
파티션 기능은 테이블을 논리적으로는 하나의 테이블이지만 물리적으로는 여러 개의 테이블로 분리해서 관리할 수 있게 해준다.
- 주로 대용량 테이블을 물리적으로 여러 개의 소규모 테이블로 분산하는 목적으로 사용한다.
- 파티션 기능을 사용하더라도 어떤 쿼리를 사용하느냐에 따라 오히리 성능이 더 나빠지는 경우도 발생할 수 있다.
MySQL 파티션이 적용된 테이블에서 INSERT나 SELECT 같은 쿼리가 어떻게 실행되는지 이해한다면 파티션을 어떻게 사용하는 것이 가장 최적일지 쉽게 이해할 수 있다.
파티션을 사용하는 이유
테이블의 데이터가 많아진다고 해서 무조건 파티션을 적용하는 것이 효율적인 것은 아니다.
- 하나의 테이블이 너무 커서 인덱스의 크기가 물리적인 메모리보다 훨씬 큰 경우
- 데이터 특성상 주기적인 삭제 작업이 필요한 경우
단일 INSERT와 단일 또는 범위 SELECT의 빠른 처리
데이터베이스에서 인덱스는 일반적으로 SELECT를 위한 것으로 보이지만 UPDATE나 DELETE 쿼리를 위해 필요한 때도 많다.
물론 레코드를 변경하는 쿼리를 실행하면 인덱스 변경을 위한 부가적인 작업이 발생하지만 처리 대상 레코드를 검색하려면 인덱스가 필수적이지만 인덱스가 커지면 커질수록 느려지는 단점이 있다.
특히 한 테이블의 인덱스 크기가 물리적으로 MySQL이 사용 가능한 메모리 공간보다 크다면 영향은 더 심각하다.
테이블의 데이터는 실질적인 물리 메모리보다 큰 것이 일반적이겠지만, 인덱스의 워킹 셋이 실질적인 물리 메모리보다 크다면 쿼리 처리가 상당히 느려진다.
파티션하지 않고 하나의 큰 테이블로 사용하면 인덱스도 커지고 그만큼 물리적인 메모리 공간도 많이 필요하므로, 파티션을 통해 데이터와 인덱스를 조각화해서 물리적 메모리를 효율적으로 사용할 수 있게 만들어준다.
데이터의 물리적인 저장소를 분리
데이터 파일이나 인덱스 파일이 파일 시스템에서 차지하는 공간이 크다면 그만큼 백업이나 관리 작업이 어려워진다. MySQL은 테이블의 데이터나 인덱스를 파일 단위로 관리하기 때문에 더 치명적인 문제가 될 수 있다.
이러한 문제는 파티션을 통해 파일의 크기를 조절하거나 파티션별 파일들이 저장될 위치나 디스크를 구분해서 지정해 해결하는 것도 가능하다.
하지만 MySQL에서는 테이블의 파티션 단위로 인덱스를 생성하거나 파티션별로 다른 인덱스를 가지는 형태는 지원하지 않는다.
이력 데이터의 효율적인 관리
거의 모든 애플리케이션이 로그라는 이력 데이터를 가지고 있는데, 이는 단기간에 대량으로 누적됨과 동시에 일정 기간이 지나면 쓸모가 없어진다.
로그 데이터는 결국 시간이 지나면 별도로 아카이빙하거나 백업한 후 삭제해버리는 것이 일반적이며, 특히 다른 데이터에 비해 라이프 사이클이 상당히 짧다.
로그 테이블에서 불필요해진 데이터를 백업하거나 삭제하는 작업은 일반 테이블에서는 상당히 고부하 작업에 속한다.
- 로그 테이블을 파티션 테이블로 관리한다면 풀필요한 데이터 삭제 작업은 단순히 파티션을 추가하거나 삭제하는 방식으로 간단하고 빠르게 해결할 수 있다.
MySQL 파티션의 내부 처리
| |
파티션 테이블의 레코드 INSERT
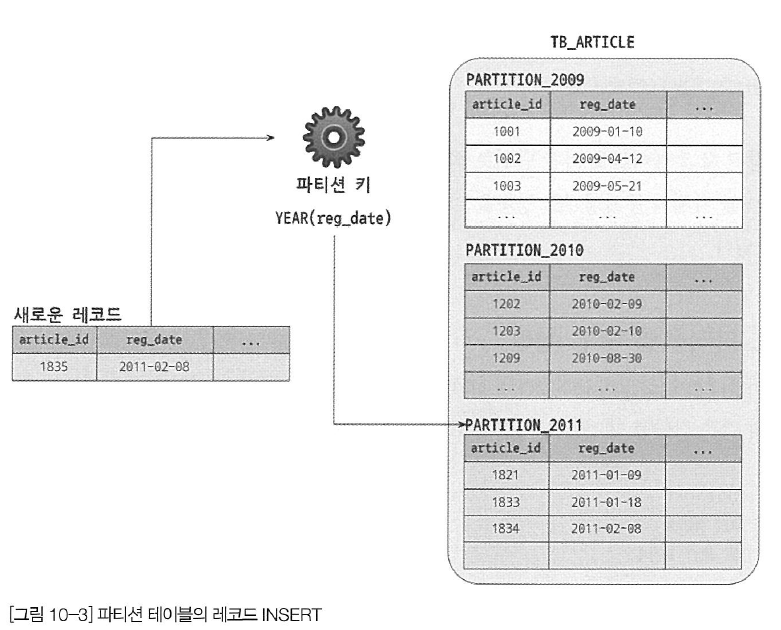
INSERT 쿼리가 실행되면 MySQL 서버는 INSERT되는 컬럼의 값 중에서 파티션 키인 reg_date 컬럼의 값을 이용해 파티션 표현식을 평가하고, 그 결과를 이용해 레코드가 저장될 적절한 파티션을 결정한다.
새로 INSERT되는 레코드를 위한 파티션이 결정되면 나머지 과정은 파티션 되지 않은 일반 테이브로가 동일하게 처리된다.
파티션 테이블의 UPDATE
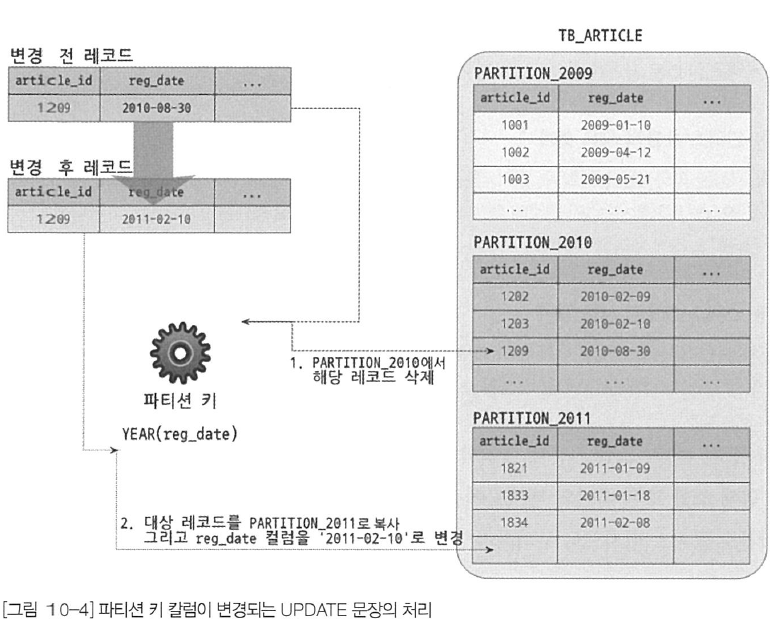
UPDATE 쿼리를 실행하려면 변경 대상 레코드가 어느 파티션에 저장돼 있는지 찾아야 하는데, 이때 WHERE 조건에 파티션 키 컬럼이 조건으로 존재한다면 그 값을 이용해 레코드가 저장된 파티션에서 빠르게 대상 레코드를 검색할 수 있다.
- 하지만
WHERE조건에 파티션 키 컬럼의 조건이 면시되지 않았다면 변경 대상 레코드를 찾기 위해 모든 파티션을 검색한다.
실제 레코드를 변경하는 작업의 절차는 UPDATE 쿼리가 어떤 컬럼의 값을 변경하느냐에 따라 큰 차이가 생긴다.
- 파티션 키 이외의 컬럼만 변경될 때는 파티션이 적용되지 않은 일반 테이블과 마찬가지로 컬럼 값만 변경한다.
- 파티션 키 컬럼이 변경될 때는 기존 레코드가 저장된 파티션에서 해당 레코드를 삭제하고, 변경되는 파티션 키 컬럼의 표현식을 평가하여 새로운 파티션을 결정하여 새로 저장한다.
파티션 테이블의 검색
파티션 테이블을 검색할 때 성능에 크게 영향을 미치는 조건은 다음과 같다.
WHERE절의 조건으로 검색해야 할 파티션을 선택할 수 있는가?WHERE절의 조건이 인덱스를 효율적으로 사용(인덱스 레인지 스캔)할 수 있는가?
파티션 테이블에서는 첫 번째 선택사항의 결과에 의해 두 번째 선택사항의 작업 내용이 달라질 수 있다.
- 파티션 선택 가능 + 인덱스 효율적 사용 가능
- 가장 효율적으로 처리 될 수 있다.
- 파티션 개수와 관계없이 검색을 위해 꼭 필요한 파티션의 인덱스만 레인지 스캔한다.
- 파티션 선택 불가 + 인덱스 효율적 사용 가능
- 모든 파티션을 대상으로 검색해야 한다.
- 각 파티션에 대해서는 인덱스 레인지 스캔을 사용할 수 있기 때문에 최종적으로 테이블에 존재하는 모든 파티션의 개수만큼 인덱스 레인지 스캔을 수행해서 검색하게된다.
- 파티션 개수 만큼의 테이블에 대해 인덱스 레인지 스캔 후 결과를 병합해서 가져오는 것 과 같다.
- 파티션 선택 가능 + 인덱스 효율적 사용 불가
- 검색을 위해 필요한 파티션만 읽는다.
- 대상 파티션에 대해 풀 테이블 스캔을 한다.
- 각 파티션의 레코드 건수가 많다면 상당히 느리게 처리될것이다.
- 파티션 선택 불가 + 인덱스 효율적 사용 불가
- 모든 파티션에 대해 풀 테이블 스캔을 한다.
파티션 테이블의 인덱스 스캔과 정렬
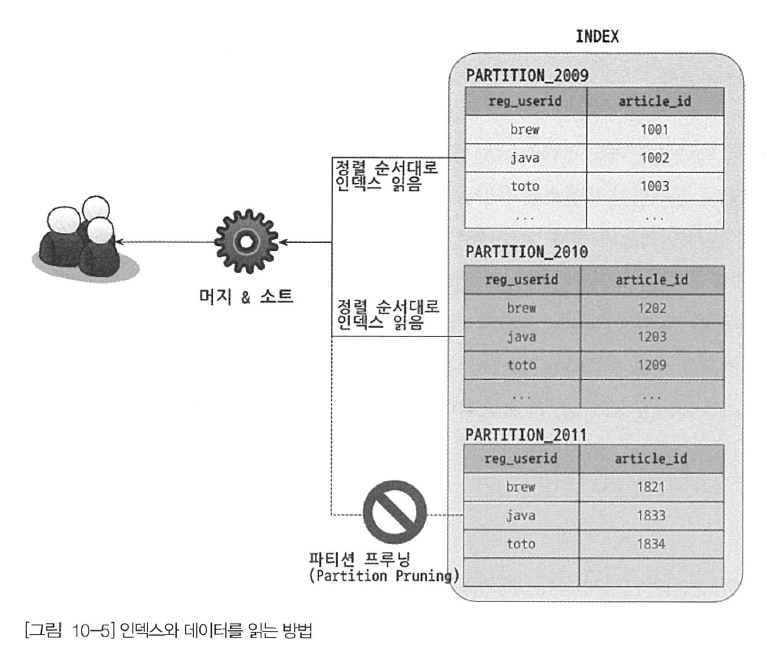
파티션 테이블에서 인덱스는 전부 로컬 인덱스에 해당한다.
- 모든 인덱스는 파티션 단위로 생성된다.
- 파티션과 관계없이 테이블 전체 단위로 글로벌하게 하나의 통합된 인덱스는 지원하지 않는다.
파티션이 되지 않는 테이블에서는 인덱스를 순서대로 읽으면 크 컬럼으로 정렬된 결과를 바로 얻을 수 있지만, 파티션된 테이블은 그렇지 않다.
| |
- MySQL 서버는 여러 파티션에 대해 인덱스 스캔을 수행할 때 각 파티션으로부터 조건에 일치하는 레코드를 정렬된 순서대로 읽으면서 우선순위 큐에 임시로 저장한다.
- 파티션 테이블에서 인덱스 스캔을 통해 레코드를 읽을 때 별도의 정렬 작업을 수행하지는 않으며, 내부적으로 큐 처리가 필요하다.
파티션 프루닝
옵티마이저에 의해 불필요한 파티션에는 전혀 접근하지 않는데, 이렇게 최적화 단계에서 필요한 파티션만 골라내고 불필요한 것들은 실행 계획에서 배제하는 것을 파티션 프루닝이라 한다.