
좋은 아키텍처를 만드는 일은 객체 지향 설계 원칙을 이해하고 응용하는 데서 출발한다.
Object Oriented란 무엇인가?
- 데이터와 함수의 조합
- 대체로 이런 방식으로 많이 설명되지만 만족스러운 대답은 아니다.
o.f()가f(o)와 다르다는 의미를 내포한다.
- 실제 세계를 모델링하는 새로운 방법
- 얼버무리는 수준에 지나지 않는다. 의도가 불분명하며, 정의가 너무 모호하다.
- 캡슐화, 상속, 다형성
- 세가지 개념을 적절하게 조합한 것
캡슐화(Encapsulation)?
OO를 정의하는 요소 중 하나로 캡슐화를 언급하는 이유는 데이터와 함수를 쉽고 효과적으로 캡슐화하는 방법을 OO 언어가 제공하기 때문이다.
이를 통해 데이터와 함수가 응집력 있게 구성된 집단을 서로 구분할 수 있다.
private,public
하지만 이러한 개념은 OO에만 국한된 것은 아니다.
point.h
| |
point.c
| |
위 예시에서 point.h를 사용하는 측에서 struct Point의 멤버에 접근할 방법이 전혀 없다.
- 사용자는
makePoint()함수와distance()함수를 호출할 수는 있지만,Point구조체의 데이터 구조와 함수가 어떻게 구현되었는지에 대해서는 조금도 알지 못한다.
이것이 완벽한 캡슐화이며, OO가 아닌 언어에서도 충분히 가능하다.
오히려 OO를 지원하는 언어들이 캡슐화를 훼손하고 있는 경우가 많아 언어에 public, private, protected 키워드를 도입하여 불완전한 캡슐화를 보완한다.
- C++는 컴파일러가 클래스의 인스턴스 크기를 알아야하는 기술적인 이유로 클래스의 멤버변수를 해당 클래스의 헤더파일에 선언해야하고, 이로인해 사용측에서 멤버변수의 존재를 알게된다.
- 자바, C#은 헤더와 구현체를 분리하는 방식을 버렸다. 이로인해 클래스 선언과 정의를 구분하는게 불가능하다.
이 때문에 OO가 강력한 캡슐화에 의존한다는 정의는 받아들이기 힘들며, 대부분의 OO를 제공하는 언어들이 실제로는 C언어에서 누렸던 완벽한 캡슐화를 약화시켰다.
- 많은 언어가 캡슐화를 거의 강제하지 않는다.
- OO 프로그래밍은 프로그래머가 캡슐화를 우회하지 않을 것 이라는 믿음을 기반으로 한다.
상속?
OO 언어가 더 나은 캡슐화를 제공하지는 못했지만, 상속만큼은 확실히 제공했다.
하지만 상속이란 단순히 어떤 변수와 함수를 하나의 유효 범위로 묶어 재정의하는 일에 불과하다.
namedPoint.h
| |
namedPoint.c
| |
main.c
| |
main 프로그램을 살펴보면 NamedPoint 데이터 구조가 Point 데이터 구조로부터 파생된 구조인 것 처럼 동작한다는 사실을 볼 수 있다.
이처럼 눈속임처럼 보이는 방식은 OO가 출현하기 이전부터 프로그래머가 흔히 사용했던 기법이다. 실제로 C++은 이 방법을 이용해 단일 상속을 구현하였다.
OO 언어가 고안되기 훨씬 이전에도 상속과 비슷한 기법이 사용되었지만, 상속만큼 편리한 방식은 절대 아니다.
따라서 OO 언어가 완전히 새로운 개념을 만들지는 못했지만, 상당히 편리한 방식으로 제공했다고 볼 수 있다.
다형성?
OO 언어가 있기 이전에도 다형성을 표현할 수 있었다.
| |
getchar()는 STDIN에서 문자를 읽고, putchar()는 STDOUT으로 문자를 쓴다.
STDIN과 STDOUT은 다양한 장치가 될 수 있기 때문에 이러한 함수는 다형적(Polymorphic)이다.
유닉스 운영체제의 경우 모든 입출력 장치 드라이버가 다섯 가지 표준 함수를 제공할 것을 요구한다
open,close,read,write,seek
FILE 데이터 구조는 이들 다섯 함수를 가리키는 포인터들을 포함한다.
| |
입출력 드라이버에서는 이들 함수를 아래와 같이 전의하며, FILE 데이터 구조를 함수에 대한 주소와 함께 로드한다.
| |
STDIN을 FILE*로 선언하면 콘솔 데이터 구조를 가리키므로, getchar()는 아래와 같은 방식으로 구현할 수 있다.
| |
다시말해 getchar()는 STDIN으로 참초되는 FILE 데이터 구조의 read 포인터가 가르키는 함수를 단순히 호출할 뿐이다.
이처럼 단순한 기법이 모든 OO가 지는 다형성이 근간이 되며, 즉 함수를 가리키는 포인터를 응용한 것이 다형성이고 OO가 새롭게 만든 개념이 아니다.
하지만, OO 언어는 좀 더 안전하고 편리하게 사용할 수 있게 해준다.
- 함수 포인터를 사용하기 위한 관례들을 없애 실수할 위험이 없다.
OO는 제어흐름을 간접적으로 전환하는 규칙을 부과한다고 결론 지을 수 있다. (??)
다형성이 가진 힘
복사 프로그램 예제에서 새로운 입출력 장치가 생겨도 프로그램의 아무런 변경이 필요하지 않다.
- 복사 프로그램의 소스 코드는 입출력 드라이버의 소스 코드에 의존하지 않기 때문이다.
- 입출력 드라이버가
FILE에 정의된 다섯가지 표준 함수를 구현한다면, 복사 프로그램에서는 어떠한 입출력 드라이버도 사용할 수 있다.
플러그인 아키텍처(Plugin architecture)
플러그인 아키텍처는 이처럼 입출력 장치 독립성을 지원하기 위해 만들어졌고, 등장 이후 거의 모든 운영체제에서 구현되었다.
그런데도 대다수의 프로그래머는 함수 포인터의 위험함 때문에 이러한 개념을 확장하여 적용하지 않았는데, OO의 등장으로 언제 어디서든 플러그인 아키텍처를 적용할 수 있게 되었다.
의존성 역전
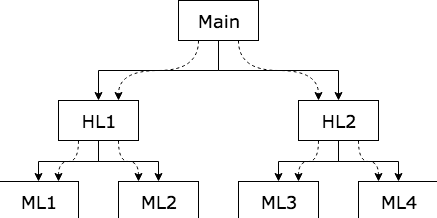
다형성을 안전하고 편리하게 적용할 수 있기 전에는 main 함수가 고수준 함수를 호출하고, 고수준 함수는 다시 중간 수준 함수를, 중간 수준 함수는 저수준 함수를 호출한다.
이로인해 소스 코드 의존성의 방향은 반드시 제어흐름을 따르게 된다.
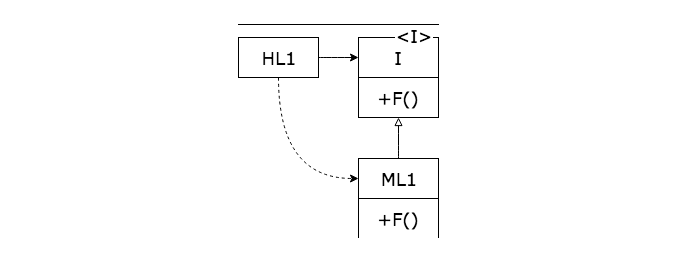
하지만 다형성을 활용하면 의존성의 방향이 바뀐다.
HL1 모듈은 ML1 모듈의 F() 함수를 호출한다. 하지만 ML1과 I 인터페이스 사이의 소스 코드 의존성(상속 관계)이 제어흐름과는 반대이다.
이는 의존성 역전(Dependency inversion)이라고 부르며, 소프트웨어 아키텍처 관점에서 이러한 현상은 소스 코드 의존성을 어디에서든 역전시킬 수 있다는 뜻이기도 하다.
이러한 접근법을 사용한다면, OO 언어로 개발된 시스템을 다루는 소프트웨어 아키텍트는 시스템의 소스 코드 의존성 전부에 대한 방향을 결정할 수 있는 절대적인 권한을 가지게 된다.
- 소스 코드 의존성이 제어흐름의 방향과 일치되도록 제한되지 않는다.
- 호출하는 모듈이든 호출 받는 모듈이든 관계없이 소스 코드 의존성을 원하는 방향으로 설정할 수 있다.
flowchart LR
a[UI]
b[Business Rules]
c[Database]
a-->b
b-.->a
c-->b
b-.->c
위 와 같은 경우 업무 규칙이 데이터베이스와 UI에 의존하는 대신에, 시스템의 소스코드 의존성을 반대로 배치하여 데이터베이스와 UI가 업무 규칙에 의존하게 만들 수 있다.
- UI와 데이터베이스가 업무 규칙의 플러그인이 된다는 뜻이다.
- 업무 규칙의 소스 코드에서는 UI나 데이터베이스를 호출하지 않는다.
결과적으로 업무 규칙, UI, 데이터베이스는 세 가지로 분리된 컴포넌트 또는 배포 가능한 단위로 컴파일할 수 있고, 의존하지 않기 때문에 각 컴포넌트들을 독립적으로 배포할 수 있다.
- 특정 컴포넌트의 소스 코드가 변경되면, 해당 코드가 포함된 컴포넌트만 다시 배포한다.
- 이를 배포 독립성(Independent deployability)이라고 한다.
- 시스템의 모듈을 독립적으로 배포할 수 있게 되면, 다른 팀에서 각 모듈을 독립적으로 개발할 수 있고, 이것을 개발 독립성 이라 한다.
결론
소프트웨어 아키텍트 관점에서 OO란 다형성을 이용하여 전체 시스템의 모든 소스코드 의존성에 대한 절대적인 제어 권한을 획득할 수 있는 능력이다.
OO를 사용하면 아키텍트는 플러그인 아키텍처를 구성할 수 있고, 이를 통해 고수준의 전책을 포함하는 모듈은 저수순의 세부사항을 포함하는 모듈에 대해 독립성을 보장할 수 있다.
저수준의 세부사항은 중요도가 낮은 플러그인 모듈로 만들 수 있고, 고수준의 정책을 포함하는 모듈과는 독립적으로 개발하고 배포할 수 있다.