
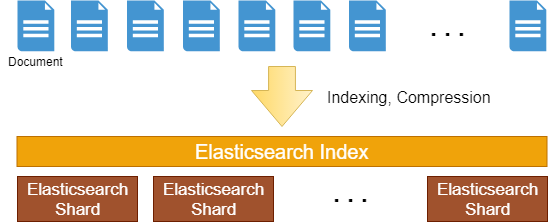
엘라스틱서치는 검색 엔진인 아파치 루씬 (Apache Lucene)으로 구현한 RESTful API 기반의 검색 엔진이다. 엘라스틱서치 아키텍쳐는 클러스터 기반으로 구성되어 있다.
클러스터 기본 특징
수평 확장
클러스터를 사실상 무한으로 확장할 수 있다.인덱스 샤딩
엘라스틱서치는 인덱스를 조각내서 “샤드 (shard)“라는 조각난 데이터로 만든다. 때문에 나누어진 데이터를 편하게 각 호스트에 분리해서 보관할 수 있다.
엘라스틱서치 특징
Schemaless와 문서지향
엘라스틱 서치는 JSON 구조를 사용하여 기존 RDBMS와 같은 엄격한 구조를 적용하지 않는다.
- 스키마가 다이나믹하게 변할 수 있다
전통적인 관계형 구조로 구성할 경우 프로젝트 막바지에 모든 스키마르 ㄹ변경하고, 데이터를 다시 구성하는 문제에 봉착할 수 있는데 JSON 구조는 이런 문제들을 사전에 막을 수 있다. - 데이터 공간을 절약할 수 있다.
컬럼을 동적으로 정의하여, 필요한 데이터만 넣게 되어 데이터 공간 및 CPU 사용량, 네트워크 트래픽도 줄일 수 이쓴 효과를 볼 수 있다.
검색능력(Searching)
기본적인 검색 기능 뿐만 아니라 특히 Full-text 검색 능력이라는 강력한 기능을 탑재하고 있다.
관계형 데이터베이스의 문자열 컬럼에 대해 실행되는 단순한 SQL 질의와는 다르다.
기본적으로 엘라스틱은 검색을 할 수 있는 Term(의미의 최소한위)로 단어의 형태소 분석을 수행하고, 이 단어들과 연관된 문서를 매핑하여 검색을 시켜주는 개념으로 문서를 통쨰로 like 검색하는 DB와는 구조적으로 다르다.
분석(Analytics)
엘라스틱 서치를 탑재하여 만든 사이트에 접속하는 사람들의 OS가 무엇인지, 어느나라에서 접속했는지 등을 알고 싶을 때 분석 기능을 사용하면 편리하게 알 수 있다.
풍부한 API와 REST 지원
기본적으로 20개의 프로그래밍 언어를 지원하며, 기본적으로 REST API를 제공하여 REST API를 사용하는 모든 언어에서 HTTP 형식으로 사용할 수 있다.
쉬운 작동, 쉬운 확장
Single Node Instance로 작동하며, 수백개의 스케일 아웃을 쉽게 할 수 있다. 대부분의 빅데이터 플랫폼들이 그러하듯 Horizontal Scaling을 사용한다.
Near real-time(근접 실시간)
검색엔진은 기본적으로 형태소를 분석하고 색인을 해야 하는 시간이 다른 DBMS보다 오래 걸린다. 엘라스틱 역시 데이터를 삽입한 순간 약 몇 초 정도는 이 단계를 거친 후 검색을 할 수 있다.
Lightning-fast (빠른 속도)
엘라스틱 서치의 DNA는 루씬이기 떄문에 단어 입력후 문서를 찾는 속도가 다른 NoSQL들에 비해 매우 빠르다.
Fault-tolerant(내고장성)
노드 실패시 replicate된 다른 노드에서 데이터를 가져오며, 네트워크 실패 시 다른 마스터 복제본으로 선택한다.
엘라스틱서치 데이터 구조

엘라스틱서치는 위와 같이 문서를 엘라스틱 인덱스로 만든 뒤, 샤드로 분리하여 보관한다.
샤드는 논리적/물리적으로 분할 된 인덱스인데, 각각의 엘라스틱서치 샤드는 루씬 인덱스이기도 하다.
루씬은 새로운 문서를 엘라스틱서치 인덱스에 저장할 때 “세그먼트"를 생성하는데, 루씬의 인덱스 조각인 이 세그먼트를 조합해 저장한 데이터의 검색을 할 수 있다.
색인 처리량이 매우 중요할 때는 세그먼트를 더 생성하기도 한다. 루씬은 순차적으로 세그먼트를 검색하므로 세그먼트 수가 많아지면 검색속도도 따라서 느려지게 된다.
엘라스틱서치 데이터 설명
인덱스(색인)
데이터를 저장 및 색인 하는 곳으로, 관계형 DB의 데이터베이스 개념과 유사하다.
- 실제로는 각 샤드를 가리키고 있는 논리적인 네임스페이스
Shard
샤드는 엘라스틱서치에서 사용하는 검색 엔진인 루씬의 인스턴스.
- 인덱스를 한 개의 샤드로 구성할 수도 있지만, 인덱스 사이즈가 증가할 경우 여러개의 물리서버에 나누어 보관하기 위해 보통은 여러개의 샤드로 구성함.
Segment
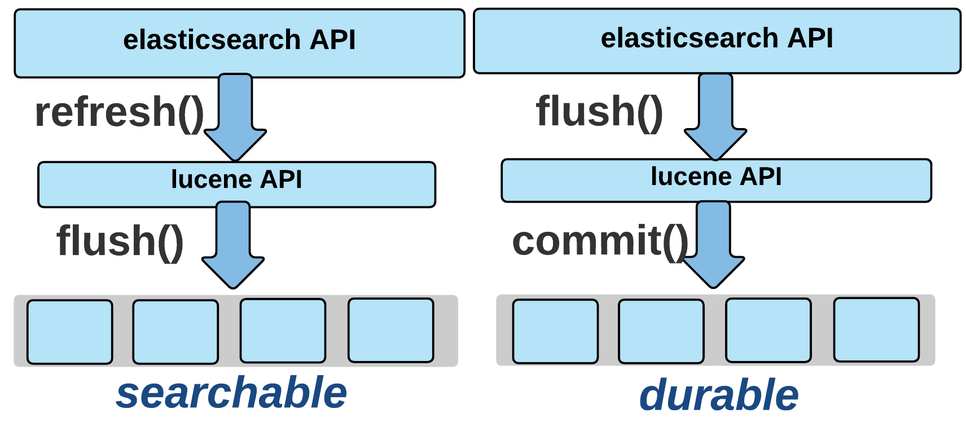
각 샤드는 다수의 세그먼트를 가지고 있고, 샤드에서 검색 시, 먼저 각 세그먼트를 검색하여 결과를 조합한 최종 결과를 해당 샤드의 결과로 리턴하게 된다.
searchable
엘라스틱서치에 데이터(문서)를 저장하면, 엘라스틱서치는 이것을 메모리에 모아두고 새로운 세그먼트를 디스크에 기록하여 검색을 리프레시함. 이로 인해 새로운 검색 가능한 세그먼트가 만들어지게 된다.
commited
그러나 세그먼트가 fsync되지 않았으므로 여전히 데이터 손실의 위험이 남아있다. 그래서 엘라스틱서치는 세그먼트를 fsync하는 “flush"를 주기적으로 진행하고, 불필요한 트랜젝션 로그를 비운다.
merge process
세그먼트는 불변임, 데이터(document)가 업데이트되면 실제로는 그저 삭제되었다고 마크하고 새로운 데이터(document)를 가리킬 뿐이다. 이러한 오래된 삭제된 데이터를 지우는 것
엘라스틱서치 클러스터 구조
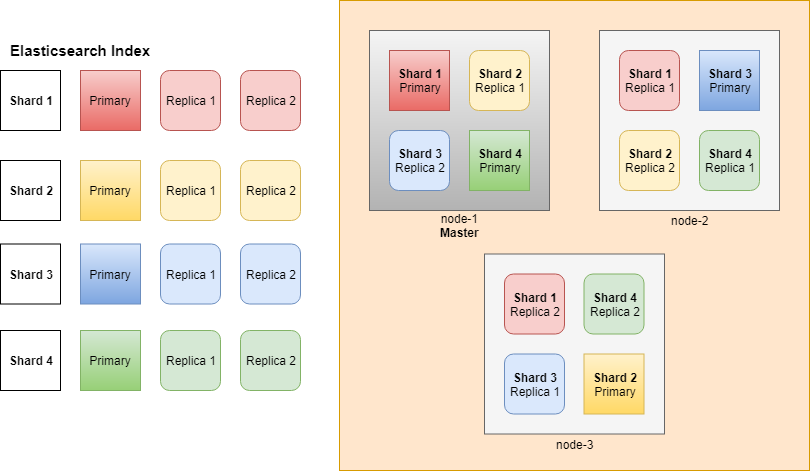
위 다이어그램은 3개의 엘라스틱서치 인스턴스 환경에서, 4개의 샤드를 2개의 복제본으로 구성했을 때의 구조이다.
엘라스틱서치는 클러스터 구조로 구성되어 있으며 샤드와 복제본의 수를 설정해두면 스스로 각 노드에 샤드를 분배하여 장애발생 시 데이터 손실을 최소화한다.
프라이머리 샤드가 손실되었을 경우에는 레플리카를 프라이머리로 승격시켜 데이터 손실을 방지한다.