안녕하세요😁 오늘은 제가 생각하는 ORM(Object Relational Mapping)을 사용하는 이유에 대한 개인적인 생각을 써보려고 합니다.
저는 현재 부스트캠프 웹 풀스택 9기 멤버십 과정에 참여중인데, 피어 세션이라던가 스터디 그룹에서 다른 분들과 ORM에 대한 이야기를 할 일이 많았어요
이야기 나눴던 분들이 말하는 ORM은 아래와 같은 내용이 대부분이었습니다.
- ORM은 쿼리 빌더처럼 직접 SQL을 사용하지 않고도 쿼리를 작성해주는 도구이다.
- RDB 테이블을 객체 지향적으로 사용할 수 있게 만들어주는 도구이다.
- 일관된 구조를 활용하기 때문에 유지보수가 편리해진다.
위 처럼 제가 이야기나눴던 분들은 대부분 편의성에 초점을 맞추시는 것 같았어요
조금 깔끔하게 정리해보면 ORM은 RDB 테이블에 저장된 데이터 조회하여 주요 관심사 단위인 엔티티 객체로 만들기 위해 사용됩니다.
다른 분들이 말씀해주셨던 내용 모두 맞는 말 입니다. 그런데 위에서 언급했던 장점들이 ORM을 사용하는 본질적인 이유일까요?
이는 사실 ORM을 사용했을 때 부가적으로 따라오는 장점이며 저는 조금 더 근본적인 이유가 바로 아키텍처에 있다고 생각합니다.
RDBMS와 아키텍처
먼저 관계형 데이터베이스가 소프트웨어 아키텍처에 어떤 영향을 주는지 살펴보면 좋을 것 같아요
아직까지도 관계형 데이터베이스는 웹서비스에서 가장 많이 활용되는 기술입니다.


관계형 데이터베이스는 데이터를 표(table) 형식으로 구성하여 저장하고, 연관된 데이터는 각 테이블의 관계를 통해 관리할 수 있죠
책 클린 아키텍처에서는 소프트웨어 아키텍처는 세부사항에 의존하면 유연하지 못한 아키텍처가 된다는 것을 항상 강조하고 있습니다.
데이터베이스는 세부사항이다 단락을 보면 아래와 같은 내용들이 언급됩니다.
아키텍처 관점에서 볼 때 데이터베이스는 엔티티가 아니다.
데이터 모델과는 달리 아키텍처 관점에서는 데이터베이스는 세부사항이라 아키텍처의 구성 요소 수준으로 끌어올릴 수 없다.
데이터베이스는 소프트웨어일 뿐이며, 데이터에 접근할 방법을 제공하는 유틸리티다.
그리고 아키텍처 관점의 컴포넌트에 대해 중요하게 언급하는데요, 아키텍처 관점의 컴포넌트를 설명한다면 아래와 같습니다.
컴포넌트는 시스템의 구성 요소로 배포할 수 있는 가장 작은 단위다.
<중략…>
컴포넌트가 마지막에 어떤 형태로 배포되든, 잘 설계된 컴포넌트라면 반드시 독립적으로 배포 가능한, 따라서 독립적으로 개발 가능한 능력을 갖춰야한다.
- 이러한 이유 때문에 Spring 같은 경우는 데이터 저장소에 대한 일관된 처리 추상화한
Spring Data를 제공합니다.
이제 위에서 언급한 클린 아키텍처에서 언급했던 컴포넌트 그리고 세부사항을 중심으로 관계형 데이터베이스의 활용을 다시 생각해볼게요
관계형 데이터베이스에서 외래키로 표현되는 의존 관계는 각 데이터베이스 수준에서 엔티티간 결합이 발생한다는 것을 의미합니다.
이 때문에 아키텍처 관점에서 데이터베이스를 사용한다는 것 자체와 엔티티를 기준으로 분리될 수 있는 컴포넌트의 결합이 문제가 될 수 있습니다.
고전적인 처리 방식
일단 ORM을 활용하지 않는 RDB를 사용하던 방식을 확인해보면 도움이 될 것 같아요
이전에는 물리적인 제한으로 인해 발생하는 지연(네트워크 오버헤드 등)과 고전적인 SSR 같은 이유로 페이지나 API 엔드포인트 별로 하나의 큰 쿼리(한방 쿼리 라고도 한다고 하네요)를 사용하는 것이 정석이었습니다.
게시글, 댓글을 예시로 확인해볼까요?
erDiagram
User {
int user_id PK
string user_name
}
Post {
int post_id PK
int user_id FK
string post_title
string post_content
}
Reply {
int reply_id PK
int user_id FK
int post_id FK
string reply_content
}
User ||--o{ Post : ""
User ||--o{ Reply : ""
Post ||--o{ Reply : ""
위 테이블 구조에서 고전적인 SSR을 이용하여 게시글 상세 정보를 보여주는 페이지를 렌더링해야 한다고 가정해보겠습니다.
- 게시글 정보
- 게시글 작성자 정보
- 댓글 정보
- 댓글 작성자 정보
- 게시글에 달린 댓글 수
- 댓글 페이지네이션
| |
아마 위와 같은 쿼리로 모든 데이터를 조회한 후 서비스 로직에서의 처리를 통해 HTML을 그려줬을거에요
만약 쿼리를 나누고 싶다던가, Ajax로 댓글 정보만 별도로 불러온다면 reply 테이블에 대한 조회를 분리할 수 있을겁니다. 아래처럼요!
| |
| |
위 예시는 간단한 편 이지만, 실제 운영되는 서비스는 복잡하고 연관된 데이터가 훨씬 많기 때문에 많은 수의 테이블을 JOIN 해야할 수 있습니다.
이처럼 이전에는 서버와 데이터베이스간 통신 오버헤드, 서버의 응답 처리 방식, 분산 처리의 여러움(하드웨어 비용, 기술 부재) 등으로 인해 쿼리를 작게 나눠 조회하는 것 보다 한번에 조회하는 방식이 성능을 위해 더 좋은 방식으로 여겨졌습니다.
한번에 조회해야 할 단위가 클라이언트에게 응답해야 할 데이터 전체이므로, 쿼리 자체도 제공해야할 뷰나 API 응답 결과에 종속적이 된다는 문제도 있었어요
위와 같은 고전적인 방식을 활용할 때, 테이블에 저장되는 데이터가 너무 커져서 데이터베이스를 분리하고 싶다던가, NoSQL로 마이그레이션 하고 싶다던가, MSA로 변경하여 각각을 독립적으로 운영해야한다면 어떤 문제가 있을까요?
매우 귀찮고 복잡한 일 이므로, 서비스의 규모가 크다면 작업을 시작하기도 어려울겁니다🥲
처리 방식의 변화
시간이 흐르면서 하드웨어, 소프트웨어의 발전과 비용 감소 등 여러 이유로 수평 확장이 쉬워지게 되었어요
필요에 따라 서버를 많이 배포하는 것이 어려운 일이 아니게되었고, 데이터베이스도 많은 수의 Read Replica를 확보해서 조회 요청에 대한 트래픽에 비교적 쉽게 대응할 수 있게 되었습니다.
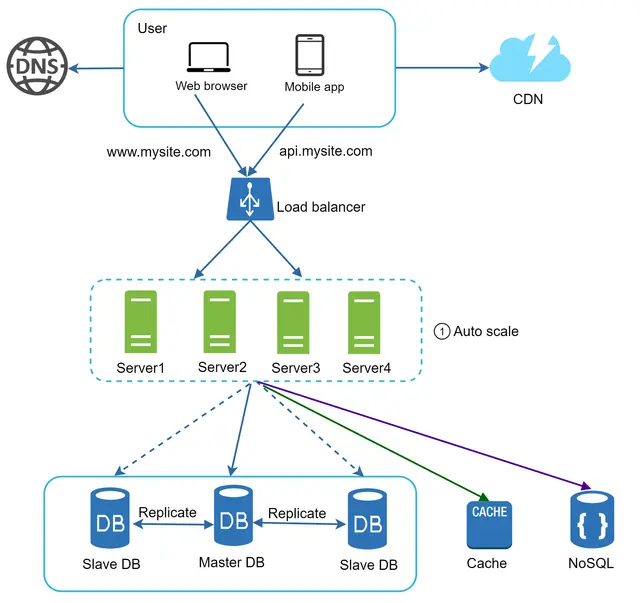
이러한 이유로 위에서 살짝 보여드린 것 처럼 커다란 쿼리를 작게 나누는 것이 성능 향상에 더 유리하다고 여겨지게 되었어요 쿼리 튜닝도 훨씬 쉬워집니다
이전과 달리 다뤄야하는 데이터의 범위와 크기도 작아졌기 때문에 객체지향적으로 데이터를 관리하는 것이 비교적 용이해졌고, 비즈니스 요구사항들을 처리하기 위해 엔티티 중심으로 설계하는 것이 적극적으로 고려되었습니다.

소프트웨어 아키텍처에서 엔티티(Entity)는 도메인 모델의 핵심 구성 요소로, 시스템이 다루는 중요한 개체 혹은 개념이에요
조금 더 설명하면 시스템의 도메인에서 고유한 속성과 행동을 가진 데이터 단위로서, 시스템의 주체가되고 주요 비즈니스 로직의 기본 단위입니다.
앞에서 언급했던 아키텍처 관점의 컴포넌트의 단위가 될 수도 있습니다.
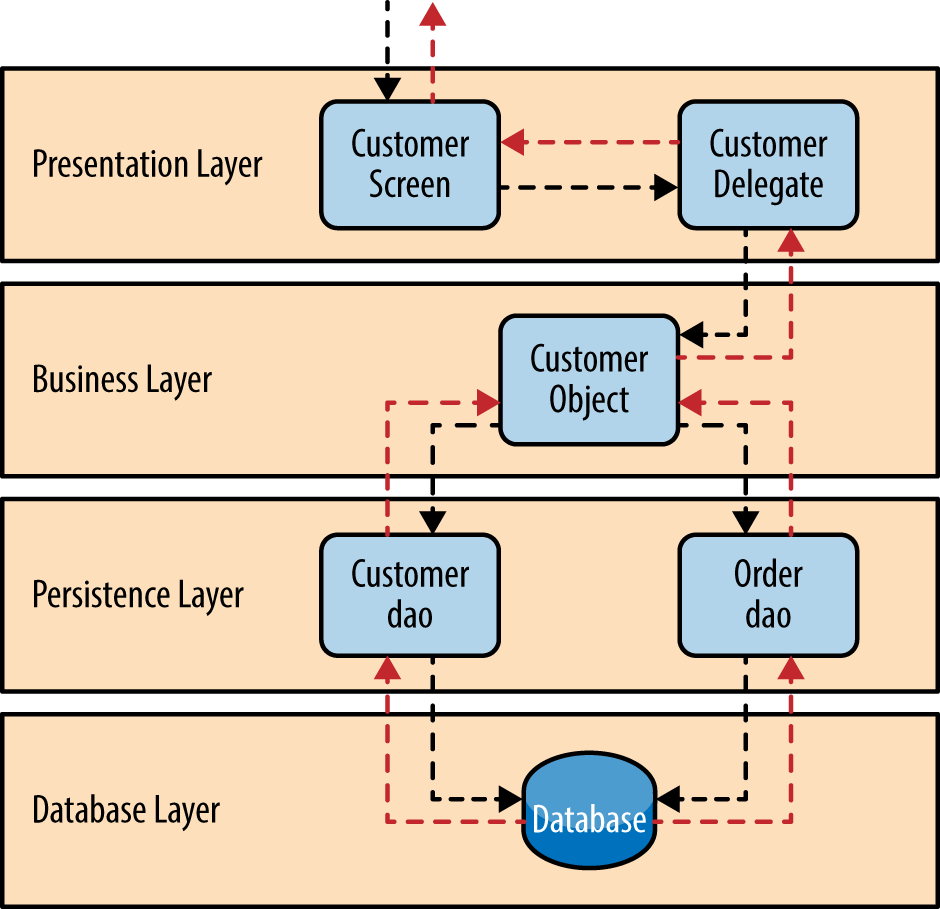
위 그림은 레이어드 아키텍처의 데이터 흐름을 표현한 것 인데, Business Layer에서 특정 비즈니스 로직을 처리하기 위한 주요 속성을 묶은 단위(객체 등)를 엔티티라고 표현할 수 있어요
ORM과 아키텍처의 관계
여기까지 쓰고나니 조금 돌아온 기분이 드는군요🤣 그래서 ORM과 아키텍처가 무슨 관계냐?!
위에서 언급했던 내용을 다시 살펴보면 ORM은 RDB의 데이터를 조회하여 엔티티 객체로 만들어주는 역할을 수행하게 되어요
이 때문에 ORM을 사용하기 위해 엔티티를 분리해야하고, 이는 관심사에 대한 수직 분해가 되었다는 의미이기도 합니다.
또한 관계형 데이터베이스를 사용한다는 사실은 변하지 않았지만 설정 값으로 특정 데이터베이스를 선택할 수 있는 기능을 제공하므로 어느정도 수평 분해를 위한 추상화가 되었다고 볼 수 있어요
여기해 더해 레이어드 아키텍처의 예시에서 Persistence Layer 역할을 하는 계층을 분리했다면, 인터페이스 등을 통해 의존성 역전을 활용하여 완전히 다른 유형의 데이터베이스(또는 API 응답)에 대해 거의 완전하게 관심사 분리가 가능해집니다.
연관 관계 분리
연관 관계가 있는 테이블들도 마찬가지로 ORM을 사용하여 관계를 관리해주기 위해 별도 엔티티로 분리해줘야합니다.
그렇기 때문에 자연스럽게 비즈니스 로직에서의 결합이 낮아지게 되어요
따라서 완전히 다른 데이터 주체로 변경된다고 하더라도 연관 관계에 있는 엔티티에 변경 내역이 비교적 적어질 것을 기대할 수 있습니다.
결론
그래서 제가 하고싶었던 말을 정리해보면 아래와 같습니다.
- ORM을 사용하기 위해서는 비즈니스의 주요 관심사인 엔티티에 대한 분리가 전제되어야한다.
- 데이터를 조회 계층 분리를 통해 추상화를 쉽게 적용할 수 있고, 이를 통해 조회 주체에 대한 의존성이 없어진다.
- 그러한 이유로 독립적으로 배포 가능한 단위인 아키텍처 관점의 컴포넌트로 분리된다.
- ORM 방식도 여러 문제가 있지만 아키텍처 관점에서 장점이 있기 때문에 계속해서 활용되고 있는 것 같다.
사실 ORM을 사용해서라기보다는 “좋은 아키텍처를 만들기 위해 개별 배포 가능한 컴포넌트로 관심사를 분리가 필요한데, ORM이 이러한 방향을 추구하고 있고, 어느정도 강제하고 있기 때문에 자연스럽게 좋은 아키텍처를 만든다.” 가 이 글의 결론이겠네요
추가로 “ORM 라이브러리는 이러한 아키텍처를 지원하기 위해 사용되는 도구일 뿐이다.”, “ORM을 사용하지 않더라도(직접 구현하더라도) 관심사를 잘 분리할 수 있는 구조를 만들어야 한다.” 라는 걸 말씀 드리고 싶었습니다.
다 쓰고 보니 정말 많이 돌아왔네요… 쓴게 아까워서 지우진 않겠습니다🤣
끝까지 읽어주셔서 감사합니다.