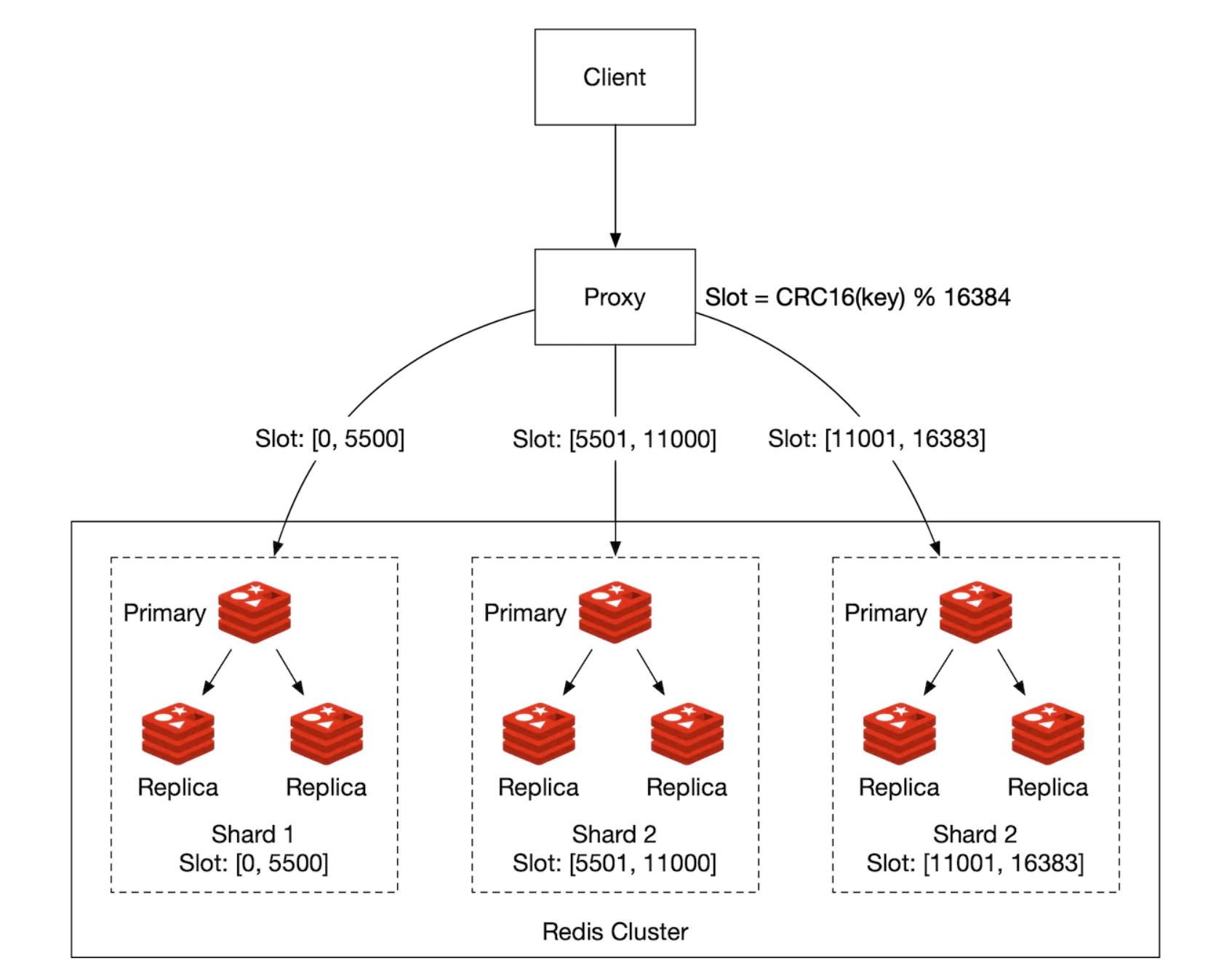
레디스 클러스터
안정 해시는 사용하지 않지만 각 키가 특정한 해시 슬롯에 속하도록 하는 샤딩 기법을 사용한다.
- 총 16384개 해시 슬롯이 있으며,
CRC16(key) % 16384의 연산을 수행하여 어떤 키가 어느 슬롯에 속하는지 계산한다.
모든 키를 재분배하지 않아도 클러스터에 쉽게 노드를 추가하거나 제거할 수 있다.
점수 갱신
점수를 갱신하려면 해당 사용자의 샤드를 찾아(CRC16(key) % 16394) 해당 사용자의 점수를 변경한다.
상위 10명 플레이어 검색
모든 샤드에서 상위 10명을 받아 애플리케이션 내에서 다시 정렬하는 분산-수집(scatter-gather) 접근법을 사용해야 한다.
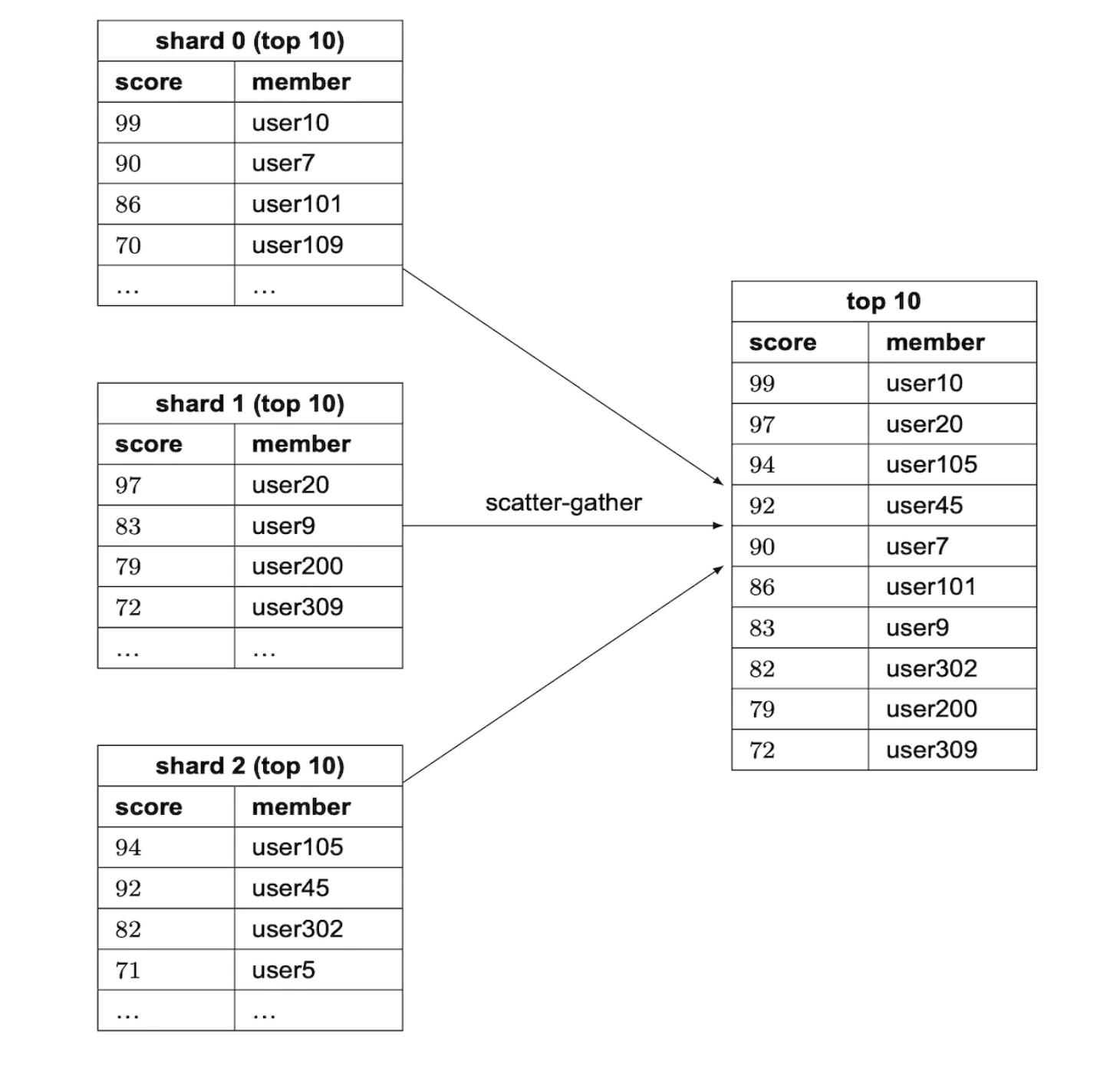
모든 샤드에 사용자를 질의하는 절차를 병렬화하면 지연 시간을 줄일수 있지만 다음과 같은 문제가 있다.
- 상위 k개의 결과를 반환해야 하는 경우(k는 매우 큰 값) 각 샤드에서 많은 데이터를 읽고 정렬해야 하므로 지연 시간이 늘어난다.
- 가장 느린 파티션에서 데이터를 다 읽고 나서야 질의 결과를 계산할 수 있으므로 지연 시간이 길어진다.
- 특정 사용자의 순위를 결정할 간단한 방법이 없다.
따라서 고정 파티션 방안을 활용한다.
레디스 노드 크기 조정
레디스 노드의 크기를 조정할 때 여러가지를 고려해야한다.
쓰기 작업이 많은 애플리케이션에서는 장애에 대비해 스냇숏을 생성할 때 필요한 모든 쓰기 연산을 감당할 수 있어야 하므로 많은 메모리가 필요하다.
- 메모리를 두 배 더 할당하는 것이 안전하다.
레디스는 성능 밴체마킹을 위해 redis-benchmark라는 도구를 제공하므로, 여러 클라이언트가 동시에 여러 질의를 실행하는 것을 실뮬레이션하여 주어진 하드웨어로 초당 얼마나 많은 요청을 처리할 수 있는지 측정할 수 있다.
대안: NoSQL
NoSQL 데이터베이스를 다른 솔루션으로 고려할 수 있으며, 다음과 같은 데이터베이스가 이상적이다.
- 쓰기 연산에 최적화
- 같은 파티션 내의 항목을 점수에 따라 효율적으로 정렬 가능
아마존 DynamoDB, 카산드라, MongoDB 등을 고려할 수 있는데, DynamoDB를 예시로 사용한다.
DynamoDB
안정적인 성능과 뛰어난 확장성을 제공하는 완전 관리형 NoSQL 데이터베이스로, 기본키 이외의 속성을 활용하여 데이터를 효과적으로 질의할 수 있도록, 전역 보조 색인을 제공한다.
전역 보조 색인은 부모 테이블의 속성들로 구성되지만 기본 키는 부모 테이블과는 다르다.
체스 게임의 순위표를 설계하고, 데이터베이스 테이블은 순위표와 사용자 테이블을 비정규화 한 것으로 순위표를 화면에 표시하는 데 필요한 모든 정보를 담고 있다.

이 방안은 레코드가 많아지면 상위 점수를 찾기 위해 전체 테이블을 뒤져야 하므로 사용자가 많아지면 성능이 떨어져 규모 확장이 어렵다.
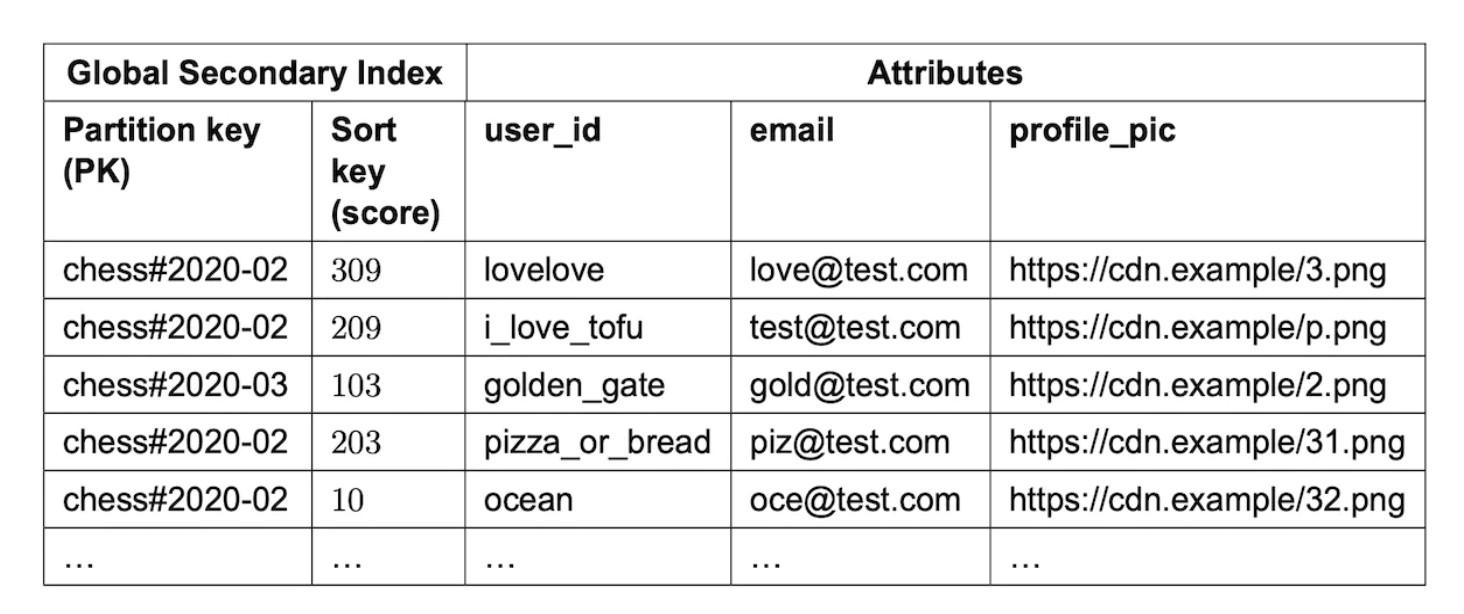
위와 같이 game_name#{year-month}를 파티션 키로, 점수를 정렬 키로 사용하면 테이블 전체를 읽어야 하는 일을 피할 수 있지만, 부하가 높을 때 문제가 발생한다.
DynamoDB는 안정 해시를 사용하여 여러 노드에 데이터를 분산하는데, 각 항목이 파티션 키에 따라 선정된 노드에 저장된다.
위와 같이 테이블을 설계하면 가장 최근 한 달치 데이터가 동일한 파티션에 저장될 뿐 아니라 핫 파티션이 되고 만다.
따라서 데이터를 n개 파티션으로 분할하고 파티션 번호(user_id % number_of_partitinons)를 파티션 키에 추가하는 쓰기 샤딩이라고 부르틑 패턴을 활용할 수 있다.
- 하지만 읽기 및 쓰기 작업 모두를 복잡하게 만드므로, 장단점을 꼼꼼히 따져봐야 한다.
쓰기 볼륨 또는 DAU를 기준으로 파티션의 수를 결정할 수 있으나 파티션이 받는 부하와 읽기 복잡도 사이에는 타협적인 부분이 있다.
- 같은 달 데이터를 여러 파티션에 고르게 분산시키면 한 파티션이 받는 부하는 낮아짐
- 특정한 달의 데이터를 읽으려고 하면 모든 파티션을 질의한 결과를 합쳐야 하므로 구현은 복잡해짐
파티션 키는 game#{year-moth}#p{partition_number}와 같이 지정할 수 있다.
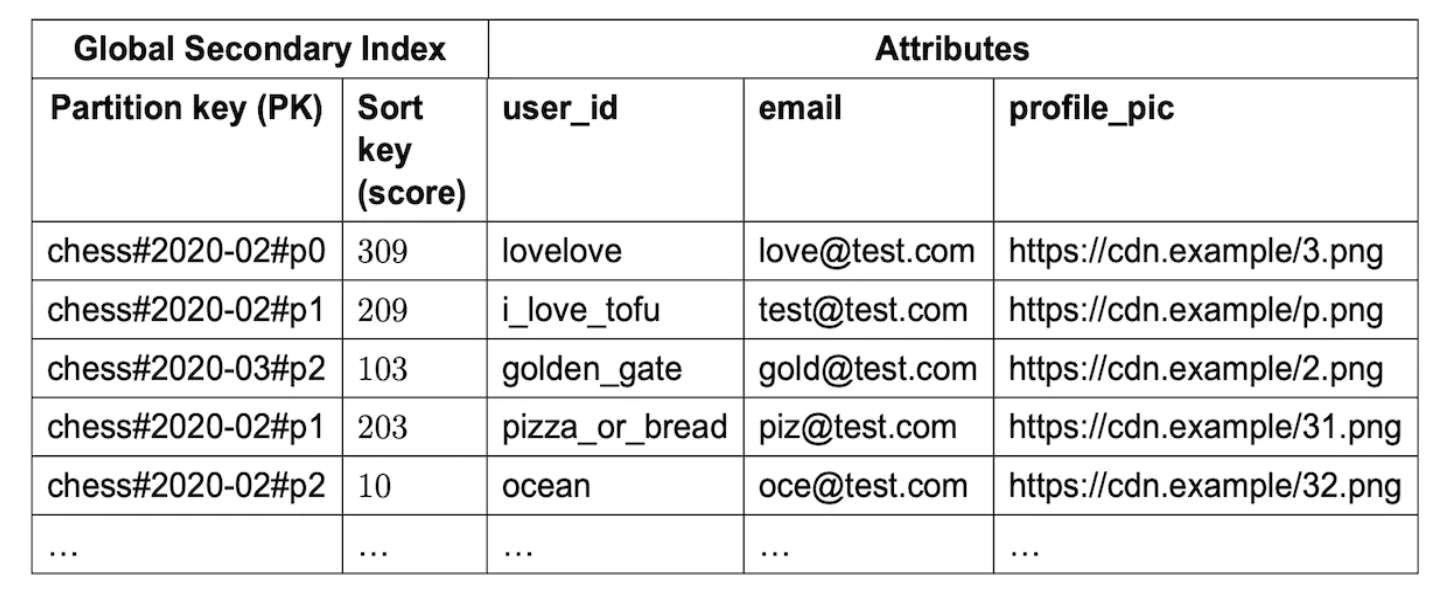
전역 보조 색인은 game#{year-moth}#p{partition_number}를 파티션 키로, 점수를 정렬 키로 사용하게 구성한다.
- 같은 파티션 내 데이터는 전부 점수 기준으로 정렬된 n개의 파티션이 만들어진다.
3개 파티션이 있다고 했을 때 상위 10명의 사용자를 가져오려면 분산-수집 접근법을 사용한다.
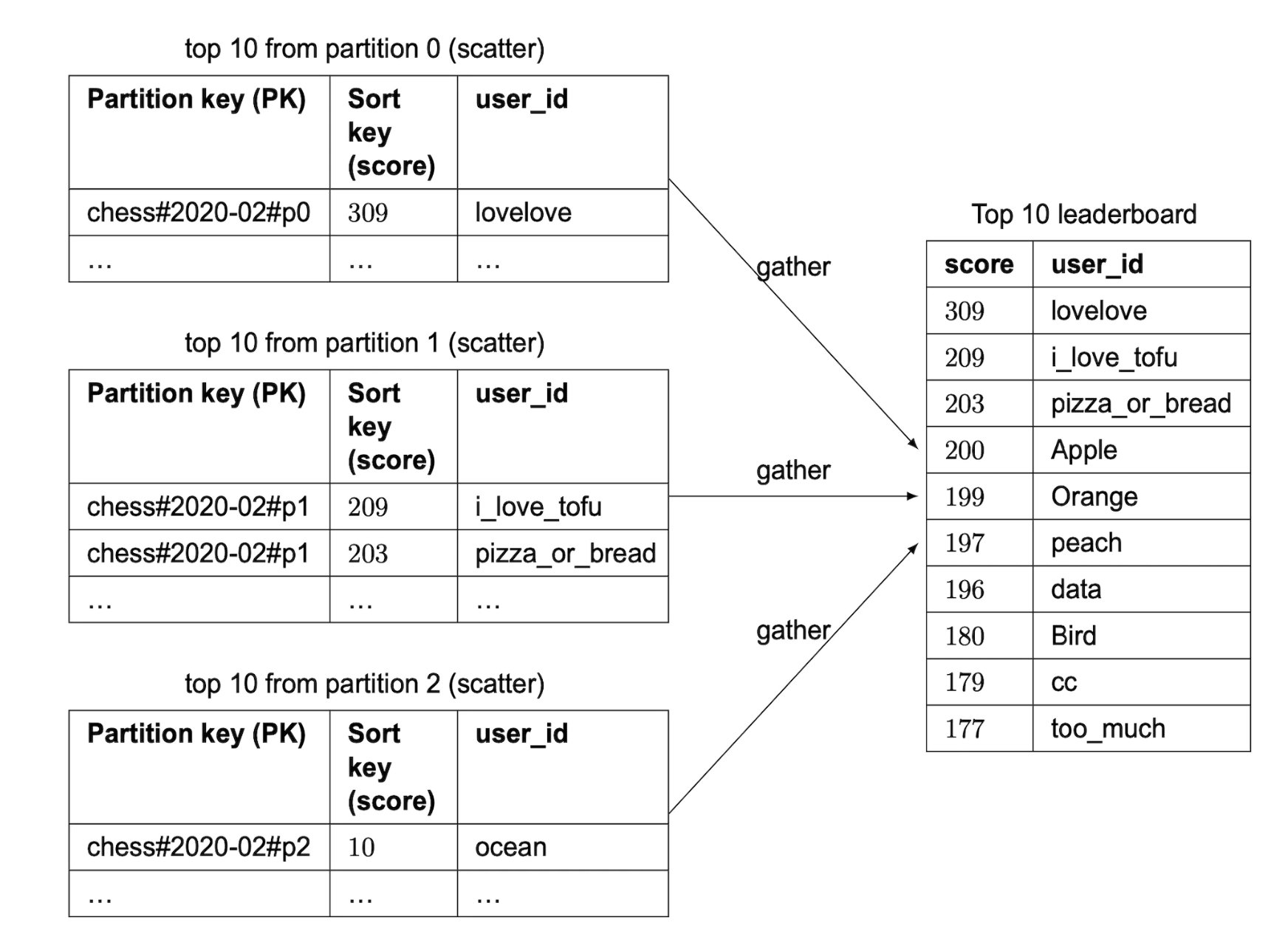
파티션 수는 신중한 벤치마킹이 필요할 수 있다.
- 파티션이 많으면 각 파티션의 부하는 줄지만 최종 순위표를 만들기 위해 읽어야 하는 파티션은 더 많으므로 복잡성은 증가
그러나 앞서 언급한 레디스 파티션 기법과 마찬가지로, 사용자의 상대적 순위를 쉽게 정할 수 없다.
하지만 사용자의 위치의 백분위수를 구하는 것은 가능하며, 충분히 괜찮은 방법일 수 있다.
- ex) 상위 10~20%에 속함
- 규모가 충분히 커서 샤딩이 필요한 상황이라면 모든 샤드의 점수 분포는 거의 같다고 가정할 수 있다.
이 가정이 사실이라면 각 샤드의 점수 분포를 분석한 결과를 캐시하는 크론 작업을 만들어 볼 수도 있다.
| |
이를 통해 사용자의 상대적 순위를 빠르게 계산할 수 있다.
4단계: 마무리
이번 장에서는 수백만 DAU 규모의 실시간 게임 순위표를 구축하기 위한 솔루션을 설계해 보았다.
- MySQL 데이터베이스를 사용하는 간단한 솔루션부터 검토하여, 정렬 집합을 사용하여 순위표를 구현하기로 했다.
- 여러 레디스 캐시에 데이터르 샤딩하여 5억 DAU도 지언할 수 있도록 규모를 확장하는 방안도 살펴보았다.
- 대안으로 NoSQL 데이터베이스를 이용하는 방법도 살펴보았다.
시간이 남는다면 아래와 같은 주제도 살펴볼 수 있을것이다.
더 빠른 조회 및 동점자 순위 판정
레디스 해시를 사용하면 문자열 필드와 값 사이의 대응 관계를 저장해 둘 수 있으며 아래와 같이 활용할 수 있다.
- 순위표에 표시할 사용자 ID와 사용자 객체 사이의 대응 관계를 저장하여 데이터베이스 질의를 줄일 수 있다.
- 동점자는 누가 먼저 점수를 받았는지에 따라 순위를 정할 수 있다.
시스템 장애 복구
레디스 클러스터에도 대규모 장애는 발생할 수 있다.
지금까지 살펴본 설계안에서는 사용자가 게임에서 이길 때마다 MySQL 데이터베이스에 타임 스탬프와 함께 저장하므로, 이를 활용한 스크립트를 만들어 간단히 복구할 수 있다.
- 사용자별로 모든 레코드를 훑으며 레코드당 한 번씩
ZINFRBY를 호출