
관계형 모델과 문서 모델
데이터 모델은 소프트웨어가 어떠헥 작성됐는지 뿐만 아니라 해결하려는 문제를 어떻게 생각해야 하는지에 대해 지대한 영향을 미친다.
대부분 애플리케이션은 하나의 데이터 모델을 다른 데이터 모델 위에 계층을 둬서 만든다.
각 계층의 핵심적인 문제는 다음 하위 계층 관점에서 데이터 모델을 표현하는 방법이다.
- 애플리케이션 개발자는 현실(사람, 조직, 상품, 행동, 자금 흐름, 센서)을 보고 객체나 데이터 구조, 그리고 이러한 데이터 구조를 다루는 API를 모델링한다.
- 이러한 구조는 보통 애플리케이션에 특화
- 데이터 구조를 저장할 때는 JSON이나 XML 문서, 관계형 데이터베이스 테이블이나 그래프 모델 같은 범용 데이터 모델로 표현한다.
- 데이터베이스 소프트웨어를 개발하는 엔지니어는 JSON/XML/관계형/그래프 데이터를 메모리나 디스크 또는 네트워크 상의 바이트 단위로 표현하는 방법을 결정한다.
- 이 표현은 다양한 방법으로 데이터를 질의, 탐색, 조작 처리할 수 있게 한다.
- 더 낮은 수준에서 하드웨어 엔지니어는 전류, 빛의 파동, 자기장 등의 관점에서 바이트를 표현하는 방법을 알아냈다.
복잡한 애플리케이션에서는 여러 API를 기반으로 만든 API처럼 중간 단계를 더 둘 수 있지만 기본 개념은 여전히 동일하다.
각 계층은 명확한 데이터 모델을 제공해 하위 계층의 복잡성을 숨겨(추상화), 다른 그룹의 사람들이 효율적으로 함께 일할 수 있게끔 한다.
다양한 유형의 데이터 모델이 존재하며, 각 데이터 모델은 사용 방법에 대한 가정을 나타낸다.
- 어떤 종류의 데이터모델의 사용법은 쉬우나 어떤 동작은 지원하지 않는다.
- 데이터 모델의 종류에 따라 어떤 연산은 빠르지만 다른 연산은 매우 느리게 작동한다.
- 어떤 데이터 변환은 자연스럽지만 달느 어떤 데이터 변환은 부자연스럽다.
하나의 데이터 모델만을 완전히 익히는 데도 많은 노력이 필요하며(관계형 데이터 모델링 관련된 학습 분량만해도 방대하다), 데이터 모델을 하나만 사용하면서도 내부 동작에 대한 걱정이 없더라도 소프트웨어 작성은 그 자체로 충분히 어렵다.
그러나 데이터 모델은 그 위에서 소프트웨어가 할 수 있는 일과 할 수 없는 일에 지대한 영향을 주므로 애플리케이션에 적합한 데이터 모델을 선택하는 작업은 상당히 중요하다.
오늘날 가장 잘 알려진 모델은 1970년 에드가 코드(Edgar Codd)가 제안한 관계형 모델을 기반으로 한 SQL이다.
- 데이터는 관계로 구성되고 각 관계는 순서 없는 튜플 모음이다.
관계형 데이터베이스의 근원은 1960년대와 1970년대에 메인프레임 컴퓨터에서 수행된 비즈니스 데이터 처리에 있다.
- 트랜잭션 처리, 일괄 처리 등
당시 다른 데이터베이스를 사용하는 개발자는 데이터베이스 내부 데이터 표현에 대해 고민해야 했지만, 관계형 모델로 인해 정리된 인터페이스 뒤로 구현 세부 사항을 숨길 수 있게 되었다.
이후 컴퓨터가 훨씬 더 강력해지고 네트워크화됨에 따라 다양한 목적으로 활용되기 시작하였고, 관계형 데이터베이스는 비즈니스 데이터 처리 뿐만이 아닌 폭넓은 다양한 사용 사례에도 보편화 되는 것으로 나타났다.
오늘날 대부분의 서비스는 여전히 관계형 데이터베이스를 통해 제공된다.
NoSQL의 탄생
2010년대에 들어서며 NoSQL이 빠르게 확산되었는데 다양한 이유가 있다.
- 대규모 데이터셋이나 매우 높은 쓰기 처리량 달성을 관계형 데이터베이스보다 쉽게 할 수 있는 뛰어난 확장성의 필요
- 상용 데이터베이스 제품보다 무료 오픈소스 소프트웨어에 대한 선호도 확산
- 관계형 모델에서 지원하지 않는 특수 질의 동작
- 관계형 스키마의 제한에 대한 불만과 더욱 동적이고 표현력이 풍부한 데이터 모델에 대한 바람
애플리케이션은 저마다 요구사항이 다르기 때문에, 사용 사례에 맞는 최적의 기술 선택은 동시에 요구되는 사용 사례에 맞는 최적의 선택과는 다를 수 있다.
이 때문에 관계형 데이터베이스가 폭넓은 다양함을 가진 비관계형 데이터스토어와 함께 사용될 것이다.(😲)
이런 개념을 종종 다중 저장소 지속성(polyglot persistence)이라고 부른다.
객체 관계형 불일치
오늘날의 대부분의 애플리케이션은 객체지향 프로그래밍 언어로 개발되는데, 이는 SQL 데이터 모델과 객체 모델 사이에 불일치가 발생한다.
- 데이터를 관계형 테이블에 저장하려면 애플리케이션 코드와 데이터베이스 모델 객체 사이에 거추장스러운 전환 계층이 필요함
- 이런 모델 사이의 분리를 임피던스 불일치(impedance mismatch)라고 부른다.
액티브레코드(Active Record)나 하이버네이트(Hibernate)와 같은 ORM 프레임워크는 전환 계층에 필요한 상용구 코드(boilerplate code)의 양을 줄이지만 두 모델 간의 차이를 완벽히 숨길 수 없다.
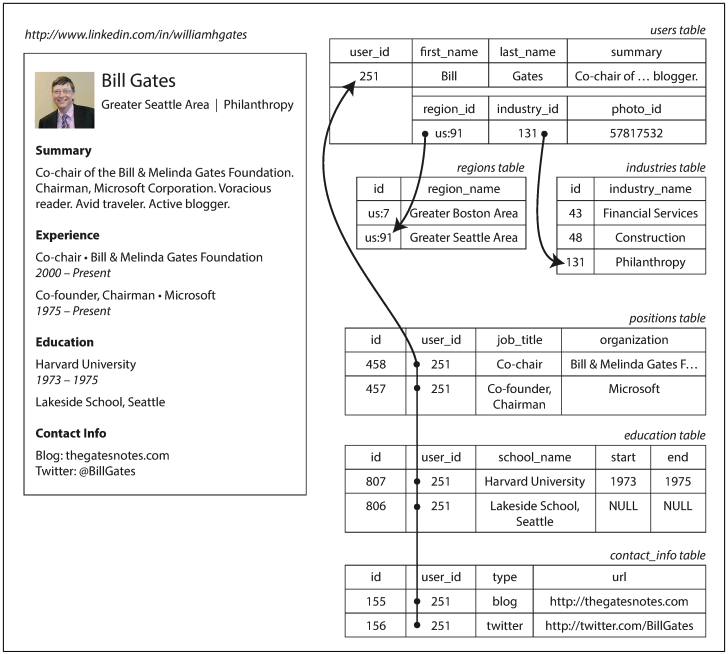
프로필 전체는 고유 식별자인 user_id로 식별가능하고, first_name, last_name 같은 필드는 사용자마다 하나만 있으므로 users 테이블 컬럼으로 모델링 가능하다.
하지만 경력에 넣을 직업이 하나 이상이며 학력 기간과 연락처 정보도 다양하기 때문에, 사용자와 이들 사이의 관계는 일대다 관계(one-to-many)이며 이는 다양한 방법으로 표현할 수 있다.
- 전통적인 SQL 모델의 일반적인 정구화 표현은 직위, 학력, 연락처 정보를 개별 테이블에 넣고 외래 키로
users테이블을 참조 - 구조화된 데이터타입으로 저장(XML, JSON 등)
- SQL 표준의 마지막 버번에서 구조화된 데이터타입에 대한 지원이 추가됨에 따라, 한 로우에 다중 값을 저장하고 질의와 색인이 가능해짐
- 직업, 학력, 연략처 정보를 JSON이나 XML 문서로 부호화해 데이터베이스의 텍스트 컬럼에 저장 후, 애플리케이션이 구조와 내용을 해석
- 일반적으로 부호화된 컬럼의 값을 질의하는 데 데이터베이스를 사용할 수 없음
이력서와 같은 데이터 구조는 모든 내용을 갖추고 있는 문서라서 JSON 표현에 매우 적합하다.
| |
일부 개발자는 JSON 모델이 애플리케이션 코드와 저장 계층 간 임피던스 불일치를 줄인다고 생각한다.
- 물론 데이터 부화화 형식으로서 JSON의 문제도 있음(4장)
JSON 표현은 다중 테이블 스키마보다 더 나은 지역성(locality)을 갖는다.
- 관계형 예제에서 프로필을 가져오려면 다중 질의를 수행하거나
users테이블과 그 하위 테이블 간에 난잡한 다중 조인이 필요함
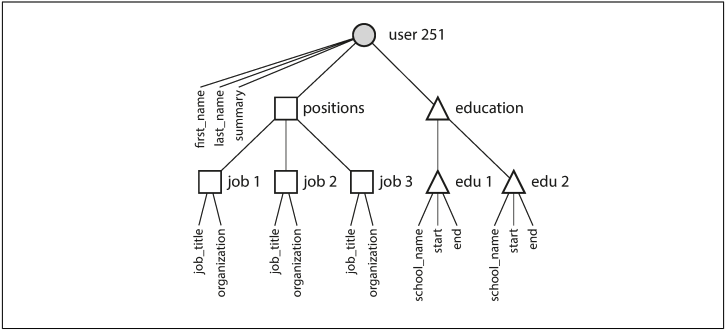
사용자 프로필에서 사용자에서 직위, 학력 기록, 연락처 정보로 대응되는 일대다 관계는 의미상 데이터 트리 구조와 같다.
- 이러한 트리 구조는 JSON 표현에서 명시적으로 드러나게된다.
다대일과 다대다 관계
이력서 예시에서 region_id와 industry_id는 평문이 아닌 외래 키인데, 지리적 지역과 업계 표준 목록으로 드롭다운 리스트나 자동 완성 기능을 만들어 사용자가 선택하게 하는 데는 다음과 같은 장점이 있다.
- 프로필 간 일관된 스타일 철자
- 모호함 회피(이름이 같은 여러 도시 등)
- 갱신의 편의성
- 이름이 한 곳에만 저장되므로 이름을 변경해야 하는 경우 전반적인 갱신이 쉬움
- 현지화 지원
- 글로벌 서비스의 경우 표준 목록을 현지화하는데 용이함
- 더 나은 검색
- 검색할 특정 항목이 특정 지역 목록에 포함된다는 것을 부호화하여 더 정확한 검색 결과를 얻을 수 있음
ID나 텍스트 문자열의 저장 여부는 중복의 문제로 텍스트로 저장하게되면 같은 의미의 데이터가 중복된다.
비정규화는 데이터 중복을 일부로 발생시키는 방법인데 이후 다룸
중복된 데이터를 정규화하려면 다대일 관계가 필요한데 이는 문서 모델에 적합하지 않다.
관계형 데이터베이스에서는 조인이 쉬어 ID로 다른 테이블의 로우를 참조하는 방식이 일반적이지만, 문서 데이터베이스에서는 일대다 트리 구조를 위해 조인이 필요하지 않지만 조인에 댛나 지원이 보통 약하다.
데이터베이스가 조인을 지원하지 않으면 데이터베이스에 대한 다중 질의를 만들어 애플리케이션 코드에서 조인을 흉내 내야 한다.
더욱이 애플리케이션의 초기 버전이 조인 없는 문서 모델에 적합하더라도 애플리케이션에 기능을 추가하면서 데이터는 점차 상호 연결되는 경향이 있다.
- 예시에서는 직장, 학교, 추천서 등
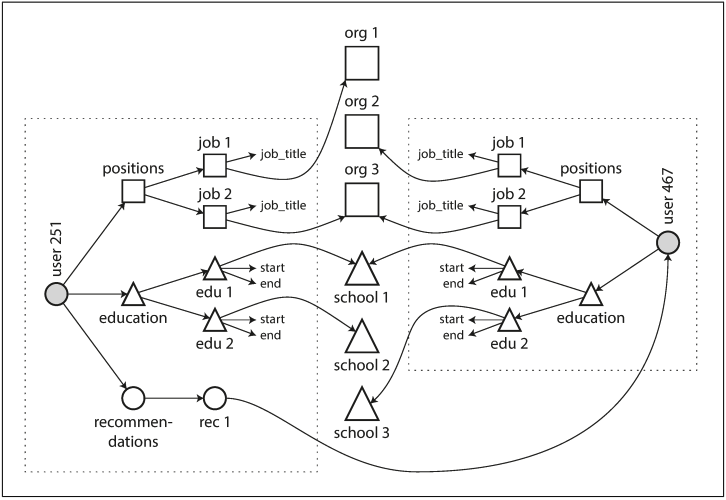
문서 데이터베이스는 역사를 반복하고 있나?
문서 데이터베이스와 NoSQL은 데이터베이스에서 다대다 관계를 표현하는 제일 좋은 방법에 대한 논쟁을 다시 열었다.
1970년대 많이 사용된 데이터베이스로 IBM의 정보 관리 시스템(Information Management System, IMS)은 계층 모델이라 부르는 간단한 데이터 모델을 사용했는데, JSON 모델과 매우 유사하다.
이때 관계형 모델에 대한 한계를 극복하기 위해 대표적으로 관계형 모델(SQL로 세상을 지배중)과 네트워크 모델이 제안되었는데, 해결하려는 문제가 지금 풀려는 문제와 매우 유사하다.
네트워크 모델
네트워크 모델은 코다실(Conference for Data Systems Languages, CODASYL)이 제안한 모델로 코다실 모델이라고도 부른다.
코다실 모델은 계층 모델을 일반화한다.
- 계층 모델의 트리 구조에서 모든 레코드는 정확하게 하나의 부모가 있지만, 네트워크 모델에서는 레코드는 다중 부모가 있을 수 있다.
- 네트워크 모델에서 레코드 간 연결은 왜래 키 보다는 프로그래밍 언어의 포인터와 더 비슷하다.
레코드에 접근하는 유일한 방법은 최상위 레코드(root record)에서 시작하는 경로를 따라가는 것이다.(“접근 경로"라고 함)
- 다대다 관계는 다양한 다른 경로가 같은 레코드로 이어질 수 있으므로, 네트워크 모델을 사용하는 프로그래머는 경로의 맨 앞에서 이런 다양한 접근 경로를 계속 추적해야 한다.
코다실에서 질의는 레코드 목록을 반복해 접근 경로를 따라 데이터베이스의 끝에서 끝까지 커서를 움직여 수행되며, 레코드가 다중 부모를 가진다면 애플리케이션 코드는 다양한 관계를 모두 추적해야한다.
- 수동 접근 경로 선택은 매우 제한된 하드웨어 성능을 가장 효율적으로 사용할 수 있었지만 데이터베이스 질의와 갱신을 위한 코드가 복잡하고 유연하지 못했다.
계층 모델과 네트워크 모델 모두, 원하는 데이터에 대한 결오가 없다면 어려운 상황에 놓인다.
- 접근 경로를 변경할 수 있지만 아주 많은 수작업 데이터베이스 질의 코드를 살펴야한다.
- 새로운 접근 경로를 다루기 위해 재작성 해야한다.
애플리케이션의 데이터 모델을 바꾸는 작업은 매우 어려운 일이었다.
관계형 모델
관계형 모델이 하는 일은 알려진 모든 데이터를 배치하는 것이다.
- 관계(테이블)는 단순히 튜플(로우)의 컬렉션이 전부이다.
- 복잡한 중첩 구조와 데이터를 보고 싶을 때 따라가야 할 복잡한 접근 경로가 없다.
임의 조건과 일치하는 테이블의 일부 또는 모든 로우를 선택해서 읽을 수 있고 일부 칼럼을 키로 지정해 칼럼과 일치하는 특정 로우를 읽을 수 있다.
다른 테이블과의 외래 키 관계에 대해 신경 쓰지 않고 임의 테이블에 새 로우를 삽입할 수 있다.
관계형 데이터베이스에서 질의 최적화기(query optimizer)는 네트워크 모델의 접근 경로와 같은 실행 계획을 선택한다.
따라서 애플리케이션 개발자가 접근 경로를 따로 생각할 필요는 없으며, 새로운 방식으로 데이터에 질의하고 싶다면 새로운 색인을 선언하면 잘의는 자동으로 가장 적합한 색인을 사용하게 된다.
- 관계형 모델은 애플리케이션에 새로운 기능을 추가하는 작업이 훨씬 쉽다.
문서 데이터베이스와의 비교
문서 데이터베이스는 별도 테이블이 아닌 상위 레코드 내에 중첩된 레코드를 저장한다.
하지만 다대일과 다대다 관계를 표현할 때 관계형 데이터베이스와 문서 데이터베이스는 근본적으로 다르지 않다.
- 둘 다 관련 항목은 고유한 식별자로 참조
- 관계형 모델에서는 외래 키, 문서 모델에서는 문서 참조(document reference)
이 식별자는 조인이나 후속 질의를 사용해 읽기 시점을 확인한다.
관계형 데이터베이스와 오늘날의 문서 데이터베이스
관계형 데이터베이스와 문서 데이터베이스를 비교할 때 많은 부분을 고려해야하지만 데이터 모델의 차이점에만 집중한다.
문서 데이터 모델을 선호하는 주요 이유는 스키마 유연성, 지역성에 기인한 더 나은 성능 때문이고 일부 애플리케이션의 경우 애플리케이션에서 사용하는 데이터 구조와 더 까깝기 때문이다.
관계형 모델은 조인, 다대일, 다대다 관계를 더 잘 지원함으로써 문서 데이터 모델에 대항한다.
어떤 데이터 모델이 애플리케이션 코드를 더 간단하게 할까?
애플리케이션에서 데이터가 문서와 비슷한 구조라면 문서 모델을 사용하는 것이 좋다.
- 문서와 비슷한 구조를 여러 테이블로 나누어 찢는(shredding) 관계형 기법은 다루기 힘든 스키마와 불필요하게 복잡한 애플리케이션 코드를 발생시킨다.
문서 모델은 문서 내 중첩 항목을 바로 참조할 수는 없다는 제한으로 인해 “사용자 251의 직위 목록의 두 번째 항목"과 같이 표현해야하지만, 문서가 너무 깊게 중첩되지 않으면 일반적으로 문제되진 않는다.
문서 데이터베이스의 미흡한 조인 지원은 애플리케이션에 따라 문제일 수 일 수 있지만 아닐수도 있다.
- ex) 어떤 시점에 발생한 이벤트를 기록하는 문서 데이터베이스를 사용하는 분석 애플리케이션
하지만 애플리케이션에서 다대다 관계를 사용한다면 문서 모델은 매력이 떨어진다.
- 비정규화로 조인의 필요성 줄이기가 가능하지만 애플리케이션 코드에서 비정규화된 데이터의 일관성을 유지하기 위한 추가 작업 필요
- 조인은 애플리케이션 코드에서 데이터베이스에 다중 요청을 만들어 흉내낼 수 있지만 복잡도가 높고, 조인보다 느림 이러한 경우 문서 모델을 사용하는 것이 훨씬 더 복잡한 애플리케이션 코드와 나쁜 성능으로 이어질 수 있다.
일반적으로 어떤 데이터 모델이 애플리케이션 코드를 더 간단하게 만드는지는 데이터 항목 간에 존재하는 관계 유형에 따라 다르다.
- 상호 연결이 많은 데이터의 경우
- 문서 모델: 곤란
- 관계형 모델: 무난
- 그래프 모델: 매우 자연스러움
문서 모델에서의 스키마 유연성
대부분의 문서 데이터베이스는 스키마를 강요하지 않는데, 이는 임의의 키와 값을 문서에 추가할 수 있고 읽을 때 클라이언트는 문서에 포함된 필드의 존재 여부를 보장하지 않는다는 의미이다.
문서 데이터베이스는 종종 스키마리스(schema-less)라고 부르는데, 오해의 소지가 있다. 보통은 읽는 코드는 어떤 구조를 가정하므로, 암묵적인 스키마가 있지만 강요하지 않는다는 뜻이 더 정확하다.
- 쓰기 스키마(schema-on-write)
- 관계형 데이터베이스의 전통적인 접근 방식
- 스키마는 명시적이고 데이터베이스는 쓰여진 모든 데이터가 스키마를 따르고 있음을 보장
- 읽기 스키마(schema-on-read)
- 데이터 구조는 암묵적이고 데이터를 읽을 때만 해석
데이터베이스에서 스키마 강제는 논쟁의 여지가 있는 주제이며 일반적으로 옳고 그른 정답은 없다.
접근 방식 간 차이는 애플리케이션이 데이터 타입을 변경하고자 할 때 특히 뚜렷이 나타나는데, 문서 데이터베이스에서는 새로운 필드를 가진 새로운 문서를 작성하기 시작하고 애플리케이션에서는 예전 문서를 읽은 경우를 처리하는 코드만 있으면 된다.
| |
데이터베이스 스키마에서는 보통 마이그레이션(migration)을 수행한다.
| |
스키마 변경은 느리고 중단시간을 요구하기 때문에 평판이 나쁘지만, 대부분의 관계형 데이터베이스 시스템에서 엄청 느리지는 않다.
- MySQL은 예외적으로
ALTER TABLE시 전체 테이블을 복사하기 때문에 큰 테이블을 변경할 때 수 분에서 수 시간까지 중단 시간이 발생할 수 있다.
큰 테이블에 UPDATE문을 실행하면 모든 로우가 재작성될 수 있기 때문에 어떤 데이터베이스는 오래 걸릴수 있다.
- 애플리케이션은 입력될 항목이 기본값인 널로 설정되게 남겨두고 문서 데이터베이스처럼 읽는 시점에 채울 수도 있다.
읽기 스키마 접근 방식은 컬렉션 안의 항목이 어떤 이유로 모두 동일한 구조가 아닐 때(데이터가 여러 다른 유형으로 구성돼 있을 때) 유용하다.
- 다른 여러 유형의 오브젝트가 있고 각 유형의 오브젝트별로 자체 테이블에 넣는 방법은 실용적이지 않다.
- 사용자가 제어할 수 없고 언제나 변경 가능한 외부 시스템에 의해 데이터 구조가 결정된다.
하지만 모든 레코드가 동일한 구조라서 예상 가능하다면 스키마가 문서화와 구조를 강제하기 위한 유용한 메커니즘이다.
질의를 위한 지역성
문서는 보통 JSON, XML로 부호화된 단일 연속 문자열이나(MongoDB의 BSON) JSON 또는 XML의 이진 변형으로 저장된다.
애플리케이션이 자주 전체 문서에 접근해야 할 때 저장소 지역성(storage locality)을 활용하면 성능 이점이 있다.
- 처음 봤던 이력서 예시처럼 데이터가 다중 테이블로 나눠졌으면 전체를 검색하기 위해 다중 색인 검색이 필요하므로 더 많은 디스크 탐색이 필요하다.
지역성의 이점은 한 번에 해당 문서의 많은 부분을 필요로 하는 경우에만 적용된다.
- 문서의 작은 부분에만 접근해도 전체 문서를 적재해야 하기에 큰 문서에서는 낭비일 수 있다.
- 문서를 갱신할 때도 보통 전체 문서를 재작성 해야한다.
- 부호화된 문서의 크기를 바꾸지 않는 수정은 쉽게 수행할 수 있다.
이런 이유로 일반적으로 문서를 아주 작게 유지하면서 문서의 크기가 증가하는 쓰기를 피하라고 권장한다.
- 이 성능 제한 때문에 문서 데이터베이스가 유용한 상황이 많이 줄어든다.
지역성을 위해 관련 데이터를 함께 그룹화하는 개념이 문서 모델에만 국한되지는 않는다는 점이 중요하다.
- 구글의 스패너(Spanner) 데이터베이스는 부모 테이블 내에 테이블의 로우를 교차 배치되게끔 선언하는 스키마를 허용하여 관계형 데이터 모델에서 지역성 특성을 동일하게 제공
- 오라클은 다중 테이블 색인 클러스터 테이블(multi-table index cluster table)을 사용해 관계형 데이터베이스에서 지역성을 제공
- 빅테이블(Bigtable) 데이터 모델의 컬럼 패밀리(column family)개념(카산드라, HBase)이 지역성 관리와 유사항 목적이 있음
문서 데이터베이스와 관계형 데이터베이스의 통합
대부분 관계형 데이터베이스 시스템은 2000년대 중반 이후로 XML을 지원한다.
- XML 문서의 저역적 수정 및 문서 내부 색인과 질의 기능 포함
그래서 문서 데이터베이스를 사용할 때와 매우 비슷한 데이터 모델을 애플리케이션이 사용할 수 있다.
PostgreSQL 9.3, MySQL 5.7, DB2 10.5 부터는 JSON 문서에 대해 비슷한 수준의 지원 기능을 제공한다.
- 웹 API용 JSON의 인기를 고려할 때, 그 밖의 관계형 데이터베이스도 선례를 쫒아 JSON 지원 기능을 추가할 가능성이 높아보임
문서 데이터베이스 쪽에서 본다면 리싱키DB는 질의 언어에서 관계형 조인을 지원하고 MongoDB 드라이버는 자동으로 데이터베이스 참조를 확인한다.
- 실제로는 클라이언트 측 조인을 수행
- 네트워크 왕복이 추가로 필요하고 최적화가 덜 되기 때문에 데이터베이스에서 수행되는 조인보다 느릴 수 있음
관계형 데이터베이스와 문서 데이터베이스는 시간이 지남에 따라 점점 더 비슷해지고 있다.
만약 데이터베이스가 데이터를 문서처럼 다룰 수 있고 관계형 질의를 수행할 수 있다면 애플리케이션은 필요에 따라 가장 적합한 기능을 조합해 사용하면 된다.
관계형과 문서형의 혼합 모델은 미래 데이터베이스들이 가야 할 올바른 길이다.🫨