
스터디를 위해 Real MySQL 8.0를 주제로 학습을 진행중 11.4.7.3 OUTER JOIN의 성능과 주의사항 부분에서 "OUTER JOIN을 사용할 때 드리븐 테이블에 WHERE 조건 적용 시 INNER JOIN으로 변경되어 실행되니 주의해야 한다." 라는 내용과 예시가 있었는데, 해당 부분이 이해가 잘 안되었습니다.
관련 자료를 찾아보았으나, 실행 계획에서 OUTER JOIN이 INNER JOIN으로 변경되는 이유를 설명한 자료는 못 찾았고, 확인한 모든 글에서 WHERE, ON절 조건을 처리하는 순서가 또는 범위가 다르다. 라는 간략한 설명만 하고 있어 더 정확한 내용들을 알려드릴 수 있을까 싶어 제가 이해한 내용을 기록합니다.
책의 예시 쿼리와 Real MySQL 8.0 학습 자료를 바탕으로 확인해보겠습니다.
테이블 구조
예시로 사용되는 테이블의 구조는 아래와 같습니다.
erDiagram
EMPLOYEES ||--o{ DEPT_MANAGER: ""
EMPLOYEES {
emp_no int pk
birth_date date
first_name varchar
last_name varchar
gender enum
hire_date date
}
DEPARTMENTS ||--o{ DEPT_MANAGER: ""
DEPARTMENTS {
dept_no char pk
dept_name varchar
emp_count int
}
DEPT_MANAGER {
dept_no char pk, fk
emp_no int pk, fk
from_date date
to_date date
}
조인 처리 과정
조인 작업은 드라이빙 테이블을 스캔하고, 스캔한 드라이빙 테이블 레코드의 조인 컬럼으로 드리븐 테이블의 레코드에 대해 탐색 작업을 수행하게 됩니다.
인덱스는 이미 정렬된 값을 가지기 때문에 빠른 속도를 보장하지만, 인덱스를 활용할 수 있는 경우라고 하더라도 여러 레코드를 가져오는 상황에서는 인덱스의 특정 범위를 가져오는 인덱스 스캔 작업 보다, 인덱스 값을 하나씩 비교해서 반복적으로 가져오는 탐색 작업이 상대적으로 부하가 높습니다.
이러한 이유로 옵티마이저는 테이블의 인덱스 사용 가능 여부나 테이블 레코드 개수 같은 통계 정보를 활용하여 더 빠르게 처리될 수 있는 테이블을 드리븐 테이블로 선택하는 방식으로 최적화를 수행합니다.
이너 조인과 아우터 조인의 차이
옵티마이저에서 이너 조인은 옵티마이저에 의해 드라이빙, 드리븐 테이블이 변경될 수 있는 반면 아우터 조인(LEFT JOIN, RIGHT JOIN)은 대상 테이블을 기준으로 조회될 레코드들이 결정되므로 테이블의 조인 순서를 변경할 수 없으므로(이미 결정된 순서이므로) 테이블 조인 순서에 의한 최적화는 발생하지 않게 됩니다.
즉, 이너 조인은 여러 상황을 고려하여 더 효율적인 테이블을 드리븐 테이블로 결정하지만, 아우터 조인은 대상 테이블을 기준으로 레코드를 선택하기 때문에 드라이빙 테이블이 결정되므로 테이블 조인 순서에 의한 최적화를 진행할 수 없습니다.
쿼리 분석
아우터 조인을 사용하는 쿼리에서 드리븐 테이블에 대한 조건을 WHERE 절에 명시하면 INNER JOIN으로 변경되어 처리된다고 하는데, EXPLAIN ANALYZE 명령으로 예시 쿼리가 어떤식으로 처리되는지 살펴보겠습니다.
LEFT JOIN + WHERE 조건
| |
WHERE 조건으로 처리한 쿼리가 Nested loop inner join으로 실행되었습니다. dept_manager 테이블을 드라이빙 테이블로 선택하였고, mgr.emp_no is not null 조건을 통해 필터링한 후, dept_no='d001' 조건을 통해 인덱스 스캔을 수행하였습니다.
그리고 employees 테이블에 대해 조인 컬럼인 emp_no=mgr.emp_no 이용해 인덱스 탐색을 수행하여 조인을 완료하였습니다.
dept_manager 테이블에 대한 mgr.emp_no is not null 필터 처리는 실행 계획 변경으로 발생할 수 있는 잘못된 데이터를 방지하는 차원에서 추가시키는 것이 아닌가 추측해봅니다.
(참고로 드리븐 테이블의 모든 컬럼의 조건에서 같은 처리가 발생합니다.)
INNER JOIN
책에서는 쿼리를 INNER JOIN으로 변경하여 실행한다고 언급했는데, 실제로 그럴까요? INNER JOIN으로 변경하여 실행 계획을 확인해보겠습니다.
| |
거의 같은 방식으로 처리되지만, INNER JOIN으로 실행한 쿼리는 dept_manager 테이블을 mgr.emp_no is not null 조건으로 필터링하는 처리가 없다는 점이 다릅니다.
그래서 이유는?
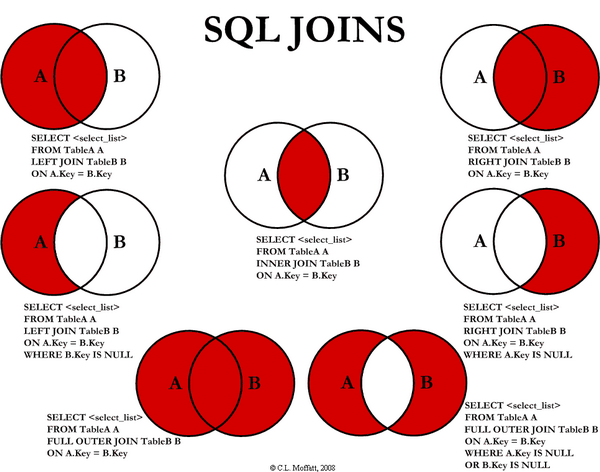
그림에서 보이듯 안티 조인이 아닌 아우터 조인(LEFT JOIN,OUTER JOIN)은 드라이빙 테이블의 레코드만 취하는 처리를 수행합니다. 따라서, 드라이빙 테이블의 조인되는 드리븐 테이블의 레코드가 존재하지 않을 경우 알 수 없다는 의미의 NULL을 채워 반환하게 됩니다.
아우터 조인의 WHERE 절에서 드리븐 테이블의 컬럼을 조건으로 사용한다는 것을 “아우터 조인된 결과에서 특정 조건으로 필터링 처리를 한다” 라는 의미로 많이 해석되는 것 같은데 이는 사실 완벽하게 일치하는 표현은 아닙니다.
결과적으로 조인 결과의 드리븐 테이블 컬럼에 대해 IS NULL을 제외한 모든 조건이 존재한다는 자체가 아우터 조인으로 만들어지는 조인 결과물의 해당 컬럼 값이 조인 결과가 있어야 한다는 것을 가정하고, 이는 드라이빙 테이블과 드리븐 테이블의 교집합을 의미하는 INNER JOIN 결과에 조건을 처리하는 것과 같은 결과를 만들게 됩니다.
옵티마이저가 아우터 조인을 INNER JOIN으로 변경하는 것은 아우터 조인으로 처리되어 드라이빙 테이블을 모두 읽고 교집합이 아닌 드리븐 테이블 영역에 대해서 NULL을 채워주는 처리 후 WHERE 조건을 이용한 필터링으로 처리하는 방식보다 효율적이고, 조인 테이블 순서 변경에 의한 최적화도 가능하므로 합리적으로 보입니다.
반대로 해당 컬럼이 NULL임을 확인해야하는 안티 조인은 아우터 조인 처리가 필요하므로 이너 조인으로 변경이 발생하지 않습니다.
정리
- 아우터 조인의 목적은 드라이빙 테이블의 레코드를 조회하되, 드리븐 테이블 대상이 드라이빙 테이블에 없다면 NULL을 채우기 위함입니다.
- 예시 쿼리에서
ON을 사용하여 아우터 조인으로 처리한 경우- 직원들을 보는데 특정 부서를 제외한 관리자 여부까지 확인하고 싶어(NULL이 아니면 관리자 의미)
- 예시 쿼리에서
- 아우터 조인의 드리븐 테이블 영역 컬럼에
IS NULL을 제외한 모든WHERE조건은 사실 조건에 해당하는 컬럼이 NULL이 아님을 의미합니다. - 이는 이너 조인으로 처리되어도 동일한 결과를 만들고, 더 효율적 처리할 여지가 있기 때문에 옵티마이저가 아우터 조인을 이너 조인으로 변경합니다.
- 아우터 조인이 이너 조인으로 변경되게 되면 오작동을 예방하기 위한 처리로 성능에 손해가 있을 수 있고(추측), 잘못된 쿼리 해석 예방을 위해 드리븐 테이블의
WHERHE조건을 사용하는OUTER JOIN쿼리는 모두INNER JOIN로 사용해야 합니다.