
MySQL 서버에서 디스크에 저장된 데이터 파일의 크기는 일반저긍로 쿼리의 처리 성능과도 직결되지만 백업 및 복구 시간과도 밀접하게 연결된다.
- 디스크의 데이터 파일이 크면 클수록 쿼리를 처리하기 위해서 더 많은 데이터 페이지를 InnoDB 버퍼풀로 읽어야 할 수 있다.
- 새로운 페이지가 버퍼풀로 적재되기 때문에 그만큼 더티 페이지가 더 자주 디스크로 기록돼야 한다.
- 데이터 파일이 크면 클수록 백업 시간이 오래 걸리며, 복구하는 데도 그만큼의 시간이 걸린다.
- 그만큼 저장 공간이 필요하기 때문에 비용 문제도 있을 수 있다.
많은 DBMS가 이러한 문제점을 해결하기 위해 데이터 압축 알고리즘을 제공하면, MySQL 서버에서 사용 가능한 압축 방식은 크게 테이블 압축과 페이지 압축의 두 가지 종류로 구분할 수 있다.
페이지 압축
페이지 압축은 MySQL 서버가 디스크에 저장하는 시점에 데이터 페이지가 압축되어 저장되고, 반대로 MySQL 서버가 디스크에서 데이터 페이지를 읽어올 때 압축이 해제되어, 버퍼풀에 데이터 페이지가 적재되면 InnoDB 스토리지 엔진은 압축이 해제된 상태로만 데이터 페이지를 관리한다. 이에 따라 서버의 내부 코드에서는 압축 여부와 관계없이 투명(Transparent)하게 작동하여 Transparent Page Compression로 불리기도 한다.
16KB 데이터 페이지를 압축한 결과가 용량이 얼마나 될지 예측이 불가능한데 적어도 하나의 테이블은 동일한 크기의 페이지(블록)로 통일돼야 한다. 따라서 페이지 압축 기능은 운영체제별로 특정 버전의 파일 시스템에서만 지원되는 펀치홀(Punch hole)이라는 방식을 사용한다.
펀치홀이란?
운영체제에서 제공하는 파일 시스템 인터페이스 일부로, 파일 내용에서 일부 데이터 블록을 삭제하여 디스크 공간을 확보하는 기능이다.
이전에는 파일 전체를 복사하고 일부분을 수정하는 드으이 방법으로 파일을 수정해야 했으나 시간과 디스크 공간을 많이 소모하게 되어 펀치홀이 개발되었다.
펀치홀은 일부 운영체제에서만 지원되는 기능이며(리눅스), 대용량 파일 시스템에 사용되어 성능을 향상시키는데 도움을 준다.
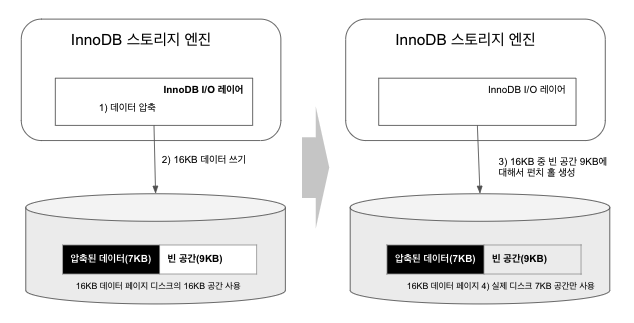
- 16KB 페이지를 압축(압축 결과를 7KB로 가정)
- MySQL 서버는 디스크에 압축된 결과 7KB를 기록(이때 MySQL 서버는 압축 데이터 7KB에 9KB 빈 데이터를 기록)
- 디스크에 데이터를 기록한 후, 7KB 이후의 공간 9KB에 대해 펀치 홀(Punch-hole) 생성
- 파일 시스템은 7KB만 남기고 나머지 디스크의 9KB 공간은 다시 운영체제로 반납
운영체제(파일 시스템)의 블록 사이즈가 512바이트인 경우, MySQL 서버는 특정 테이블에 대해 16KB 크기의 페이지를 유지하면서도 압축된 다양한 크기의 데이터 페이지를 디스크에 저장하고 압축된 만큼의 공간을 절약할 수 있다.
문제점
- 펀치홀 기능은 운영체제뿐만 아니라 하드웨어 자체에서도 지원을 해야 사용 가능하다.
- 아직 파일 시스템 관련 명령어(유틸리티)가 펀치홀을 지원하지 못한다.
MySQL 서버의 데이터 파일은 해당 서버에만 머무는 것이 아니라 백업했다가 복구하는 과정에서 데이터 파일 복사 과정이 실행되고, 그 외에도 많은 파일 관련 유틸리티들을 활용한다. 이러한 이유로 실제 페이지 압축은 많이 사용되지 않는 상태이다.
| |
테이블 압축
테이블 압축은 운영체제나 하드웨어에 대한 제약 없이 사용할 수 있기 때문에 일반적으로 더 활용도가 높은편이다. 테이블 압축은 우선 디스크의 데이터 파일의 크기를 줄일 수 있기 때문에 그만큼의 이득은 있지만, 내부적인 처리 과정과 버퍼풀에서 처리 방식으로 인해 몇가지 단점이 존재한다.
- 버퍼풀 공간 활용률이 낮음
- 쿼리 처리 성능이 낮음
- 빈번한 데이터 변경시 압축률 떨어짐
압축 테이블 생성
테이블 압축을 사용하기 위해 압축을 사용하려는 테이블이 별도의 테이블 스페이스를 사용해야 한다.
- 이를 위해서는
innodb_file_per_table시스템 변수가ON으로 설정된 상태에서 테이블이 생성돼야 한다. - 테이블 압축을 사용하는 테이블들은 테이블을 생성할 때
ROW_FORMAT=COMPRESSED옵션을 명시해야 한다. KEY_BLOCK_SIZE옵션을 이용해 압축된 페이지의 타깃 크기(목표 크기, 2n(n >= 2))를 명시해야 한다.- InnoDB 스토리지 엔진의 페이지 크기가(innodb_page_size)가 16KB 라면
KEY_BLOCK_SIZE는 4KB 또는 8KB만 설정할 수 있다. - 페이지 크기(
innodb_page_size)가 32KB or 64KB인 경우에는 테이블 압축을 적용할 수 없다.
- InnoDB 스토리지 엔진의 페이지 크기가(innodb_page_size)가 16KB 라면
| |
innodb_file_per_table시스템 변수가 0 인 상태에서 제너럴 테이블스페이스(General Tablespace)에 생성되는 테이블도 테이블 압축을 사용할 수 있으나, 제너럴 테이블스페이스의 FILE_BLOCK_SIZE에 의해 압축을 사용하지 못할 수 있다.
테이블 압축 동작 방식
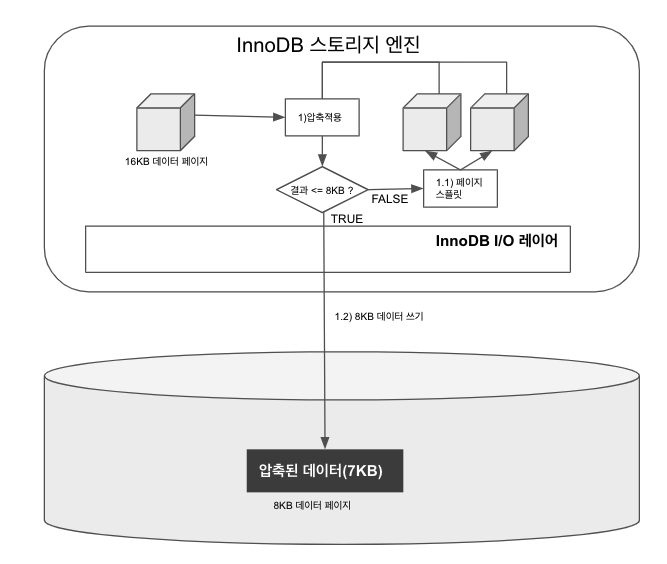
현재 InnoDB스토리지 엔진의 데이터 페이지 크기가 16KB, KEY_BLOCk_SIZE가 8로 설정되었다면,
- 16KB의 데이터 페이지를 압축
- 압축된 결과가 8KB 이하이면 그대로 디스크에 저장
- 압축된 결과가 8KB를 초과하면 원본 페이지를 스플릿(split)해서 2개의 페이지에 8KB씩 저장
- 나뉜 페이지 각각에 대해 “1” 단계를 반복 실행
테이블 압축 방식에서 가장 중요한 것은 원본 데이터 페이지의 압축 결과가 목표 크기(KEY_BLOCK_SIZE)보다 작거나 같을 때까지 반복해서 페이지를 스플릿하는 것이다.
따라서 목표 크기가 잘못 설정되면 MySQL 서버의 처리 성능이 급격히 떨어질 수 있다.
KEY_BLOCK_SIZE 결정
테이블 압축에서 가장 중요한 부분은 압축된 결과가 어느 정도가 될지 예측해서 KEY_BLOCK_SIZE를 결정하는 것이다.
따라서 테이블 압축을 적용하기 전에 먼저 KEY_BLOCK_SIZE를 4KB 또는 8KB로 테이블을 생성하여 샘플 데이터를 저장해 보고 적절한지 판단하는 것이 좋다.
이때 샘플 데이터는 많으면 많을수록 더 정확한 테스트가 가능한데, 최소한 테이블 데이터 페이지가 10개 정도는 생성되도록 테스트 데이터를 INSERT해보는 것이 좋다.
| |
결과
| … | index_name | … | compression_failure_pct |
|---|---|---|---|
| PRIMARY | 27.6737 | ||
| ix_firstname | 8.0168 | ||
| ix_hiredate | 13.4561 |
실패율이 높다는 의미는 압축 결과가 4KB를 초과하여 데이터 페이지를 스플릿해서 다시 압축을 많이 했다는 뜻이다. 일반적으로 압축 실패율은 3~5%미만으로 유지하는 것이 좋으며 이에 맞추어 KEY_BLOCk_SIZE를 적절히 조절해야 한다.
KEY_BLOCk_SIZE를 크게 설정하였는데도 압출 실패율이 높게 나타난다면, InnoDB 버퍼풀에서 디스크로 기록되기 전에 압축하는 과정에 꽤 오랜 시간이 걸릴 것으로 예측 가능하다. 성능에 민감한 서비스라면 압축을 적용하지 않는 것이 좋을 수 있다.
압축 실패율이 높다고 해서 무조건 압축을 사용하지 말아야 한다는 것을 의미하지는 않는다.
INSERT만 되는 로그 테이블은 실패율이 높다고 하더라도 데이터 파일의 크기가 큰 폭으로 줄어든다면 큰 손해는 아닐 수 있다.
반대로 실패율이 낮다고 해서 무조건 압축을 적용하는 것도 좋지 않을 수 있다.
- 알고리즘 실행에 적지 않은 CPU 자원을 소비하므로, 테이블의 데이터가 빈번하게 조회되고 변경되는 경우 압축을 적용하지 않는 것이 좋을 수 있다.
압축된 페이지의 버퍼풀 적재 및 사용
InnoDB 스토리지 엔진은 압축된 테이블의 데이터 페이지를 버퍼풀에 적재하면 압축된 상태와 압축이 해제된 생태 2개 버전을 관리한다. 따라서 InnoDB 스토리지 엔진은 디스크에서 읽은 상태 그대로의 데이터 페이지 목록을 관리하는 LRU 리스트와 압축된 페이지들의 압축 해제 버전인 Unzip_LRU 리스트를 별도로 관리하게 된다.
- 결국 InnoDB 스토리지 엔진은 압축된 테이블에 대해서는 버퍼풀의 공간을 이주응로 사용함으로써 메모리를 낭비하게 된다.
- 압축된 페이지에서 데이터를 읽거나 변경하기 위해서 압축을 해제해야하므로 CPU를 상대적으로 많이 소모한다.
이러한 단점을 보완하기 위해 Unzip_LRU 리스트를 별도로 관리하고 있다가 MySQL 서버로 유입되는 요청 패턴에 따라 적절히 다음과 같은 처리를 수행한다.
- InnoDB 버퍼풀 공간이 필요한 경우에는 LRU 리스트에서 원본 데이터 페이지(압축)는 유지하고, Unzip_LRU 리스트에서 압축 해제된 버전은 제거해서 버퍼풀의 공간을 확보한다.
- 압축된 데이터 페이지가 자주 사용되는 경우에는 Unzip_LRU 리스트에 압축 해제된 페이지를 계속 유지하면서 압축 및 압축 해제 작업을 최소화한다.
- 압축된 데이터 페이지가 사용되지 않아서 LRU 리스트에서 제거되는 경우에는 Unzip_LRU 리스트에서도 함께 제거된다.
InnoDB 스토리지 엔진은 버퍼풀에서 압축 해제된 버전의 데이터 페이지를 적절한 수준으로 유지하기 위해 다음과 같은 어댑티브 알고리즘을 사용한다.
- CPU 사용량이 높은 서버에서는 가능하면 압축과 압축 헤제를 피하기 위해 Unzip_LRU의 비율을 높에서 유지한다.
- Disk IO 사용량이 높은 서버에서는 가능하면 Unzip_LRU 리스트의 비율을 낮춰 InnoDB 버퍼풀 공간을 더 확보하도록 작동한다.
테이블 압축 관련 설정
테입르 압축을 사용할 때 연관된 시스템 변수가 몇가지 있는데, 모두 페이지의 압축 실패율을 낮추기 위해 필요한 튜닝 포인트를 제공한다.
innodb_cmp_index_enable
테이블 압축이 사용된 테이블의 모든 인덱스별로 압축 성공 및 압축 실행 횟수를 수집하도록 설정한다.- 비활성화시 테이블 단위의 압축 성공 및 실행 횟수만 수집
- 테이블 단위 수집된 정보:
infoamtion_schema.INNODB_CMP테이블에 기록 - 인덱스 단위 수집된 정보:
infoamtion_schema.INNODB_CMP_PER_INDEX테이블에 기록
innodb_compression_level
InnoDB의 데이터 압축은zlib알고리즘만 지원하는데, 시스템 변수를 이용해 압축률을 설정할 수 있다(0~9).- 값이 커질수록 느려지고, 작아진다.
- 기본값은 6
innodb_compression_failure_threshold_pct
테이블 단위로 압축 실패율이 시스템 설정값 보다 커지면 압축을 실행하기 전 원본 데이터 페이지 끝에 의도적으로 일정 크기의 빈 공간을 추가한다.- 추가된 빈 공간은 압축률을 높여서 압축 결과가
KEY_BLOCK_SIZE보다 작아지게 만드는 효과를 낸다. - 추가하는 빈 공간을 패딩이라고 하며, 패딩 공간은 실패율이 높아질수록 계속 증가된 크기를 가진다.
- 추가된 빈 공간은 압축률을 높여서 압축 결과가
innodb_log_compressed_pages
MySQL 서버가 비정상적으로 종료됐다가 다시 시작되는 경우 압축 알고리즘의 버전 차이가 있더라도 복구 과정이 실패하지 않도록 InnoDB 스토리지 엔진은 압축된 데이터 페이지를 그대로 리두 로그에 기록한다.- 압축 알고리즘을 덥그레이드 할 대 도움이 되지만, 데이터 페이지를 통째로 로그에 저장하는 것은 리두 로그의 증가량에 상당한 영향을 미칠수도 있다.
- 압축을 적용한 후 리두 로그 용량이 매우 빠르게 증가한다건아 버퍼풀로부터 더티 페이지가 한꺼번에 많이 기록되는 패턴으로 바뀌었다면, 해당 변수를 OFF로 설정하여 모니터링 해보는 것이 좋다.
- 기본값은 ON, 가능하면 기본값 상태를 유지하자.