
MySQL 복제에서는 레플리카 서버에서 소스 서버로부터 복제된 트랜잭션들을 하나의 스레드가 아닌 여러 스레드로 처리할 수 있게 하는 멀티 스레드 복제 기능을 제공한다.
소스 서버에서는 여러 세션에서 실행된 DML 쿼리들이 동시에 처리되는데, 소스 서버에서 짧은 시간 동안 다량의 DML 쿼리가 실행되는 경우 MySQL 5.6 버전 미만의 레플리카 서버에서는 하나의 스레드가 모든 트랜잭션을 처리하므로 복제 동기화에 지연이 발생한다.
또한 하나의 스레드로만 복제가 동기화 되는것은 멀티코어 CPU가 장착된 서버를 사용하는 환경에서는 서버의 자원을 충분히 활용하지 못하는 비효율적인 방식이었다.
flowchart LR
a[Relay Log]-->b([Coordinator Thread])
subgraph Worker 1
direction LR
c[[Queue]] -->
d([Worker Thread])
end
subgraph Worker 2
direction LR
e[[Queue]] -->
f([Worker Thread])
end
subgraph Worker N
direction LR
g[[Queue]] -->
h([Worker Thread])
end
b-->c
b-->e
b-->g
기존 단일 스레드 복제에서는 레플리케이션 SQL 스레드가 릴레이 로그 파일을 읽어서 바로 트랜잭션을 적용하는 형태였다면 멀티 스레드 복제에서는 SQL 스레드는 코디네이터 스레드(Coordinator Thread)로 불리며, 실제로 이벤트를 실행하는 스레드인 워커 스레드와 협업해서 동기화를 진행한다.
- 코디네이터 스레드는 릴레이 로그 파일에서 이벤트들을 읽은 뒤 설정된 방식에 따라 스케줄링 해서 워커 스레드에 각 이벤트를 할당한다.
- 각 이벤트는 워커 스레드들의 큐에 적재되며 워커 스레드는 큐에서 이벤트들을 꺼내 순차적으로 레플리카 서버에 적용한다.
멀티 스레드 복제는 소스 서버로부터 복제된 트랜잭션들을 어떻게 병렬로 처리할 것인가에 따라 데이터베이스 기반과 LOGICAL CLOCK 기반 처리 방식으로 나뉜다.
slave_parallel_type- 병렬 처리 방식 설정
- 기본적으로 데이터베이스 기반 방시긍로 설정
parallel_workers시스템 변수를 통해 워커 스레드의 개수를 지정할 수 있다.- 0 ~ 1024 까지 설정 가능
- 1로 설정하면 스레드 복제를 위한 코드 블록이 모두 실행되면서 실제 복제는 단을 스레드처럼 처리됨
- 0으로 설정시 단일 스레드 모드로 복제 수행, 부가적인 작업 처리를 수행하지 않음
slave_pending_jobs_size_max- 시스템 변수를 통해 워커 스레드의 큐에 할당할 수 있는 최대 메모리 크기를 설정
- MySQL 8.0 기본값은 128MB
- 작은 이벤트들이 빈번하게 발생하는 OLTP 환경에서는 기본값도 문제 없음
- 소스 서버로부터 전달받은 이벤트 크기가 설정된 값을 초과하는 경우 모든 워커 스레드들의 큐가 바위질 때 까지 대기후 처리됨
- 복제 지연이 발생할 수 있으므로 적절히 큰 값 설정 필요
SHOW PROCESSLIST 명령을 통해 코디네이터 스레드와 워커 스레드를 확인할 수 있다.
데이터 베이스 기반 멀티 스레드 복제
데이터베이스 기반 멀티 스레드 복제 방식은 스키마 기반 처리 방식이라고도 하며, 멀티 스레드 복제가 처음 도입됐을 때 유일하게 사용할 수 있었던 방식이다.
데이터 베이스 기반 멀티 스레드 복제는 MySQL 내의 데이터베이스 단위로 병렬 처리를 수행하는 형태를 말한다.
- MySQL 서버에 데이터베이스가 하나밖에 존재하지 않는다면 장점을 가지지 못한다.
- 여러 개의 데이터베이스가 있다면 레플리카 서버에서는 데이터베이스 개수 만큼 워커 스레드 수를 설정하는 것이 좋다.
코디네이터 스레드는 릴레이 로그 파일에서 이벤트를 읽어 데이터베이스 단위로 분리하고 각 워커 스레드에게 이벤트들을 할당한다.
flowchart LR
a[트랜잭션 3: UPDATE DB3
UPDATE DB1
트랜잭션 2: UPDATE DB2
트랜잭션 3: UPDATE DB1]
b([코디네이터 스레드])
c([워커 스레드 1
1. UPDATE DB1
트랜잭션 1])
d([워커 스레드 2
2. UPDATE DB2
트랜잭션 2])
e([워커 스레드 3
3. UPDATE DB3
트랜잭션 3])
a--4. UPDATE DB1
트랜잭션 3-->b
b-->c
b-->d
b-->e
위의 트랜잭션 3의 마지막 처리인 UPDATE DB1 같은 경우 워커 스레드 1이 이미 처리중이므로 해당 작업을 완료될때까지 기다리게 된다.
- 데이터베이스 기반 멀티 스레드 복제에서는 테이블이나 레코드 수준까지의 충돌 여부는 고려하지 않고 데이터베이스가 동일한지만 비교하기때문에, 변경 대상 테이블이나 레코드는 다르다고 하더라도 대기한다.
- 트랜잭션 3의
UPDATE DB1이 대기하고 있는 상황에서, 워커 스레드 2의 작업이 이미 완료되고 네 번째 트랜잭션으로 또 다른 DB2 변경 작업이 들어온다고 하더라도 대기하게 된다.
이러한 처리로 인해 서로 다른 데이터베이스를 참조하는 쿼리나 트랜잭션이 빈번하게 실행되는 경우 예상했던 것보다 멀티 스레드 처리 효율이 낮아질 수 있다.
- 하지만 MySQL 서버에 여려 개의 데이터베이스가 존재하고 각 데이터베이스에 유입되는 DML이 서로 독립적이면서 균등하게 실행되는 환경이라면 데이터기반 멀티 스레드 복제가 단일 스레드 복제보다 월등한 처리량을 보인다.
데이터베이스 기반 멀티 스레드 복제를 사용하려면 레플리카 서버를 다음과 같이 설정 후 복제를 연결하면 된다.
- 기존에 이미 단일 스레드 복제가 진행되고 있는 상황에서 데이터베이스 기반 멀티 스레드 복제로 전환하고 싶다면 SQL 스레드만 멈춘 후 멀티 스레드 복제를 설정하고 다시 시작하면 된다.
| |
데이터베이스 기반 멀티 스레드 복제에서는 레플리카 서버가 자체적으로 바이너리 로그를 가지고 log_slave_updates 있고 옵션이 활성화되어 있을 때 소스 서버의 바이너리 로그에 기록된 트랜잭션 순서와 레플리카 서버의 바이너리 로그에 기록된 트랜잭션 순서가 다를 수 있다.
- 레플리카 서버의 멀티 스레드 복제 동기화에서 각 트랜잭션이 처리된 시점에 따라 실제 소스 서버에서 실행된 것과는 순서가 달라질 수 있기 때문
- 소스 서버에서 가장 최근에 싫애된 트랜잭션을 레플리카 서버에서 확인한다고 했을 때 소스 서버에서 그 트랜잭션 이전에 실행된 모든 트랜잭션들이 레플리카 서버에도 전부 실행되었다고 보장하긴 어렵다.
LOGICAL CLOCK 기반 멀티 스레드 복제
MySQL 5.7 버전부터 소스 서버로부터 넘어온 전체 트랜잭션들을 데이터베이스에 종속되지 않고 멀티 스레드로 처리하는, 즉 같은 데이터베이스 내에서도 멀티 스레드 동기화 처리가 가능한 LOGICAL CLOCK 방식이 도입되어 데이터 베이스 기반 멀티 스레드 복제의 아쉬움을 해소할 수 있게 되었다.
LOGICAL CLOCK 기반 멀티 스레드 복제는 소스 서버에서 트랜잭션들이 바이너리 로그로 기록될 때 각 트랜잭션별로 논리적인 순번 값을 부여해 레플리카 서버에서 트랜잭션의 순번 값을 바탕으로 정해진 기준에 따라 병렬로 실행하는 방식이다.
트랜잭션이 병렬로 처리될 수 있다고 여겨지는 기준은 같은 상황에서도 세부 처리 방식에 따라 달라딘다.
- Commit-parent 기반 방식
- 잠금(Lock) 기반 방식
- WriteSet 기반 방식
바이너리 로그 그룹 커밋
MySQL 5.5 버전까지는 InnoDB 스토리지 엔진에서 한 시점에 하나의 트랜잭션만 커밋될 수 있었으며, 바이너리 로그에 트랜잭션을 기록하고 디스크와 동기화하는 부분도 마찬가지로 여러 트랜잭션이 동시에 진행될 수 없었다.
sequenceDiagram
클라이언트->>MySQL: COMMIT;
MySQL->>스토리지 엔진: prepare;
MySQL->>바이너리 로그: write;
MySQL->>바이너리 로그: fsync;
MySQL->>스토리지 엔진: commit;
MySQL-->>클라이언트: OK;
클라이언트로부터 커밋 요청이 들어오면 MySQL 서버에서는 Prepare, Commit 두 단계를 거쳐 머닛을 처리하는데, 이를 분산 트랜잭션 이라고 한다.
- 분산 트랜잭션은 트랜잭션을 커밋할 때 스토리지 엔진에 적용된 내용과 바이너리 로그에 기록된 내용 간의 일관성을 유지하기 위해 사용된다.
커밋을 처리하는 과정에서 바이너리 로그에 기록한 내용을 디스크와 동기화하는 fsync 작업은 sync_binlog 시스템 변수에 설정된 값에 따라 실행 여부와 실행 빈도수가 결정된다
- 1: 트랜잭션이 커밋될 때마다 디스크 동기화를 수행
- 빈번하게 수행되는 디스크 동기화 작업은 서버에 부하가 발생한다.
- 트랜잭션 처리량 저하를 야기한다.
이 같은 처리 성능 저하 문제를 개선하기 위해 MySQL 5.6 버전에서는 여러 트랜잭션에 대한 커밋을 동시에 진행할 수 있게 바뀌었고, 바이너리 로그 단의 처리 또한 여러 트랜잭션을 함께 처리할 수 있도록 바이너리 로그 그룹 커밋 기능이 도입되었다.
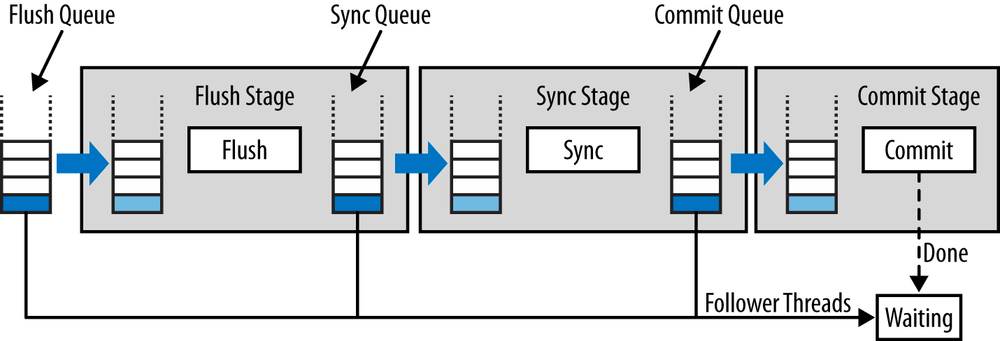
바이너리 로그 그룹 커밋에서 트랜잭션들은 커밋 처리 과정 중 Prepare이후 바이너리 로그 관련 처리를 진핼할 때 세 단계를 거치면서 최종적으로 그룹 커밋된다.
- 트랜잭션들은 순서대로 대기 큐에 등록된다.
- 비어있는 대기 큐에 첫번째로 등록된 트랜잭션을 리더(Leader)라고 하며, 이후 등록된 다른 트랜잭션들은 팔로워(Follower) 라고 한다.
- 팔로워는 리더에게 자신의 트랜잭션 처리에 대한 모든 것을 일임하며, 리더는 큐에 등록된 모든 팔로워들을 가져와 처리하고 다음 단계의 대기 큐에 등록한다.
- 다음 단계의 큐에 등록될 때는 큐가 비어있지 않은 경우 리더는 팔로워가되고 해당 큐의 리더가 그 단계에서의 처리를 주도하게 된다.
- 리더는 팔로워가 될 수 있으나 팔로워는 절대 리더가 될 수 없다.
각 단계의 트랜잭션들은 다음과 같이 처리된다.
- Flush 단계
- 대기 큐에 등록된 각 트랜잭션들을 순서대로 바이너리 로그에 기록한다.
- Sync 단계
- 앞서 기록된 바이너리 로그 내용들을 디스크와 동기화하는
fsync()시스템 콜이 수행된다. sync_binlog옵션에 설정된 값에 따라 디스크 동기화 수행- 트랜잭션 별로 동기화가 수행되는 것이 아닌 트랜잭션 그룹에 대해 동기화가 수행됨
- 대기 큐에 트랜잭션들이 많을수록 효율적으로 처리됨
- Sync 단계의 대기 큐에 많은 트랜잭션을 쌓기 위해 시스템 변수를 설정하여 실행을 지연할 수 있음
binlog_group_commit_sync_delay:
동기화 작업을 얼마정도 지연시킬지 제아하는 변수(마이크로 초)binlog_group_commit_sync_no_delay_count:
동기화 작업이 진행되기 전에 지연되어 대기할 수 있는 최대 트랜잭션 수
- Commit 단계
- 대기 큐에 등록된 트랜잭션들에 대해 스토리지 엔진 커밋을 진행한다.
- 스토리지 엔진 커밋은 대기 큐에 등록된 순서대로 혹은 병렬로도 처리될 수 있다.
- 대기 큐에 등록된 순서대로 커밋되는 경우 대기 큐의 리더에 의해 처리가 진행
- 이러한 경우 트랜잭션들은 바이너리 로그에 기록된 순서와 스토리지 엔진에 커밋된 순서가 일치하게 된다.
- 병렬로 처리되는 경우 리더가 아닌 각 트랜잭션들이 커밋을 수행하게 된다.
- 시스템 변수를 통해 트랜잭션들이 커밋되는 순서를 제어할 수 있다.
binlob_order_commit: 바이너리 로그 파일에 기록된 순서대로 스토리지 엔진에 커밋됨
Commit-parent 기반 방식
멀티 스레드 복제 동기화가 처음 도입됐던 버전에서 적용된 방식으로, 동일 시점에 커밋된 트랜잭션들을 레플리카 서버에서 병렬로 실행될 수 있게 한다.
- 커밋 시점이 같은 트랜잭션들은 잠금 경합 등과 같이 서로 충돌하는 부분이 없는 트랜잭션들이므로 병렬로 실행될 수 있다는 부분에서 착안됨.
Commit-parent 기반 방식이 적용된 MySQL 버전을 사용하는 레플리카 서버에서 LOGICAL CLOCK 멀티 스레드 동기화가 활성화되어 있는 경우 소스 서버에서 같은 시점에 커밋된 트랜잭션들을 복제 동기화할 때 병렬로 처리한다.
- MySQL 서버는 같은 시점에 커밋 처리된 트랜잭션들을 식별할 수 있도록, 바이너리 로그에 트랜잭션을 기록할 때
commit_clock이라는 64비트 정수값을 기반으로 한다.- 각 트랜잭션이 커밋을 위해 Prepare 단계에 진입했을 때 설정되며 그 당시의 commit clock 값이 저장된다.(최종적으로 커밋되기 전에 값이 증가함)
- 같은 시점에 커밋 처리가 시작된 트랜잭션들은 동일한
commit_seq_no값을 가지며, 복제된 트랜잭션들의 해당 값을 바탕으로 같은 값을 가진 트랜잭션들을 병렬로 수행한다.
병렬 처리 기준인 commit_seq_no 값이 앞서 커밋된 트랜잭션 순번 값에 해당하므로 이 방식을 Commit-parent 기반 방식이라고 한다.
sequenceDiagram
0->>1:Tx1 C=0;
1->>2:Tx2 C=1;
2->>3:Tx3 C=2;
3->>4:Tx4 C=3;
4->>5:Tx5 C=4;
4->>6:Tx6 C=4;
4->>7:Tx7 C=4;
4->>8:Tx8 C=6;
6->>9:Tx9 C=6;
8->>10:Tx10 C=8;
Commit-parent 기반에서는 소스 서버에서 같은 그룹으로 커밋된 트랜잭션 수가 많을수록 레플리카 서버에서의 트랜잭션 병렬 처리율이 향상된다.
사용자는 소스 서버에서 binlog_group_commit_sync_delay 시스템 변수와 binlog_group_commit_sync_no_delay_count 시스템 변수에 적절한 값을 설정해 그룹 커밋되는 트랜잭션 수를 늘릴 수 있다.
- 소스 서버에서 트랜잭션들의 처리 속도를 느리게 하는 대신, 레플리카 서버에서의 처리 속도를 높이는 방법이다.
- 소스 서베에서 트랜잭션을 실행하는 클라이언트들이 영향을 받을 수 있으므로 설정을 변경한 후 주의 깊게 모니터링 해야한다.
잠금 기반 방식
기존 Commit-parent 기반 방식에서는 단순하게 마지막으로 커밋된 선행 트랜잭션의 순번 값이 동일한 트랜잭션들만 레플리카 서버에서 병렬로 처리할 수 있었다.
그러나 잠금 기반 방식에서는 선행 트랜잭션의 순번 값이 동일하지 않더라도 커밋 처리 시점이 겹친다면 그 트랜잭션들은 레플리카 서버에서 병렬로 처리될 수 있다.
이를 위해 MySQL 서버에서는 트랜잭션을 바이너리 로그에 기록할 때 sequence_number와 last_committed라는 값을 함께 기록한다.
- sequence_number
- 커밋된 트랜잭션에 대한 논리적인 순번 값으로, 매 트랜잭션이 커밋될 때마다 값이 증가한다.
- last_committed
- 현 트랜잭션 이전에 커밋된 가장 최신 트랜잭션의 sequence_number 값이 저장된다.
- 바이너리 파일이 새로운 파일로 로테이션 되는 경우 sequence_number 값은 1, last_committed 값은 0으로 초기화된다.
잠금 기반 LOGICAL CLOCK 방식이 적용된 MySQL 버전을 사용하는 레플리카 서버에서는 LOGICAL CLOCK 멀티 스레드 동기화가 활성화돼 있는 경우 별렬로 트랜잭션을 실행할 때 다음과 같은 조건을 기준으로 트랜잭션들의 실행 가능 여부를 결정한다.
- 실행하려는 트랜잭션의 last_committed < 현재 실행중인 트랜잭션들이 가지는 가장 작은 sequence_number
sequenceDiagram
0->>1:Tx1 C=0, S=1;
1->>2:Tx2 C=1, S=2;
2->>3:Tx3 C=2, S=3;
3->>4:Tx4 C=3, S=4;
4->>5:Tx5 C=4, S=5;
4->>6:Tx6 C=4, S=6;
4->>7:Tx7 C=4, S=7;
4->>8:Tx8 C=6, S=7;
6->>9:Tx9 C=6, S=9;
8->>10:Tx10 C=8, S=10;
잠금 기반 방식에서는 트랜잭션들이 레플리카 서버로 복제됐을 때 다음과 같이 처리된다.
| 트랜잭션 | 처리 |
|---|---|
| Tx1, Tx2, Tx3, Tx4 | 병렬 처리 가능 조건을 충족하지 않으므로 순차적으로 하나씩 실행됨 |
| Tx5, Tx6, Tx7 | 병렬 처리 기능 조건을 충족하므로 병렬로 실행 가능 |
| Tx8, Tx9 | Tx6이 종료되고 Tx7이 아직 실행 중인 경우 Tx8, Tx9는 Tx7과 같이 실행될 수 있음(Tx8, 9의 last_committed 값보다 Tx7의 sequence_number 값이 크므로) |
| Tx10 | Tx8이 종료되고 Tx9가 실행 중일 때 Tx9과 함께 실행 가능 |
잠금 기반 방식은 소스 서버에서 커밋 처리 시점이 겹치는 트랜잭션들의 수가 많을 수록 레플리카 서버에서 최대한 병렬로 처리되므로 Commit-parent 기반 방식과 동일하게 소스 서버에서 그룹 커밋되는 트랜잭션 수에 영향의 받는다.
- 잠금 기반 방식에서도 소스 서버의 시스템 변수 값을 적절히 조정해서 레플리카 서버에서의 병렬 처리율을 향상시킬 수 있다.
WriteSet 기반 방식
WriteSet 기반 방식은 트랜잭션의 커밋 처리 시점이 아닌 트랜잭션이 변경한 데이터를 기준으로 병렬 처리 가능 여부를 결정한다.
기존 잠금 기반 방식에서는 다음과 같이 커밋 처리 시점이 전혀 겹치지 않는 두 트랜잭션은 병렬로 실행될 수 없었다.
| |
WriteSet 기반 방식에서는 두 트랜잭션이 서로 다른 데이터를 변경하는 것이라면 병렬로 실행할 수 있다.
- 동일한 데이터를 변경하지 않는 트랜잭션들은 레플리카 서버에서 모두 병렬로 실행될 수 있다.
WriteSet 기반에서는 같은 세션에서 실행된 트랜잭션들의 병렬 처리 여부에 따라 WRITESET과 WRITESET_SESSTION 타입으로 나눠진다.
binlog_transaction_dependency_tracking시스템 변수로 설정 가능하다.- COMMIT_ORDER
- 기본값으로 잠금 기반 방식과 동일하게 동작한다.
- WRITESET
- 서로 다른 데이터를 변경한 트랜잭션들은 모두 병렬로 처리될 수 있다.
- WRITE_SESSION
- WRITE_SET 처리에서 동일한 세션에서 실행된 트랜잭션들은 병렬로 처리될 수 없다는 점만 다르다.
WriteSet 기반 방식에서는 각 트랜잭션에서 변경한 데이터를 기주능로 병렬 처리를 위한 트랜잭션들의 종속 관계를 정의하므로 이를 위해 내부적으로 트랜잭션에 의해 변경된 데이터들의 목록을 관리한다.
- 변경된 데이터들은 하나하나가 전부 해시값으로 표현된다.
- 해싱된 변경 데이터를 WriteSet이라고 한다.
- WriteSet은 테이블에 존재하는 유니크한 키의 개수만큼 만들어진다. 따라서 하나의 변경 데이터는 여러 개의 WriteSet을 가질 수 있다.
| |
트랜잭션들의 WriteSet은 MySQL 서버 메모리에서 해시맵 테이블로 그 히스토리가 관리된다.
- 히스토리 테이블에는 변경된 데이터의 해시값인 WriteSet과 해당 데이터를 변경한 트랜잭션의 sequence_number 값이 Key-Value 형태로 저장된다.
- 사용자는
binlog_transaction_dependency_histroy_size시스템 변수를 통해 히스토리 테이블이 최대로 가질 수 있는 WriteSet 개수를 정할 수 있다(기본값 25000).- 저장된 데이터 수가 지정된 최대 개수만큼 도달하면 히스토리 테이블은 초기화된다.
- DDL 쿼리가 실행된 경우에도 초기화된다.
WriteSet 기반 방식에서도 마찬가지로 트랜잭션이 커밋되면 바이너리 로그에 트랜잭션 정보와 함께 last_committed 값과 sequence_number 값이 기록되며, 레플리카 서버에서는 이를 바탕으로 병렬 처리를 수행한다.
- WRITESET, WRITESET_SESSION 타입 모두 트랜잭션 커밋을 처리할 때 트랜잭션의 last_committed 값을 1차적으로 COMMIT_ORDER 타입 기반으로 설정한다.
- 이후 WriteSet 히스토리 테이블 데이터를 조회해서 트랜잭션의 WriteSet과 충돌하는 WriteSet의 존재 여부를 확인 후 다시 last_committed 값을 설정하게 된다.
처리 과정
- WriteSet 히스토리 테이블에서 가장 작은 sequence_number 값을 자신의 last_committed 값으로 설정한다.
- WriteSet을 히스토리 테이블에서 찾는다.
- 충돌하는 데이터가 있을 경우 이 해시값에 매핑된 sequence_number 값을 자신의 sequence_number 값으로 변경한다.
- 기존 sequence_number 값은 자신의 last_committed 값으로 설정한다.
- 기존 sequence_number 값이 자신의 last_committed 값보다 크지 않을 경우 변경하지 않는다.
- 충돌하는 데이터가 없는 경우 히스토리 테이블에 자신의 sequence_number 값과 함께 해당 데이터를 저장한다.
- 충돌하는 데이터가 있을 경우 이 해시값에 매핑된 sequence_number 값을 자신의 sequence_number 값으로 변경한다.
트랜잭션에서는 WriteSet 히스토리 테이블에 자신의 WriteSet과 충돌되는 WriteSet 데이터가 존재하는 경우 그 WriteSet에 매핑된 sequence_number 값을 가져와 자신의 last_committed에 저장하고 해상 WriteSet의 sequence_number를 자신의 sequence_number 값으로 업데이트한다.
- 충돌하는 WriteSet이 여러개이고 WriteSet이 다른 sequence_number 값을 가지는 경우 가장 큰 sequence_number로 업데이트된다.
- 충돌하는 WriteSet이 없다면 해당 트랜잭션이 가진 WriteSet들이 히스토리 테이블에 새로 저장되고 WriteSet 중 가장 작은 sequence_number로 저장된다.
WRITESET_SESSION 타입에서는 이렇게 결정된 last_committed 값을, 같은 세션에서 커밋된 마지막 트랜잭션의 sequnece_number 값과 한번 더 비교해서 둘 중 더 큰값을 선택해 last_committed에 저장한다.
- WRITESET과 WRITESET_SESSION 타입 모드 트랜잭션에서 변경된 데이터들이 속하는 테이블이 유니크한 키를 가지고 있지 않은 경우 해당 트랜잭션의 WriteSet은 생성되지 않으며, last_committed에는 COMMIT_ORDER 타입 기반으로 결정된 값이 그대로 사용된다.
- 변경된 데이터들이 속하는 테이블의 유니크한 키들이 다른 테이블에서 외래키로 참조되는 경우에도 같은 방식으로 처리된다.
WriteSet 기반 방식에서는 레플리카 서버에서의 트랜잭션 병렬 처리가 소스 서버에서 동시에 커밋되는 트랜잭션 수에 의존적이지 않으므로 그룹 커밋되는 트랜잭션 수를 늘리기 위해 의도적으로 소스 서버의 트랜잭션 커밋 처리 속도를 저하시킬 필요가 없다.
- 체인 형태로 복제가 구성돼 있는 경우 하위 계층의 레플리카 서버로 갈수록 병렬로 처리되는 트랜잭션 수가 점점 줄어드는 문제는 WRITESET 타입을 사용하면 병렬 처리량 감소 문제를 해결할 수 있다.
WriteSet 기반 방식은 어느 방식보다도 레플리카 서버에서의 병렬 처리성을 높이는 방식이지만 트랜잭션 커밋 시 추가적인 메모리 공간이 필요하며 매 트랜잭션마다 WriteSet 히스토리 테이블에 저장된 값들을 계속 비교해야 하므로 이에 따른 오버헤드가 발생한다.
멀티 스레드 복제와 복제 포지션 정보
멀티 스레드 복제에서 각 워커 스레드들이 실행한 바이너리 로그 이벤트의 포지션 정보는 relay_log_info_repository 시스템 변수에 지정된 값에 따라 mysql 데이터베이스 내 slave_worker_info 테이블 혹은 데이터 디렉터리 내 worker-relay-log.info 접두사를 가지는 파일들에 각 스레드별로 저장되며, 워커 스레드들은 이벤트를 실행 완료할 때마다 해당 데이터를 갱신한다.
현재 복제 이벤트의 처리 현황을 보여주는 어플라이어 메타데이터에는 워커 스레드들이 실행한 이벤트들에서 로우 워터마크에 해당하는 이벤트의 포지션 값이 저장된다.
- 코디네이터 스레드가 수행하는 체크포인트 작어베 의해 주기적으로 갱신된다.
- 갭이 존재하는 경우 체크포인트 지점은 항상 갭 이전에 실행 완료된 이벤트에서만 나타날 수 있다.
- 먼저 실행된 트랜잭션보다 나중에 실행된 트랜잭션이 먼저 처리되었을 때 발생하는 포지션 간격을 갭(Gap)이라고 한다.
- 멀티 스레드 복제에서
slave_preserve_commit_order시스템 변수가 비활성화되어있는 경우 발생한다.- 레플리카 서버에서 복제를 통해 넘어온 이벤트를 소스 서버에서 커밋된 순서와 동일한 순서로 커밋할 것인지를 제어
- 1로 설정시 여러 이벤트들이 동시에 처리돼도 릴레이 로그에 기록된 수서대로 커밋되어 갭이 발생하지 않는다.
- 갭이 발생하지 않는다 하더라도 어플라이어 메타데이터는 워커 스레드들이 처리한 이벤트 내역이 실시가능로 반영된 데이터가 아니라 체크포인트 주기마다 갱신되는 데이터므로 실제 적용된 이벤트의 포지션 값보다 이전의 포지션 값을 보여준다. (명령을 통한 조회도 동일함)
코디네이터 스레드는 다음 시스템 변수들에 설정된 값을 바탕으로 워커 스레드들에서 실행된 이벤트들에 대해 체크포인트를 수행해 어플라이어 메타데이터를 갱신한다.
slave_checkpoint_period- 어플라이어 메타데이터 갱신 작업의 주기를 결정하는 시스템 변수(기본값 300 (밀리초))
slave_checkpoint_group- 어플라이어 메타데이터 갱신 작업의 주기를 결정하는 시스템 변수로 실행한 트랜잭션의 개수를 지정함