
그래프형 데이터 모델
애플리케이션이 주로 일대다 관계(트리 구조 데이터)이거나 레코드 간 관계가 없다면 문서 모델이 적합하다.
하지만 데이터에서 다대다 관계가 매우 일반적이라면 어떻게 해야 할까? 관게형 모델은 단순한 다대다 관계를 다룰 수 있지만, 데이터 간 연결이 더 복잡해지면 그래프로 데이터를 모델링하기 시작하는 편이 더 자연스럽다.
그래프는 두 유형의 객체로 이뤄지며 이를 통해 많은 유형의 데이터를 그래프로 모델링할 수 있다.
- 정점(vertex)(노드, 엔티티)
- 간선(edge)(관계, 호(arc))
일반적인 예는 다음과 같다.
- 소셜 그래프
- 정점은 사람, 간선은 사람들이 알고 있음을 나타냄
- 웹 그래프
- 정점은 웹 페이지, 간선은 다른 페이지에 대한 링크
- 도로나 철도 네트워크
- 정점은 교차로, 간선은 도로나 철로
하지만 그래프는 정점이 모든 같은 유형인 형식, 동종 데이터에 국한되지 않는다. 그래프를 동종 데이터와 마찬가지 방식으로 사용하면 단일 데이터 저장소에 완전히 다른 유형의 객체를 일관성 있게 저장할 수 있는 강력한 방법을 제공한다.
- 페이스북
- 정점: 사람, 장소, 이벤트, 체크인, 사용자가 작성한 코멘드 등
- 간선:
- 어떤 사람이 서로 친구인지
- 어떤 위치에서 체크인이 발생했는지
- 누가 어떤 포스트에 코멘트를 했는지
- 누가 이벤트에 참여했는지 등
속성 그래프
그래프에서 데이터를 구조화하고 질의하는 몇 가지 다른(하지만 관련된) 방법이 있다.
속성 그래프 모델에서 각 정점은 다음과 같은 요소로 구성된다.
- 고유한 식별자
- 유출(outgoing) 간선 집합
- 유입(incoming) 간선 집합
- 속성 컬렉션(키-값 쌍)
각 간선은 다음과 같은 요소로 구성된다.
- 고유한 식별자
- 간선이 시작하는 정점(꼬리 정점)
- 간선이 끝나는 정점(머리 정점)
- 두 정점 간 관계 유형을 설명하는 레이블
- 속성 컬렉션(키-값 쌍)
아래와 같이 두 개의 관계형 테이블(하나는 정점, 하나는 간선)로 구성된 그래프 저장소를 생각해보면, 머리와 꼬리 정점은 각 간선마다 저장된다. 따라서 정점을 위한 유입 간선과 유출 간선의 집합이 필요하다면
edges 테이블에 head_vertex나 tail_vertex로 각각 질의할 수 있다.
| |
이 모델의 몇 가지 중요한 면은 다음과 같다.
- 정점은 다른 정점과 간선으로 연결된다.
- 특정 유형과 관련 여부를 제한하는 스키마는 없다.
- 정점이 주어지면 정점의 유입과 유출 간선을 효율적으로 찾을 수 있고 그래프를 순회할 수 있다.
- 일련의 정점을 따라 앞뒤 방향으로 순회한다.
- 이를 위해
tali_vertex와head_vertex컬럼에 대해 색인을 생성했다.
- 다른 유형의 관계에 서로 다른 레이블을 사용하면 단일 그래프에 다른 유형의 정보를 저장하면서도 데이터 모델을 깔끔하게 유지할 수 있다.
이러한 기능을 통해 그래프는 데이터 모델링을 위한 많은 유연성을 제공한다.
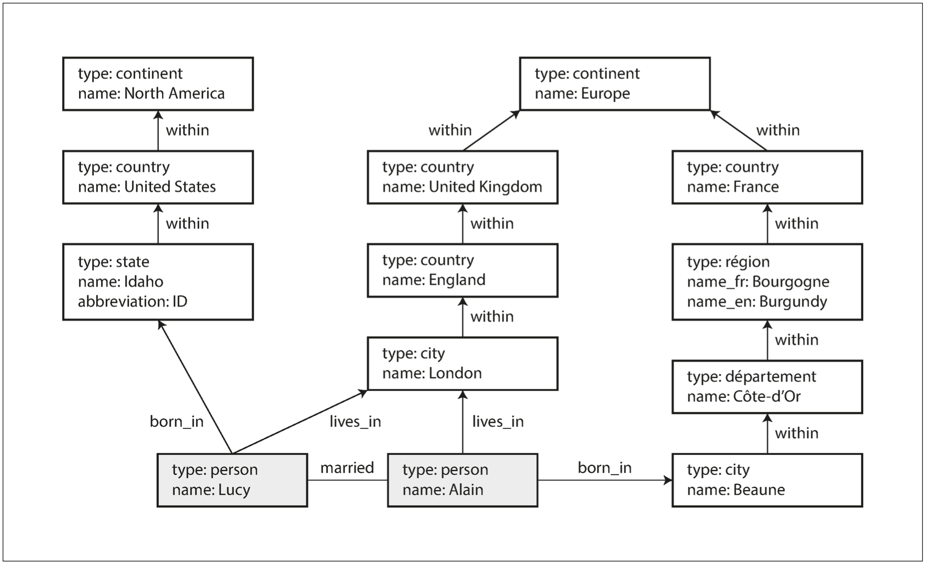
위 그림에서 전통적인 관계형 스키마에서 표현하기 어려운 사례 몇 가지를 살펴볼 수 있다.
- 국가마다 다른 지역 구조
- 프랑스에서는 주(departement)와 도(region)
- 미국에서는 군(country)과 주(state)
위 예시에서 루시와 알랭 또는 그 밖의 사람에 대한 다른 여러 사실을 포함시키기 위해 그래프를 확장해야한다면, 새로운 관심사를 정점으로 만들고 연결하기만 하면 된다.
그래프는 발전성이 좋아서 애플리케이션에 기능을 추가하는 경우 애플리케이션의 데이터 구조 변경을 수용하게끔 그래프를 쉽게 확장할 수 있다.
사이퍼 질의 언어
사이퍼(Cypher)는 속성 그래프를 위한 선언형 질의 언어로, Neo4j 그래프 데이터베이스용으로 만들어졌다.
사이퍼로 왼쪽 부분을 그래프 데이터베이스로 삽입하려면 아래와 같은 질의가 필요하다.
| |
각 정점에는 USA나 Idaho 같은 상징적인 이름이 지정돼있고, 질의의 다른 부분에서 이 이름을 사용해 정점간 간선을 화살표 표기를 사용해 만들 수 있다.
미국에서 유럽으로 이민 온 모든 사람들의 이름 찾기
더 정확하게 말하면 미국 내 위치의 BORN_IN 간선을 가진 정점과 유럽 내 위치의 LIVING_IN 간선을 갖는 모든 정점을 찾아서 이 정점들의 name 속성을 반호나하는 문제이다.
MATCH 문에서는 같은 화살표 표기를 이용해 그래프에서 패턴을 찾는다.
(person) -[:BORN_IN]-> ()는 BORN_IN 레이블을 가진 간선과 관련된 두 정점을 찾는다. 이 간선의 꼬리 정점은 person 변수에 묶여 있고 머리 정점은 명기하지 않는 채로
남아있게된다.
| |
person은 어떤 정점을 향하는BORN_IN유출 간선을 가지며, 이 정점에서name속성이 “United States"인Location유형의 정점에 도달할 때까지 일련의WITHIN유출 간선을 따라간다.- 같은
person의 정점은LIVES_IN유출 간선도 가지는데, 이 간선과WITHIN유출 간선을 따라가면 결국name속성이 “Europe"인Location유형의 정점에 도달하게된다. - 각
person정점마다name속성을 반환한다.
질의를 실행하는 데는 여러 가지 방법이 있다.
- 데이터베이스에서 모든 사람을 홅어보는 작업을 시작으로 사람들의 출생지와 거주지를 확인해 기준에 맞는 사람들만 반환
- 두 개의
Location정점에서 시작해 반대 방향으로 수행name속성에 색인이 있다면 미국과 유럽을 나타내는 두 개의 정점을 효율적으로 찾을 수 있음WITHIN유입 간선을 따라겨 미국과 유럽의 모든 위치 찾기를 진행- 위치를 나타내는 정점 중 하나에서
BORN_IN이나LIVE_IN유입 간선을 통해 발견된 사람을 구함
보통 선언형 질의 언어는 질의를 작성할 때 이처럼 수행에 대해 자세히 지정할 필요가 없다. 질의 최적화기가 가장 효율적이라고 예측한 전략을 자동으로 선택하므로 작성자는 나머지 애플리케이션만 작성하면 된다.
SQL의 그래프 질의
위에서 언급한 것 처럼 관계형 데이터베이스에서 그래프 데이터를 표현할 수 있음을 제안하였다.
그래프를 관계형 구조로 넣어도 SQL을 통해 질의할 수 있지만, 어렵다. 관계형 데이터베이스에서는 대개 질의에 필요한 조인을 미리 알고 있는데, 그래프 질의에서는 찾고자 하는 정점을 찾기 전에 가변적인 여러 간선을 순회해야하기 때문이다.
- 미리 조인 수를 고정할 수 없다.
예제에서 간선 순회는 사이퍼 질의의 () -[:WITHIN*0..]-> () 문에서 발생한다.
person의LIVES_IN간선은 위치 유형(거리, 도시, 지구, 군, 주 등)을 가리킨다.- 각각 “도시 -> 군 -> 주 -> 주 -> 국가” 순으로
WITHIN간선으로 이어진다.LIVES_IN간선은 찾고자 하는 위치 정점을 직접 가르킬 수 있으나 위치 계층 구조에서 제거된 일부 수준일 수도 있다.
사이퍼에서 :WITHIN*0..은 0회 이상 WITHIN 간선을 따라가라는 의미로 이를 간결하게 표현한다.
SQL:1999 이후 가변 순회 경로에 대한 질의 개념은 재귀 공통 테이블 식(recursive common table expression, WITH RECURSIVE)을 사용해서 표현할 수 있지만
사이퍼와 비교했을 때 문법이 어렵다.
| |
name속성이 “United States"인 정점을 찾아in_usa정점 집합의 첫 번째 엘리먼트로 만든다.in_usa집합의 모든 정점들의 모든within유입 간선을 따라가 같은 집합에 추가한다.- 모든
within간선을 방문할 때까지 수행한다.
- 모든
name속성이 “Europe"인 정점을 시작으로 동일하게 수행해in_europe집합을 만든다.- 미국에서 태어난 사람을 찾기 위해
in_usa집합의 각 정점에 대해born_in유입 간선을 따라간다. - 비슷하게 유럽에서 사는 사람을 찾기 위해
in_europe집합의 각 정점에 대해lives_in유입 간선을 따라간다. - 마지막으로 조인을 이용해 미국에서 태어난 사람 집합과 유럽에서 사는 사람 집합의 교집합을 구한다.
동일한 질의를, cypher는 4줄로 작성하고, SQL은 29줄로 작성해야 한다. 이는 다양한 데이터 모델이 서로 다른 사용 사례를 만족하기 위해 설계되었다는 사실을 반증한다.
따라서 애플리케이션에 적합한 데이터 모델 선택 작업은 중요하다.
트리플 저장소와 스파클
트리플 저장소 모델은 속성 그래프 모델과 거의 동등하다.
이 모델은 같은 생각을 다른 용어를 사용해 설명한다. 그럼에도 애플리케이션 구축에 유용한 도구일지도 모를 트리플 저장소를 위한 ㄷ양한 도구와 언어가 있기 때문에 논의할 만한 가치가 있다.
트리플 저장소에서는 모든 정보를 주어(subject), 서술어(predicate), 목적어(object) 처럼 매우 간단한 세 부분 구문(three-part statements) 형식으로 저장한다.
트리플의 주어는 그래프의 정점과 종등하며, 목적어는 두 가지중 하나이다.
- 문자열이나 숫자 같은 원시 데이터타입의 값
- 트리플의 서술어와 목적어는 주어 정점에서 속성의 키, 값과 동등하다.
- (루시, 나이, 33)은
{"age":33}속성을 가진 정점 lucy와 같다.
- 그래프의 다른 정점
- 서술어는 그래프의 간선이고 주어는 꼬리 정점이며 목적어는 머리 정점이다.
- (루시, 결혼하다, 알랭)에서 주어와 목적어인 루시와 알랭은 정점이고, 서술어 결혼하다는 두 정점을 잇는 간선의 레이블이다.
| |
위 예제는 그림의 일부를 보여주며 터틀(Turtle) 형식의 트리플로 작성되었다.(터틀은 Notation3(N3)의 부분 집합이다.)
그래프의 정점을 _:someName으로 작성했는데 이 파일 외부의 것을 의미하지 않는다, _:someName은 트리플이 같은 정점을 참조하는지 달리 알지 못하기 때문에 존재한다.
서술어가 간선을 나타내면 목적어는 _:usa :within _:usa 처럼 정점이 되고, 서술어가 속성이라면 목적어는 _:usa :name "United States" 처럼 문자열 리터럴이된다.
동일한 주어를 반복하는 작업은 단순 반복 작업으로, 세미콜론을 사용해 동일한 주어에 대해 여러 경우를 잘 표한할 수 있게되어 터틀 형식을 읽기 쉽게 만든다.
| |
시맨틱 웹
트리플 저장소에 관한 내용을 읽다보면 시맨틱 웹관련 기사들을 많이 접할 수 있지만, 트리플 저장소 데이터 모델은 시맨틱 웹과는 완전히 독립적이다.
하지만 많은 사람들이 이 둘이 매우 밀접한 관계가 있다고 생각하기때문에 간략화게 논의할 필요가 있다.
시맨틱 웹은 즉 웹 사이트는 이미 사람이 읽을 수 있는 텍스트와 그림으로 정보를 게시하고 있으니 컴퓨터가 읽게끔 기계가 판독 가능한 데이터로도 정보를 게시하는 건 어떨까?라는 개념이다.
자원 기술 프레임워크(Resource Description Framework, RDF) 는 서로 다른 웹 사이트가 일관된 형식으로 데이터를 게시하기 위한 방법을 제안한다.
RDF는 서로 다른 웹 사이트의 데이터가 일종의 전 인터넷 “만물 데이터베이스(database of everything)“인 데이터 웹(web of data) 에 자동으로 결함할 수 있게 한다.
시맨틱 웹은 2000년대 초반에 과대평가됐고 지금까지 현실에서 실현된 흔적이 없어 많은 사람이 부정적인 견해를 보였다.
- 어지러운 약어의 과잉과 지나치게 복잡한 표준 제안, 자만심으로 어려움을 겪었다.
하지만 이런 단점들이 있음에도 시맨틱 웹 프로젝트에서 유래한 좋은 작업이 많이 있으며, 시맨틱 웹에서 RDF 데이터를 게시하는 일어 관심이 없다고 하더라도 트리플은 애플리케이션의 훌륭한 내부 데이터 모델이 될 수 있다.
RDF 데이터 모델
터틀 언어는 RDF 데이터를 사람이 읽을 수 있는 형식으로 표현한다. XML 형식으로 쓰기도 하지만, XML 형식은 같은 내용을 훨씬 장황하게 만든다.
한눈에 쉽게 보기 위해서는 터틀/N3를 선호하며 아파치 제나 같은 도구는 필요한 경우 서로 다른 RDF 형식으로 자동 변환할 수 있다.
| |
RDF는 인터넷 전체의 데이터 교환을 위해 설계했기 때문에 약간 이상한 점이 있다.
첫 번째로 트리플의 주어, 서술어, 목적어는 주로 URI다.
서술어는 WITHIN이나 LIVES_IN이 아니라 <http://my-company.com/namespace#within>, <http://my-company.com/namespace#lives_in>
같은 URL일 수 있는데, 이러한 설계의 배경은 데이터를 다른 사람의 데이터와 결합하기 위함이다.
만약 within이나 lives_in 단어에 다른 의미를 붙이면 서술어는 <http://other.org/foo#within>, <http://other.org/foo#lives_in>이므로 충돌이
발생하지 않게된다.
두 번째로 URL은 반드시 실제 접속 가능한 주소일 필요는 없다는 점으로, RDF의 관점에서는 하나의 네임 스페이스를 의미할 뿐이다.
스파클 질의 언어
스파클(SPARQL)은 RDF 데이터 모델을 사용한 트리플 저장소 질의 언어이다.(SPARQL Protocol and RDF Query Language)
스파클을 사이퍼보다 먼저 만들었고 사이퍼의 패턴 매칭을 스파클에서 차용했기 때문에 매우 유사해보인다.
앞에서 살펴본 무국에서 유럽으로 이주한 사람을 찾는 질의는 사이퍼보다 스파클에서 더욱 간결해진다.
| |
구조는 매우 유사하며 다음 두 표현식은 동등하다.
- 스파클에서 변수는 물음표로 시작
| |
RDF는 속성과 간선을 구별하지 않고 서술어만 사용하기 때문에 속성 매칭을 위해 동일한 구문을 사용할 수 있다.
다음 표현식에 따르면 usa 변수는 문자열 값이 "United States"인 name 속성을 가진 모든 정점이어야 한다.
| |
스파클은 훌륭한 질의 언어로 시멘틱 웹이 아니더라도 애플리케이션이 내부적으로 사용하는 강력한 도구가 될 수 있다.
초석: 데이터로그
데이터로그(Datalog) 는 스파클이나 사이퍼보다 훨씬 오래된 언어로 1980년대 학계에서 광범위하게 연구되었다.
소프트웨어 엔지니어 사이에서는 잘 알려져 있지 않지만 그럼에도 중요한 이유는 이후 질의 언어의 기반이 되는 초석을 제공하기 때문이다.
데이터로그의 데이터 모델은 트리플 저장소 모델과 유사하지만 조금 더 일반화되었다.
(주어, 서술어, 목적어)로 트리플을 작성하는 대신서술어(주어, 목적어)로 작성한다.
지금까지 예시로 주어졌던 데이터를 데이터로그로 표현아면 아래와 같다.
| |
데이터를 위와 같이 정의했다면, 데이터로그를 이용해서 이전과 동일한 질의를 작성할 수 있다.
| |
사이퍼와 스파클은 SELECT로 바로 질의하는 반면 데이터로그는 단계를 나눠 한 번에 조금씩 질의로 나아간다.
먼저 새로운 서술어를 데이터베이스에 전달하는 규칙(rule) 을 정의한다.
- 이 예제에서는
within_recursive와migrated두 개를 새로 정의
서술어는 데이터베이스에 저장된 트리플이 아니며, 데이터나 다른 규칙으로 부터 파생되며, 규칙(rule)은 함수가 다른 함수를 호출하거나 재귀적으로 자신을 호출하는 것 처럼 다른 규칙을 참조할 수 있다.
- 이처럼 복잡한 질의를 작은 부분으로 나눠 차례차례 구성할 수 있다.
규칙에서 대문자로 시작하는 단어는 변수이고 서술어는 사이퍼와 스파클의 서술어와 대응된다.
name(Location, Name)은 변수Location = namerica,Name = 'North America'를 가진 트리플name(namerica, 'North America')에 대응
시스템이 :- 연산자의 오른편에 있는 모든 서술어의 대응을 찾으면 규칙이 적용된다. 규칙이 적용될 때 :-의 왼편이 데이터베이스에 추가된다.(변수는 대응된 값으로 대체)
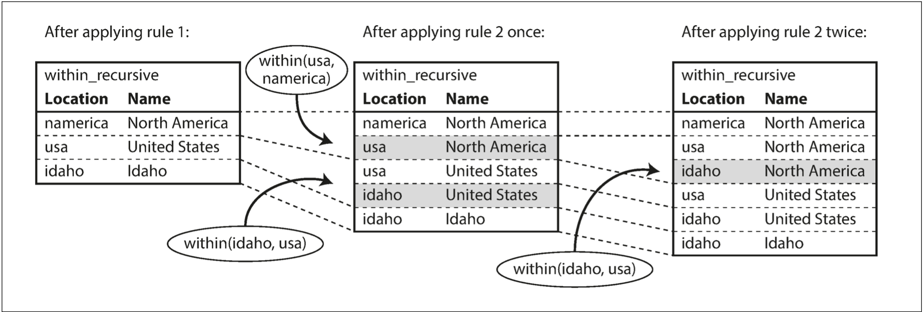
다음은 이 규칙을 적용할 수 있는 방법 중 하나다.
- 데이터베이스에
name(namerica, 'North America')가 존재하면 규칙 1을 적용하고, 규칙 1은within_recursive(namerica, 'North America')를 생성한다. - 데이터베이스에
within(usa, namerica)가 존재하고 이전 단계에서within_recursive(namerica, 'North America')를 생성했으면 규칙 2를 적용한다. 규칙 2는within_recursive(usa, 'North America')를 생성한다. - 데이터베이스에
within(idaho, usa)가 존재하고 이전 단계에서within_recursive(usa, 'North America')를 생성했으면 규칙 2를 적용한다. 규칙 2는within_recursive(idaho, 'North America')를 생성한다.
within_recursive 서술어는 규칙 1과 2를 반복 적용해 데이터베이스에 포함된 북아메리카(또는 다른 장소 이름)의 모든 위치를 찾을 수 있다.
이제 규칙 3으로 특정 LivingIn 장소에 살면서 특정 BornIn 장소에서 태어난 사람을 찾을 수 있다.
질의는 BornIn = 'United State'와 LivingIn = 'Europe'이고 변수 Who에 사람을 남기게 한 다음 데이터로그 시스템에 어떤 값이 변수 Who에 나타날 수 있는지 물어본 후 최종적으로 이전 사이퍼나 스파클 질의와 같은 답을 얻는다.
데이터로그 접근 방식은 이번 장에서 이전에 설명한 질의 언어와는 다른 사고가 필요하지만 다른 질의 규칙을 결합하거나 재사용할 수 있기 때문에 매우 강력한 접근 방식이다.
간단한 일회성 질의에 사용하기는 편리하지 않지만 데이터가 복잡하면 더 효과적으로 대체할 수 있다.
정리
데이터 모델은 광범위한 주제다. 이번 장에서는 다양한 종류의 모델을 간략하게 살펴봤다.
역사적으로 데이터를 하나의 큰 트리(계층 모델)로 표현하려고 노력했지만 다대다 관계를 표현하기에는 트리 구조가 적절하지 않았다. 이 문제를 해결하기 위해 관계형 모델이 고안되었으며, 최근 개발자들은 관계형 모델에도 적합하지 않은 애플리케이션이 있다는 사실을 발견했다.
새롬게 등장한 비관계형 데이터 저장소인 NoSQL은 다음과 같은 두 가지 주요 갈래가 있다.
- 문서 데이터베이스
- 데이터가 문서 자체에 포함돼 있으면서 하나의 문서와 다른 문서 간 관계가 거의 없는 사용 사례를 대상으로 함
- 그래프 데이터베이스
- 문서 데이터베이스와는 정 반대로 모든 것이 잠재적으로 관련이 있다는 사용 사례를 대상으로 함
세 가지 모델(문서, 관계형, 그래프) 모두 현재 널리 사용하고 있으며 각 모델은 각자의 영역에서 훌륭하다.
한 모델을 다른 모델로 흉내 낼 수 있지만 그 결과는 대부분 엉망이며, 이것이 단일 만능 솔루션이 아닌 각기 목적에 맞는 다양한 시스템을 보유해야 하는 이유이다.
문서 및 그래프 데이터베이스가 가진 공통점 중 하나는 일반적으로 저장할 데이터를 위한 스키마를 강제하지 않아 변화하는 요구사항에 맞춰 애플리케이션을 쉽게 변경할 수 있지만, 애플리케이션은 데이터가 특정 구조를 갖는다고 가정할 가능성이 높다.
- 이는 스키마가 명시적인지(쓰기에 강요) 암시적인지(읽기에 다뤄짐)의 문제일 뿐이다.
각 데이터 모델은 고유한 질의 언어나 프레임 워크를 제공한다.
- SQL, 맵리듀스, MongoDB의 집계 파이프라인, 사이퍼, 스파클, 데이터로그 등
- CSS, XSL/XPath: 데이터베이스 질의 언어는 아니지만 흥미로운 유사점이 있다.
아직 언급되지 않은 데이터 모델은 몇 가지는 아래와 같다.
- 게놈(Genome) 데이터베이스
- 대형 강입자 충돌기를 위한 하드웨어 비용이 통제되는 사용자 정의 솔루션
- 전문 검색(full-text)